S-au schimbat multe în ceea ce privește arhitectură of NVIDIA GPU-urile din ultimele două decenii, dar un moment de cotitură important a fost atunci când cei din verde au lansat arhitectura Tesla, în 2006. În acest articol vom arunca o privire Înapoi pentru a vedea cum a evoluat arhitectura NVIDIA de la Tesla la Turing , arhitectura actuală (în absența sosirii lui Ampere) și, mai precis, cum este SM (Streco Multiprocessors) au făcut-o.
În acest articol vom analiza modul în care arhitectura NVIDIA a evoluat de la Tesla la Turing, deci este un moment bun pentru a intra în fundal și pentru a vedea ce a fost deosebit în legătură cu fiecare dintre aceste arhitecturi, pe care le puteți găsi rezumate în tabelul următor. .

| An | Arhitectură | Serie | . | Proces litografic | Graficul cel mai reprezentativ |
|---|---|---|---|---|---|
| 2006 | Tesla | GeForce 8 | G80 | 90nm | 8800 GTX |
| 2010 | Fermi | GeForce 400 | GF100 | 40nm | GTX 480 |
| 2012 | Kepler | GeForce 600 | GK104 | 28 nm | GTX 680 |
| 2014 | Maxwell | GeForce 900 | GM204 | 28 nm | GTX 980 Ti |
| 2016 | Pascal | GeForce 10 | GP102 | 16nm | GTX 1080 Ti |
| 2018 | Turing | GeForce 20 | TU102 | 12nm | RTX 2080 Ti |
Stalemate: epoca pre-NVIDIA Tesla
Până la sosirea Tesla în 2006, NVIDIA GPU proiectarea a fost corelată cu stările logice ale API-ului său de redare. GeForce 7900 GTX , alimentat cu matriță G71, a fost fabricat în trei secțiuni (una dedicată prelucrării vertexului (8 unități), alta pentru a genera fragmente (24 unități) și alta pentru a uni aceste (16 unități)).
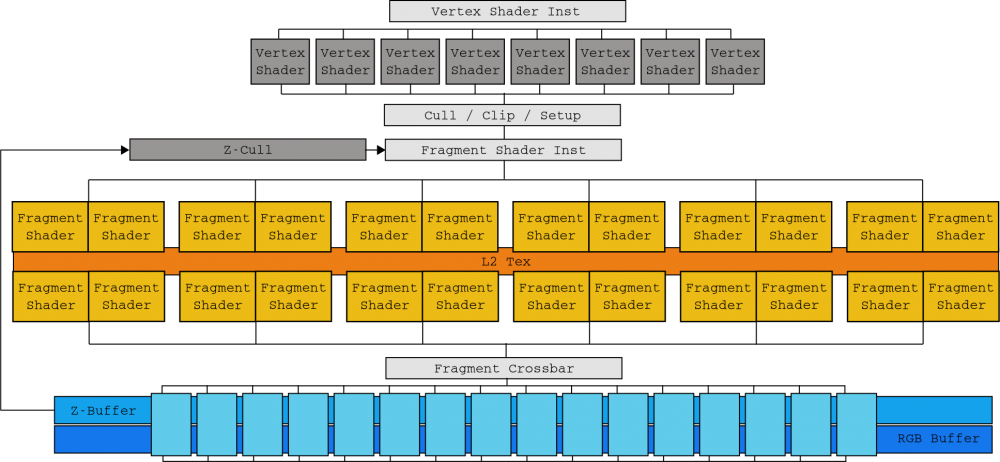
Această corelație i-a obligat pe proiectanți și ingineri să fie nevoiți să-și imagineze locația blocajelor pentru a echilibra fiecare strat corespunzător. La aceasta s-a adăugat sosirea DirectX 10 cu umbrire geometrică, astfel inginerii NVIDIA s-au găsit între o piatră și un loc greu pentru a echilibra matrița fără să știe când și în ce fel următorul stadiu al API-urilor grafice.
Era timpul să schimbăm modul în care îți proiectezi arhitectura .
Arhitectura Tesla NVIDIA
NVIDIA a rezolvat problema creșterii complexității cu arhitectura Tesla, prima „unificată”, în 2006. Cu ajutorul acesteia mor G80 acolo nu mai face nicio distincție între straturi. Multiprocesoare în flux (SM) au înlocuit toate unitățile anterioare datorită abilității lor de a executa procesarea vertexului, generarea fragmentelor și unirea fragmentelor fără distincție într-un singur nucleu. Astfel, în plus, sarcina este echilibrată automat prin schimbul de „nuclee” executate de fiecare SM în funcție de nevoile fiecărui moment.
Astfel, Shader Units sunt acum „nucleele” (nu mai sunt compatibile cu SIMD) care sunt capabile să gestioneze singuri o instrucțiune integrală sau o instrucțiune float32 (SM-urile primesc fire în grupuri de 32 numite warps). În mod ideal, toate firele dintr-un warp vor executa aceeași afirmație în același timp numai cu date diferite (de aici și numele SIMT). Unitatea de instrucțiune cu mai multe filete (MT) este responsabilă pentru activarea și dezactivarea firelor de pe fiecare urzire în cazul în care indicatorii de instrucțiune (IP) converg sau diferă.
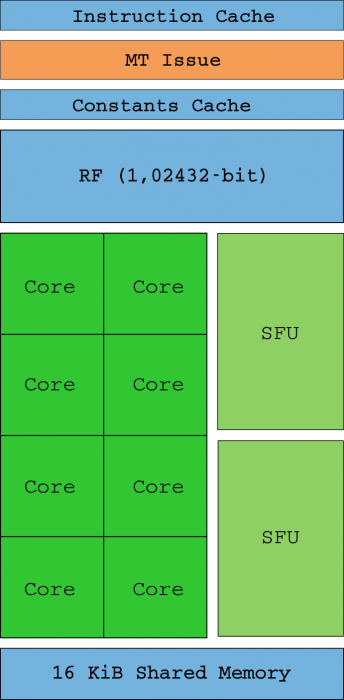
Doi SFU unitățile (le puteți vedea în diagrama de mai sus) sunt însărcinate să vă ajute cu calcule matematice complexe, cum ar fi rădăcinile pătrate inverse, sinele, cosinusul, exp și rcp. Aceste unități sunt, de asemenea, capabile să execute o instrucțiune pentru fiecare ciclu de ceas, dar, deoarece există doar două, viteza de execuție este împărțită la patru pentru fiecare dintre ele (adică există un SFU pentru fiecare patru nuclee). Nu există suport hardware pentru calculele float64, iar acestea se realizează prin software, reducând semnificativ performanța.
Un SM funcționează la potențialul său maxim atunci când latența de memorie poate fi eliminată, având întotdeauna urzări programabile în coada de execuție, dar și atunci când firul unei urzeale nu are divergențe (pentru asta este fluxul de control, care le menține mereu în aceeași calea instrucțiunilor). Fișierul jurnal ( 4KB RF ) este locul în care stările de fir sunt stocate, iar firele care consumă prea multă coadă de execuție reduc câte dintre ele pot fi păstrate în acel jurnal, reducând și performanța.
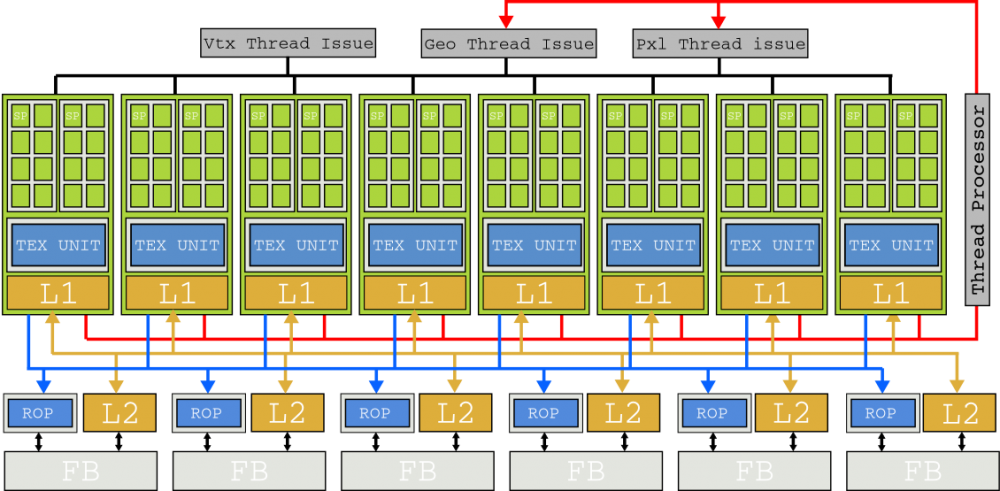
Matrița „flagship” a acestei arhitecturi NVIDIA Tesla a fost G90 bazată pe un proces litografic de 90 nanometri, prezentat cu celebrul GeForce 8800 GTX. Două SM-uri sunt grupate într-un cluster de procesor de textură (TPC) împreună cu o unitate de textură și cache Tex L1. Cu 8 TPC-uri, G80 avea 128 de nuclee care generează 345.6 GFLOP-uri de putere brută. GeForce 8800 GTX a fost extrem de popular în acele zile.
Odată cu arhitectura Tesla, NVIDIA a introdus, de asemenea, limbajul de programare CUDA (Compute Unified Devide Architecture) în C, un superset de C99, care a fost o ușurare binevenită pentru pasionații de GPGPU, care au salutat o alternativă pentru a înșela GPU-ul cu umbrele și texturile GLSL.
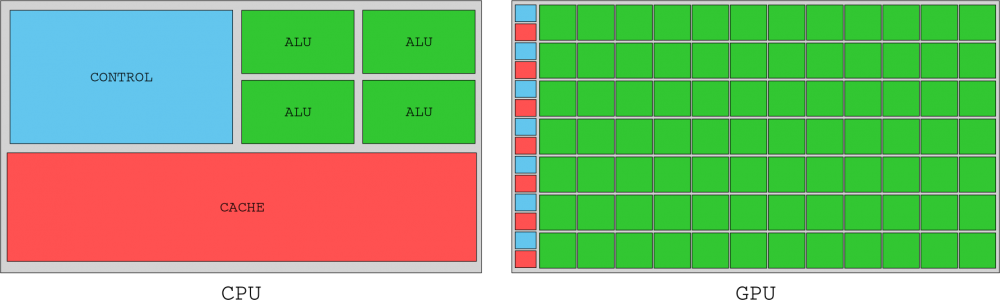
Deși această secțiune s-a concentrat pe SM, acestea erau doar jumătate din sistem. IM-urile trebuie să fie alimentate cu instrucțiuni și date cu rezidență în memoria grafică a GPU, astfel încât pentru a evita stagnarea, GPU-urile nu evită „deplasările” de memorie cu o mulțime de memorie cache, cum ar fi procesoarele (CPU), ci, mai degrabă, ele aglomerează memoria. autobuz pentru cereri de I / O din miile de fire pe care le gestionează. Pentru aceasta, performanța de memorie ridicată a fost implementată în cipul G80 prin șase canale de memorie DRAM bidirecționale.
Arhitectura Fermi
Tesla a fost o mișcare foarte riscantă, dar care s-a dovedit a fi foarte bună și a avut un succes atât de mare încât a devenit temelia arhitecturilor NVIDIA pentru următoarele două decenii. În 2010, NVIDIA a lansat programul GF100 mor pe baza noului Fermi arhitectură, cu numeroase caracteristici noi în interior.
Modelul de execuție se învârte în continuare în jurul deformărilor de 32 de fire programate într-un SM și a fost doar datorită lui 40 litri litri (față de 90 de metri ai lui Tesla), NVIDIA a coplat aproape totul. Un SM poate programa acum două media-warps (16 fire) simultan datorită două seturi de 16 nuclee CUDA. Cu fiecare nucleu care execută o instrucțiune pe ciclu de ceas, un singur SM a fost capabil să execute o instrucțiune de urzeală pe ciclu (și aceasta este de 4 ori mai mare decât capacitatea SM Tesla).

Numărul SFU a fost, de asemenea, consolidat, deși mai puțin pentru că „doar” a înmulțit cu două, în total cu patru unități. Suport hardware a fost adăugat, de asemenea, pentru calcule float64, de care Tesla nu avea, efectuate de două nuclee combinate CUDA. GF100 ar putea face o înmulțire integrală într-un ciclu de ceas unic datorită unui ALU pe 32 de biți (față de 24 de biți în Tesla) și are o precizie mai mare float32.
Din perspectivă de programare, sistemul de memorie unificat al lui Fermi a permis CUDA C să fie mărită cu caracteristici C ++ precum obiecte și metode virtuale.
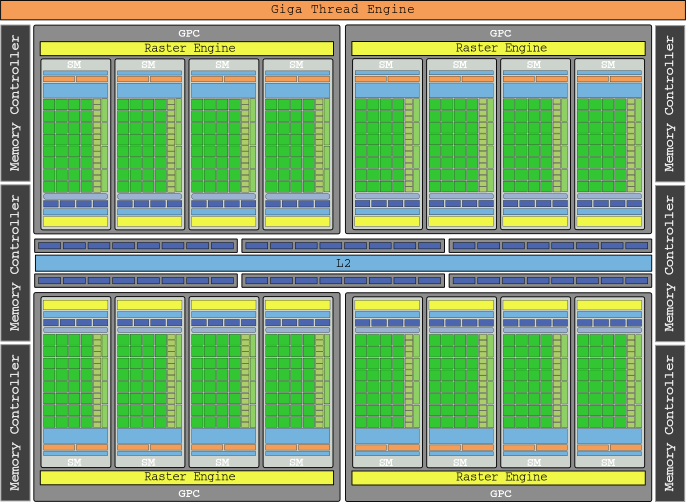
Cu unități de texturi acum parte a SM-urilor, conceptul de TPC a dispărut, înlocuit de clustere de procesoare grafice (GPC) care au patru SM-uri. Nu în ultimul rând, un motor „Polimorf” a fost adăugat pentru a gestiona vertexurile obiectului, transformarea vizualizării și tesselarea. Steagul grafic al acestei generații a fost GTX 480, care cu 512 nuclee sale avea 1,345 GFLOP de putere brută.
Arhitectura NVIDIA Kepler
În 2012 a venit arhitectura NVIDIA Kepler, cu care eficiența energetică a matriței sale a fost îmbunătățită drastic prin scăderea vitezei ceasului și unificarea ceasului central cu cel al cardului (obișnuiau să aibă o frecvență de două ori), rezolvând astfel problema Generația anterioară GTX 480 (au devenit foarte calde și au un consum foarte mare).
Aceste schimbări ar fi trebuit să conducă la performanțe mai scăzute, dar datorită implementării procesului litografic de 28 nm și eliminării programatorului hardware în favoarea unuia software, NVIDIA a fost capabil să adauge nu doar mai multe SM, ci și să îmbunătățească designul. .

„Multiprocesorul de streaming de nouă generație”, cunoscut sub numele de SMX, s-a dovedit a fi un monstru în care aproape totul s-a dublat sau chiar s-a triplat. Cu patru programatori de urzeală capabili să proceseze o întreagă urzeală într-un ciclu de ceas (în comparație cu designul cu două jumătăți al lui Fermi), SMX conține acum 196 de nuclee. Fiecare programator are o dublă expediere pentru a executa oa doua instrucțiune într-o urzeală dacă este independent de instrucțiunea executată în prezent, deși această dublă programare nu a fost întotdeauna posibilă.
Această abordare a complicat logica de programare, dar cu până la șase instrucțiuni de deformare pe ceas, un SMX Kepler oferă de două ori performanța unui Fermi SM.
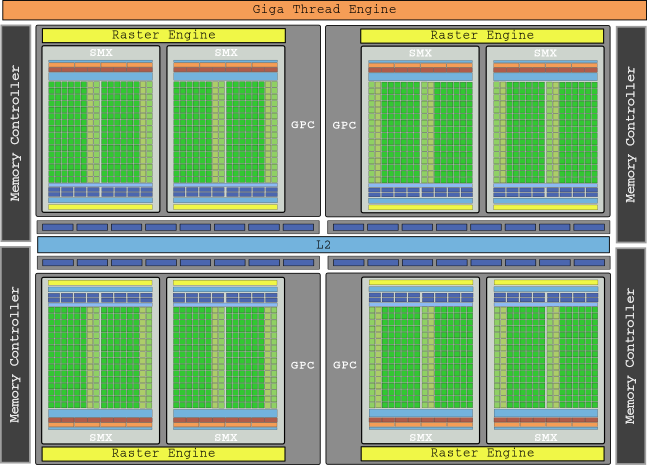
Grafica emblematică a acestei generații a fost GeForce GTX 680 cu GK104 și 8 SMX, care conține o cantitate incredibilă de 1536 de nuclee și a furnizat un număr de până la 3,250 GFLOP de putere brută.
Arhitectura NVIDIA Maxwell
În 2014 a venit arhitectura NVIDIA Maxwell, GPU-urile sale din a 10-a generație. După cum au explicat în documentația lor tehnică, inima acestor GPU a fost „eficiența energetică extremă și performanțe excepționale pe watt consumate” și aceasta este că NVIDIA a orientat această generație către sisteme cu putere limitată, cum ar fi mini PC-uri și laptopuri.
Principala decizie a fost să renunț la abordarea lui Kepler la SMX și să revină la filozofia lui Fermi de a lucra cu media warps. Astfel, pentru prima dată în istoria sa, SMM prezintă mai puține nuclee decât predecesorul său, cu „doar” 128 de nuclee. Având numărul de miezuri ajustat la dimensiunea urzeii, a îmbunătățit structura matriței, ceea ce a dus la o mare economie de spațiu ocupat și energie consumată.
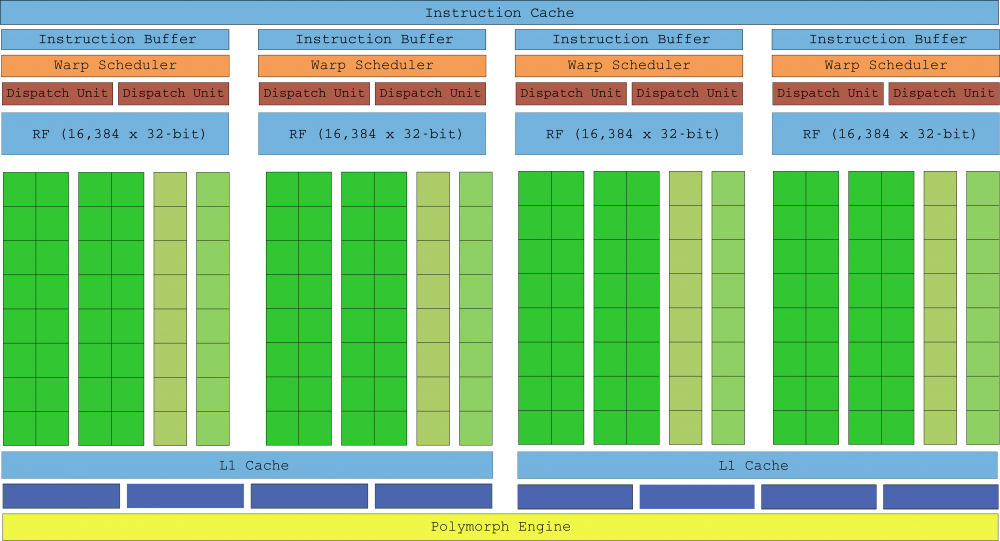
A doua generație de Maxwell a îmbunătățit semnificativ performanța, menținând în același timp eficiența energetică a primei generații. Cu procesul litografic încă stagnant la 28 nm, inginerii NVIDIA nu s-au putut baza pe miniaturizarea tranzistoarelor pentru a îmbunătăți performanța, totuși mai puține nuclee per SMM și-au redus dimensiunea, permițându-le să se potrivească mai multor SMM-uri. in aceeasi zi. Maxwell Gen 2 conține de două ori mai mult SMM ca Kepler, cu doar 25% mai mult în suprafață.
În lista de îmbunătățiri ar trebui să menționăm, de asemenea, o logică de planificare mai simplificată, care a redus recalcularea redundantă a deciziilor de planificare, ceea ce a redus latența calculului pentru a asigura o mai bună ocupare. Ceasul de memorie a fost, de asemenea, crescut cu 15% în medie.
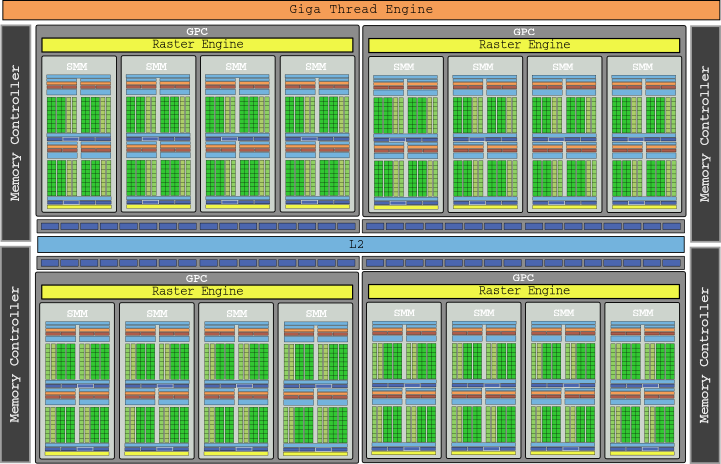
Diagrama cipului GM200 pe care o vedem mai sus începe aproape să doară ochiul, nu? Matrița care a încorporat GTX 980 Ti, cu 3072 de nuclee în 24 SMM și care a furnizat o putere brută de 6,060 GLOP.
Arhitectura NVIDIA Pascal
În 2016 a sosit următoarea generație, NVIDIA Pascal, iar documentația tehnică arăta aproape ca o copie în carbon a SMM-urilor lui Maxwell. Dar doar pentru că nu există modificări ale SM-urilor nu înseamnă că nu au existat îmbunătățiri și, de fapt, procesul de 16 nm utilizat în aceste cipuri a îmbunătățit substanțial performanțele prin faptul că a putut pune mai multe SM pe același cip.
Alte îmbunătățiri importante de evidențiat au fost sistemul de memorie GDDR5X, o noutate care a furnizat viteze de transfer de până la 10 Gbps datorită opt controlere de memorie, interfața sa de 256 biți oferind o lățime de bandă cu 43% mai mare decât generația anterioară.
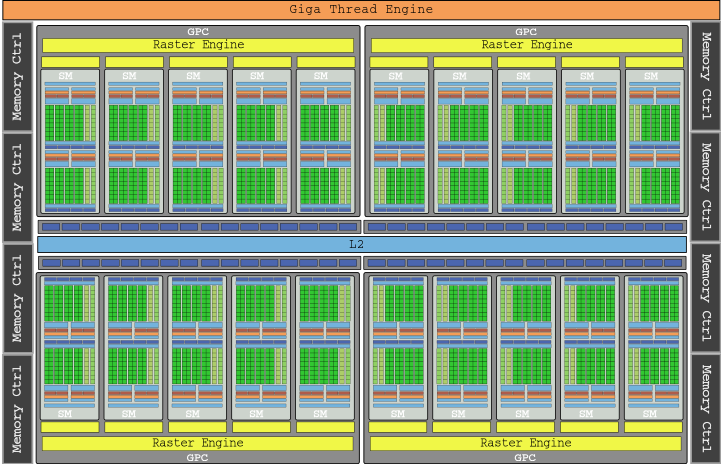
Steagul grafic al generației Pascal a fost GTX 1080 Ti, cu modelul GP102 pe care îl puteți vedea în imaginea de mai sus și cele 28 SM ale sale, ambalând un număr total de 3584 de nuclee pentru o putere brută de 11,340 GLOP (suntem deja la 11.3 TFLOPs ).
NVIDIA Turing Architecture
Lansat în 2018, Turing Architecture a fost „cel mai mare salt arhitectural în mai mult de un deceniu” (în cuvintele NVIDIA). Nu numai că s-au adăugat SM Turing, dar a fost introdus pentru prima dată hardware dedicat Ray Tracing, cu nuclee Tensor Cores și RayTracing. Acest design presupune că matrița a fost „fragmentată” din nou, în stilul straturilor din epoca dinainte de Tesla despre care v-am spus la început.
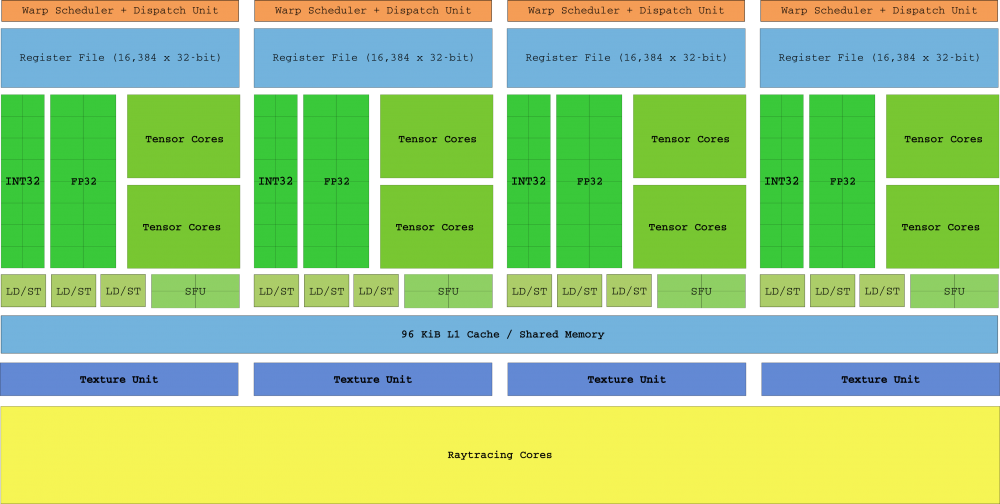
În plus față de noile nuclee, Turing a adăugat trei caracteristici principale: În primul rând, nucleul CUDA este acum scalabil și capabil să execute atât instrucțiuni întregi cât și în virgulă mobilă în paralel (acest lucru le va aminti multor „revoluționari” Intel Arhitectura Pentium acolo. anul 1996). În al doilea rând, noul sistem de memorie GDDR6 susținut de 16 controlere, care pot ajunge acum la 14 Gbps și, în cele din urmă, firele care nu mai împărtășesc indicatori de instrucțiuni în warpuri.
Datorită programării independente de thread introduse în Volta (pe care nu o includem aici, deoarece este o arhitectură orientată spre utilizator), fiecare thread are propriul IP și, în consecință, SM-urile sunt libere să programeze thread-uri într-o urzeală fără nevoia de așteptare ca ei să convergă cât mai curând.

Topul graficului de gamă al acestei generații este RTX 2080 Ti, cu matrița TU102 și 68 TSM conținând 4352 nuclee, cu o putere brută de 13.45 TFLOP. Nu îi punem diagrama completă ca în cele anterioare, deoarece pentru ca acesta să se potrivească pe ecran, ar trebui să fie micșorat atât de mult încât să fie o neclaritate.
Și ce urmează?
După cum știți bine, următoarea arhitectură NVIDIA se numește Ampere și, cu siguranță, va ajunge cu nodul de fabricație la 7 nm de TSMC. Vom actualiza acest articol imediat ce toate datele vor fi disponibile.