
The Von Neumann architecture is the common architecture of all PC processors. Each and every one of the CPUs, from ARM to x86, from 8086 to Ryzen through Pentium. All of them are von Neumann architectures and they all inherit a certain common problem.
John Von Neumann was a Hungarian-born mathematician who is famous for two things. The first is for having worked on the Manhattan Project where the atomic bomb that the United States dropped against Japan at the end of World War II was developed. The second is the development of the base architecture that our PCs use nowadays, whatever size they are, as well as the form of the programs they execute.
What is Von Neumann architecture?
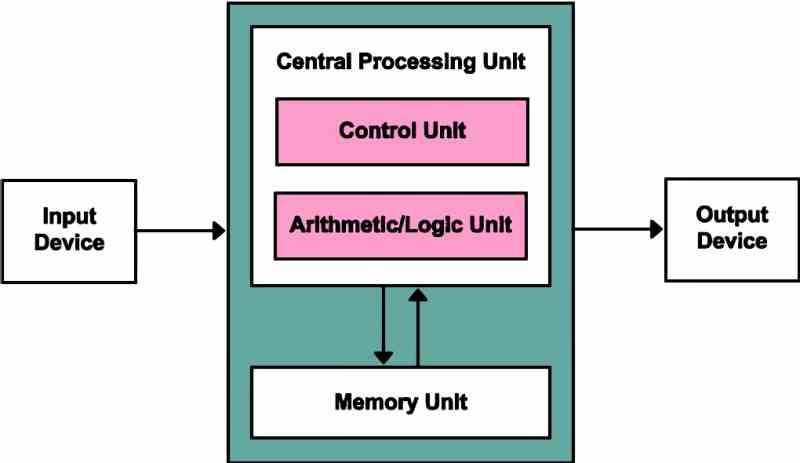
The Von Neumann architecture is on which all PC processors are based, since all of them are organized with a series of common components, which are the following:
- Control Unit: In charge of the acquisition and decoding stages of the instruction cycle.
- Logical-arithmetic unit or ALU: In charge of carrying out the mathematical and logic operations required by the programs.
- Memory: The memory in which the program is stored, which we know as RAM memory
- Input device: From which we communicate with the computer.
- Output Device: From which the computer communicates with us.
As you can see, it is the common architecture in all processors and that is why it has no more secret, but there is another type of architecture known as Harvard architecture in which the RAM memory is divided into two different wells, in one of They store the program instructions and the data in the other memory, having separate buses for both memory addressing and instructions.
What are the limitations of the Von Neumann architecture?
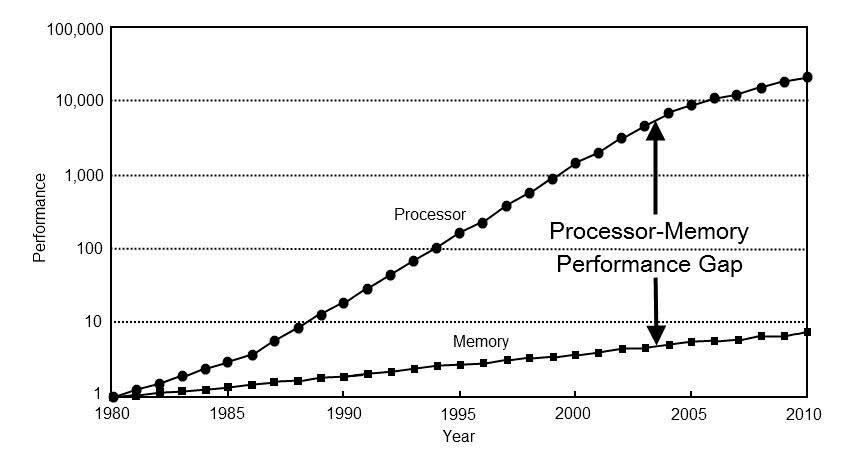
The main disadvantage is that the RAM memory, which is where the instructions and the data to be processed are located, are unified and shared through the same data bus and common addressing. So the instructions and data have to be captured sequentially from memory. This bottleneck is the so-called Von Neumann bottleneck. That is why the different microprocessors have the closest cache to the processor divided into two types, one for data and one for instructions.
In recent years, processor speeds have increased much faster than RAM memory, thus increasing the time it takes for data to be communicated from memory. What has forced to develop solutions to alleviate this problem, a product of the Von Neumann bottleneck.
In the processors where the Harvard architecture is normally used, they are self-contained and therefore do not have access to the common RAM of the system, but instead execute their own memory and program in isolation from the main CPU. These processors receive the list of data and instructions on two different data branches. One for the instruction memory and the other for the data memory of said processor.
Why is it used in CPU and GPU?

The main reason is the fact that increasing the number of buses means increasing the perimeter of the processor itself, since to communicate with the external memory it is necessary that the interface be on the outside of it. This leads to much larger and much more expensive processors. So the main reason Von Neumann architecture has become standardized is cost.
The second reason is that the two memory wells need to be synchronized so that an instruction does not apply to erroneous data. Which leads to having to create coordination systems between both memory wells. Of course, a good part of the bottlenecks would be eliminated by separating both buses. But neither would it completely reduce the Von Neumann bottleneck.
This is due to the fact that the Von Neumann bottleneck despite being a consequence of storing data and instructions in the same memory can also occur in a Harvard architecture if it is not fast enough to power the processor. That is why Harvard architectures have been reduced especially to microcontrollers and DSP. While Von Neumann is common on CPU and GPU