
Se você leu as especificações completas de alguns dos mais recentes Intel CPUs, você vai vi alguns acrônimos misteriosos aparecerem: GNA. Na realidade, é um pequeno processador, ou melhor, um coprocessador que é responsável por acelerar certos Aprendizagem profunda algoritmos e que, portanto, estão altamente relacionados com a implementação de inteligência artificial. Explicamos em que consiste este coprocessador e qual é sua funcionalidade.
Processadores dedicados a acelerar certas tarefas do dia a dia, usando modelos desenvolvidos via inteligência artificial, têm surgido nos últimos anos em todas as configurações e tamanhos e não é de se estranhar que a Intel não quisesse ficar para trás.
O que é Intel GNA?
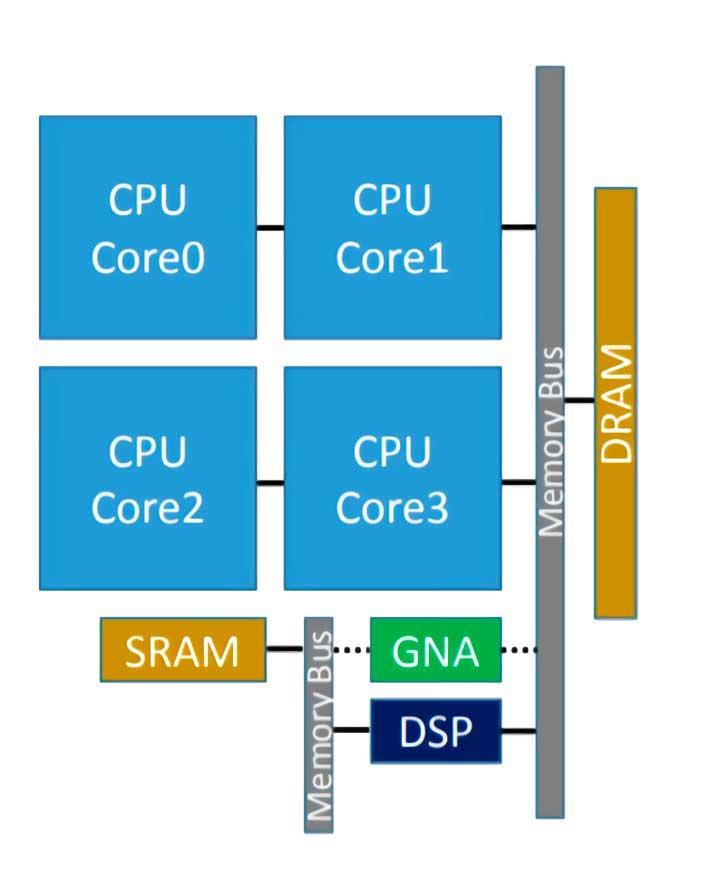
O Intel GNA é o coprocessador que algumas CPUs da Intel integraram e que serve para acelerar a execução de alguns algoritmos de inferência. Dito isso, muitos de vocês já sabem que, portanto, estamos diante de um processador do tipo neural, que neste caso foi introduzido pela primeira vez no Intel Ice Lake, e sua sigla significa Acelerador Neural Gaussiano ( RNG ), e sendo integrado no próprio processador funciona com um consumo muito baixo.
Destina-se a ser usado para tarefas como transcrição de áudio em tempo real ou remoção de ruído de foto, que são típicas para IA, mas não requerem um acelerador de alta potência.
Recentemente, foi melhorado em Tiger Lake, onde a versão 2.0 do GNA foi implementada, que se destina a ser usado também para cancelar o ruído ambiente e reduzir o ruído em fotografias. Com isso podemos deduzir que o GNA está pensado para ambientes de negócios colaborativos, principalmente aqueles baseados em teletrabalho em que a transcrição de texto e que a comunicação é realizada sem ruídos de qualquer espécie é muito importante.
Como funciona?
O Intel GNA não é uma unidade de execução do CPU então estamos lidando com um processador dentro de outro e isso serve para acelerar certas tarefas para seu convidado. Isso significa que ele deve ser invocado explicitamente no código por meio de uma API, neste caso a API Intel dedicada.
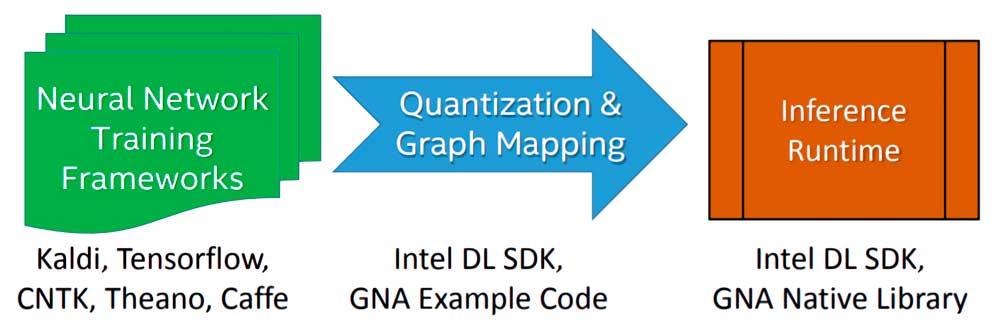
A implementação de um algoritmo ou modelo de Deep Learning a ser executado pelo Intel GNA durante a etapa de inferência é feita em três etapas:
- Começamos treinando o algoritmo usando uma rede neural de ponto flutuante com uma estrutura de livre escolha.
- O modelo resultante do treinamento é importado usando a ferramenta Intel Deep Learning SDK Deployment que permite importar qualquer modelo gerado pelos frameworks Deep Learning mais famosos e usados.
- Ele se conecta ao Intel Deep Learning SDK Inference Engine ou às bibliotecas nativas GNA, das quais existem duas: uma para Intel Quark e outra para Intel Atom e Intel Core.
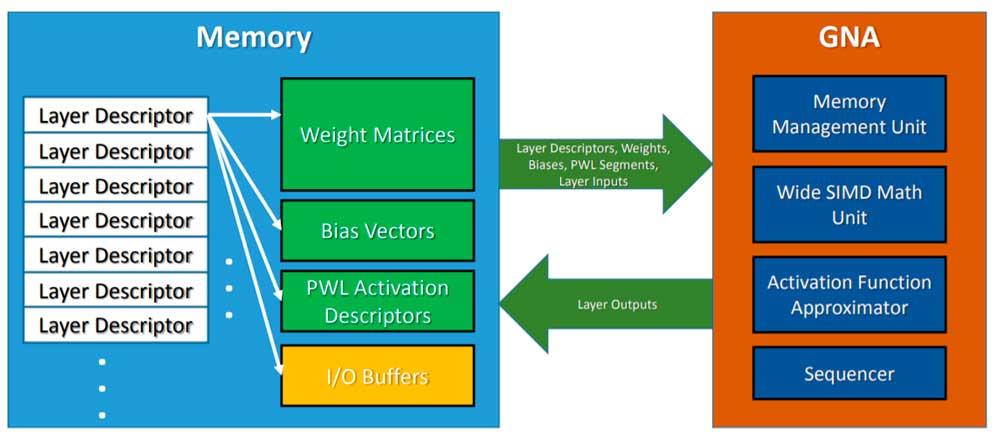
Para invocar o GNA, o que a CPU faz é deixar o modelo de inferência na memória, e o GNA é invocado para adotar o referido algoritmo e executá-lo paralelamente ao trabalho do processador do qual está hospedada. Também deve ser levado em conta que se trata de uma unidade de baixo consumo de energia, portanto não podemos esperar os mesmos resultados que usar uma rede neural de alto desempenho ou um FPGA configurado como tal, mas é bom o suficiente para tarefas simples do dia a dia .
Intel GNA fora das CPUs Intel

Embora o próprio GNA seja um processador integrado como parte de CPUs x86, ele pode ser implantado fora da CPU, se desejado, sendo o caso mais famoso o Intel Speech Habilitando Dev Kit , que é usado especialmente para inferência de comandos de voz para aplicativos para Amazon Alexa dispositivos.