Când avem un server cu Linux sau un server NAS (care are și un sistem de operare bazat pe Linux) cu o mulțime de informații în interior, atât sistemul de operare în sine, cât și fișierele și folderele personale sau de lucru, este esențial să se controleze ca hard disk-urile și SSD Unitățile sunt în stare bună de sănătate și nu se vor rupe prea curând fără avertisment. Din acest motiv, este foarte important să monitorizăm continuu hard disk-ul sau SSD-ul serverului nostru, pentru a evita pierderea datelor din cauza spargerii acestuia. Astăzi, în acest articol, vă vom arăta tot ce ar trebui să verificați pe serverul dvs. Linux pentru a verifica starea discurilor dumneavoastră.

Care este SMART-ul discurilor
Toate hard disk-urile și unitățile SSD au o tehnologie numită SMART, sau cunoscută și ca SMART, care înseamnă „Self Monitoring Analysis and Reporting Technology”. Această tehnologie încorporată în firmware-ul hard disk-urilor și SSD-urilor constă în detectarea eventualelor defecțiuni ale hard disk-ului, cu scopul de a anticipa erorile fizice din hard disk sau defecțiunile neașteptate ale unităților SSD din cauza scrierii pe memoria flash internă. . Scopul SMART este de a alerta utilizatorii astfel încât să poată face copii de rezervă și înlocui unitatea fără pierderi de date. Dacă ignorăm SMART-ul, va veni un moment în care hard disk-ul se va rupe și vom pierde date, așa că este esențial să fim mereu atenți la datele SMART ale discurilor.
Pentru a utiliza SMART este absolut necesar ca BIOS-ul sau UEFI-ul serverului sa fie compatibil cu aceasta tehnologie si sa fie activat, in plus, este absolut necesar ca discurile sa o includa. Astăzi toate serverele, sistemele de operare și discurile folosesc această tehnologie pentru a detecta problemele de pe hard disk, am putea spune că este „universală” și că este întotdeauna folosită.
Această tehnologie este responsabilă de monitorizarea diferiților parametri ai hard disk-ului, cum ar fi viteza platourilor de disc, sectoarele defectuoase, erorile de calibrare, verificarea redundanței ciclice (erori tipice CRC), temperatura discului, viteza de citire a datelor, timpul de pornire (rotire). sus), contor de sectoare realocate, viteza de căutare (timp de căutare) și alți parametri foarte avansați care vă permit să știți ce este important: dacă hard disk-ul va eșua în curând.
Intern SMART are o gamă de valori pe care le putem considera „normale”, iar atunci când un parametru iese din aceste valori, adică atunci când alarma se stinge, BIOS-ul/UEFI îl va detecta și va anunța sistemul de operare că există o defecțiune in sistem. disc și asta poate fi grav. În sistemele de operare Linux avem posibilitatea de a efectua teste SMART pentru a verifica dacă discul funcționează corect, în plus, avem posibilitatea de a programa aceste teste pentru a minimiza impactul asupra performanței.
Cum să vizualizați starea de sănătate a discului
În majoritatea distribuțiilor bazate pe Linux avem un pachet numit smartmontools. Uneori, acest pachet este preinstalat în distribuția noastră, iar alteori trebuie să-l instalăm singuri. Acest pachet are două programe diferite:
- smartctl : este programul de linie de comandă care ne permite să verificăm hard disk-urile și SSD-urile la cerere, sau putem programa funcționarea acestuia prin cron-ul tipic din sistemul de operare.
- inteligent : este un demon sau un proces care verifică dacă hard disk-urile sau SSD-urile într-un interval specificat nu au avut nicio eroare. Este capabil să înregistreze orice tip de avertizare sau eroare de disc în syslog-ul principal al serverului, de asemenea, permite trimiterea acestor avertismente și erori prin e-mail către administrator pentru ca acesta să verifice că totul este corect.
Pachetul smartmontools este responsabil de monitorizarea hard disk-urilor și unităților SSD, indiferent dacă acestea folosesc interfețe SATA, SCSI, SAS sau NVME, acceptă orice tip de interfață de date. Desigur, acest program este complet gratuit.
Instalare
Instalarea acestui program, dacă nu este instalat implicit pe distribuția dvs. Linux, se face prin utilizarea managerului de pachete al distribuției dvs. De exemplu, pe sistemele de operare Debian cu apt ar fi după cum urmează:
sudo apt install smartmontools
În funcție de managerul de pachete al distribuției tale, va trebui să folosești o comandă sau alta, important este că acest pachet este disponibil pentru toate distribuțiile bazate pe Unix și, de asemenea, pentru Linux, așa că îl poți instala și pe FreeBSD fără probleme.
Folosind smartctl
Pentru a folosi acest program și a verifica starea de sănătate a hard disk-ului nostru, primul lucru pe care trebuie să-l facem este să știm câte hard disk-uri avem și care este calea pentru a examina acele hard disk-uri sau SSD-uri în cauză. Pentru a ști unde sunt discurile, trebuie să executăm următoarea comandă:
df -h
De asemenea, am putea folosi fdisk pentru a obține lista de discuri pe care le avem pe serverul nostru:
sudo fdisk -l
Aceste comenzi ne vor arăta o listă a unităților și, de asemenea, a partițiilor. Trebuie să folosim acest program la nivel de hard disk sau SSD, nu la nivel de partiție. În general, în sistemele Linux vom găsi discurile în calea /dev/sdX.
Odată ce știm ce unitate vom analiza pentru a-i verifica starea de sănătate prin SMART, trebuie să știm că există în total două teste diferite pe care le putem efectua:
- Test scurt – Acest test este folosit cel mai adesea pentru a detecta problemele de disc. La efectuarea acestui test, acesta ne va arăta cele mai importante erori și avertismente, fără a fi nevoie să analizăm în detaliu întregul disc. Putem programa acest scurt test prin cron să fie săptămânal, în acest fel, o dată pe săptămână va efectua această analiză și ne va anunța dacă a detectat erori. Este indicat să faceți acest test într-un moment în care este puțin sau deloc folositor, nu este recomandat să îl faceți în timpul orelor de lucru, mai bine în zori.
- Test lung – Acest test poate dura destul de mult, în funcție de unitate și de capacitatea acesteia. Efectuând acest test cuprinzător, ne va arăta toate avertismentele sau erorile pe care le găsește pe întregul disc. Putem programa acest test lung cu cron să fie făcut lunar, adică o dată pe lună vom efectua acest test pentru a verifica starea de sănătate a discului. Este recomandabil să faceți acest test într-un moment în care discul este puțin folosit, de exemplu, în zori, pentru că altfel performanța de citire și scriere, precum și latența de acces la date vor crește considerabil.
Odată ce cunoaștem cele două tipuri de teste pe care le putem folosi, primul lucru pe care trebuie să-l știm este dacă hard diskul sau SSD-ul are SMART activat:
sudo smartctl -i /dev/sda
În cazul în care discul acceptă SMART, dar nu este activat, îl putem activa executând următoarea comandă:
sudo smartctl -s on /dev/sda
Pentru a vedea toate atributele SMART ale producătorului discului în cauză, putem executa următoarea comandă:
sudo smartctl -a /dev/sda
Pentru a efectua un test scurt, executăm următoarele:
sudo smartctl -t short /dev/sda
Pentru a efectua un test lung, executăm următoarele:
sudo smartctl -t long /dev/sda
Odată ce am efectuat testul scurt sau lung, putem executa următoarea comandă pentru a vedea toate rezultatele:
sudo smartctl -H /dev/sda

Vă recomandăm să citiți paginile de manual ale smartctl unde veți găsi toate comenzile pe care le vom putea executa pentru a folosi posibilitățile SMART, totuși, comenzile principale sunt cele pe care vi le-am explicat.
La ce valori ar trebui să mă uit?
Când facem un test SMART, va apărea un număr mare de atribute ale hard diskului sau SSD-ului nostru. Unele dintre aceste valori sunt esențiale cărora le acordăm o atenție deosebită, deoarece ne pot oferi „indicii” că discul va eșua foarte curând:
- Reallocated_Sector_Ct: este numărul de sectoare care au fost realocate către alte zone ale discului deoarece au existat erori de citire. Această eroare este foarte tipică atunci când un disc este foarte vechi și se apropie de sfârșitul duratei de viață utilă.
- Spin_Retry_Count: este numărul de încercări care au fost necesare pentru a porni discul, aceasta indică faptul că există o problemă serioasă de hardware pe disc și s-ar putea să nu pornească data viitoare.
- Reallocated_Event_Count – Numărul de realocări care au fost efectuate, fie cu succes, fie fără succes. Cu cât numărul este mai mare, cu atât starea de sănătate a hard disk-ului este mai proastă.
- Current_Pending_Sector: numărul de sectoare care sunt în așteptare pentru realocare în curând.
- Offline_Uncorectable: numărul de erori necorectabile la accesarea, fie la citire, fie la scriere, în diferite sectoare ale discului.
- Multi_Zone_Error_Rate: numărul total de erori în timpul scrierii unui sector.
În imaginea următoare puteți vedea starea unui hard disk WD Red 4TB de pe NAS-ul nostru cu sistemul de operare XigmaNAS:

În captura de ecran anterioară puteți vedea o mulțime de informații, dar trebuie să știm dacă este o defecțiune izolată sau discul nostru poate eșua în curând.
Starea discurilor din QNAP NAS
Dacă aveți un server NAS QNAP, Synology sau ASUSTOR, veți putea vedea și starea SMART a hard disk-urilor și SSD-urilor prin sistemul de operare cu acces web, nu este nevoie să intrați prin SSH sau Telnet și să executați orice comenzi . În exemplul de mai jos am folosit un server NAS QNAP, dar procesul cu ceilalți producători ar fi foarte asemănător.
Primul lucru pe care trebuie să-l facem este să mergem la „ Stocare și instantanee ”, odată aici, faceți clic pe „ Stocare / Discuri ” și vom vedea așa ceva:

Dacă facem clic pe „ Starea discului ”, va trebui să alegem pe ce disc dintre toate vrem să ne uităm. Putem selecta atât hard disk-uri HDD, cât și unități SSD, indiferent de tipul lor, deoarece au și informații interne SMART pentru a vedea dacă există o eroare de disc.

În meniul „Rezumat” putem vedea starea generală a discului, dacă există vreun tip de eroare sau avertisment grav, putem vedea și starea generală de sănătate cu ușurință și rapiditate, fără a fi nevoie să efectuăm o analiză detaliată a SMART valori . Desigur, putem vedea și istoricul accesului la disc și dacă au apărut probleme.

Deși QNAP ne oferă informații foarte ușor de înțeles, în cazul în care dorim să vedem toate valorile brute, o vom putea face și fără probleme. În plus, vom avea o coloană suplimentară care ne spune „Stare” și dacă este bine sau rău.
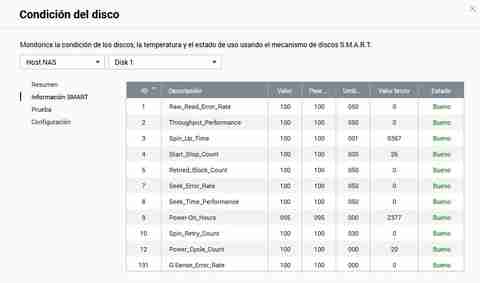
Vom putea face teste rapide sau complete prin aici, trebuie pur și simplu să alegem metoda de testare și apoi să facem clic pe butonul „Test”.

În sfârșit, putem programa și aceste teste într-un mod foarte ușor, pur și simplu trebuie să alegem să activăm testul rapid sau complet, și să alegem frecvența: zilnic, săptămânal sau lunar, în plus, putem defini ora de începere a acestui test.

După cum puteți vedea, verificarea și verificarea stării de sănătate a hard disk-urilor și a SSD-urilor de pe un server este ceva cu adevărat important pentru a evita pierderea de date. Când apare orice fel de eroare, este foarte important să cumpărați o unitate nouă și să faceți o copie de rezervă pentru a evita pierderea datelor. În plus, ar trebui să verificăm și starea RAID-ului deoarece am putea provoca pierderea întregului pool de stocare, mai ales dacă am configurat un ZFS RAID 0 sau Stripe.