
VLIW to skrót od Very Long Instruction Word, co przekłada się na bardzo długie instrukcje słowne. W świecie architektury procesorów służy do definiowania typu CPU lub procesor, który osiąga równoległość instrukcji lub ILP, ale z inną metodologią niż ta stosowana w procesorach superskalarnych, która jest powszechnie stosowana w procesorach.
Procesory typu VLIW mają wiele zalet i wad w porównaniu z innymi procesorami i były używane nie tylko w procesorach, ale także jako jednostki cieniujące dla GPU, a także DSP.
Obecnie wydaje się, że projekty VLIW zniknęły ze sprzętu komputerowego, jednak mimo ich nieużywania pozostają ważną opcją w projektowaniu nowych procesorów dla różnych obszarów rynku sprzętowego.
Jak działa procesor VLIW?
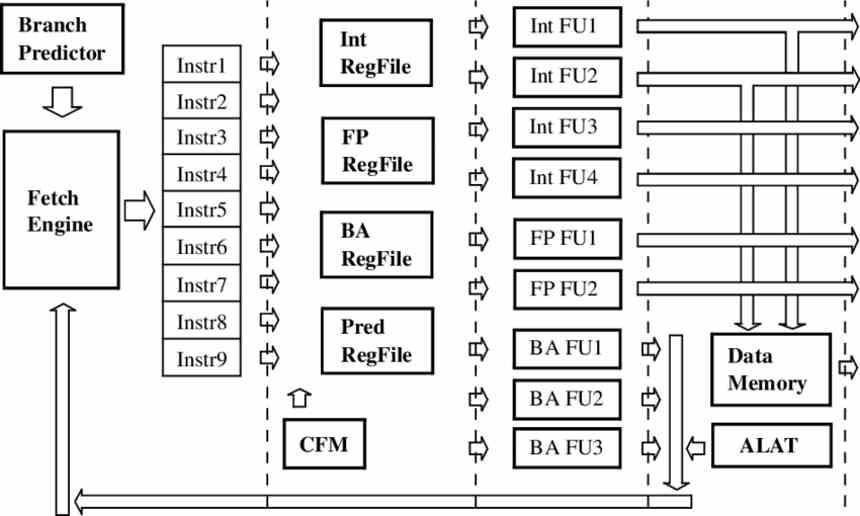
W superskalarnym procesorze lub konwencjonalnym ILP instrukcje są przechwytywane i przetwarzane indywidualnie podczas cyklu instrukcji każdego z nich. Niezależnie od tego, czy mówimy o realizacji w porządku, czy poza kolejnością. W przypadku procesora VLIW wystarczy zgrupować kilka instrukcji w jedną i wysłać je razem do różnych jednostek, które są dostępne w procesorze.
Osiągnąć to, procesory VLIW w dużym stopniu zależą od kompilatora podczas generowania kodu binarnego , który będzie grupował różne instrukcje w jedną instrukcję, zawsze biorąc pod uwagę poziom zajętości każdej z jednostek wykonawczych w każdym momencie operacji. wykonanie, które będzie zależeć od liczby cykli zegara wymaganych przez każdą z instrukcji.
Ponieważ instrukcje mogą mieć różne stopnie czasu trwania w odniesieniu do cykli zegara, jest to problem z wydajnością, ponieważ podczas kilku cykli zegara będziemy mieli jednostki wykonawcze, które nic nie zrobią i będą wykonywać instrukcję NOP, co oznacza, że podczas tego zegara cykl wspomniana jednostka nie wykonuje żadnej operacji. To sprawia, że procesory VLIW są wysoce zależne od kompilatora w celu uzyskania maksymalnej wydajności.
Zalety i wady projektu VLIW

Głównie korzyści, jakie przynosi, są następujące:
- Sprzęt odpowiedzialny za dekodowanie instrukcji jest znacznie prostszy niż procesor ILP lub TLP, co pozwala na pozostawienie większej ilości wolnego miejsca na chipie dla jednostek wykonawczych, a tym samym na wykonanie większej liczby instrukcji w tym samym czasie.
- Posiadanie większej ilości miejsca pozwala również na umieszczenie większej liczby rejestrów, co jest idealnym rozwiązaniem dla ułatwienia wykonywania spekulacyjnego typowego dla nieczynnych procesorów bez potrzeby stosowania bufora sortowania.
Jeśli chodzi o jego wady, pierwsza z nich polega na tym, że wymagany jest znacznie bardziej złożony kompilator, a druga to ta, o której wspomnieliśmy wcześniej i która opiera się na fakcie, że istnieje większe marnotrawstwo różnych jednostek wykonawczych, ponieważ większość z nich będzie dobrze spędzać wolny czas.
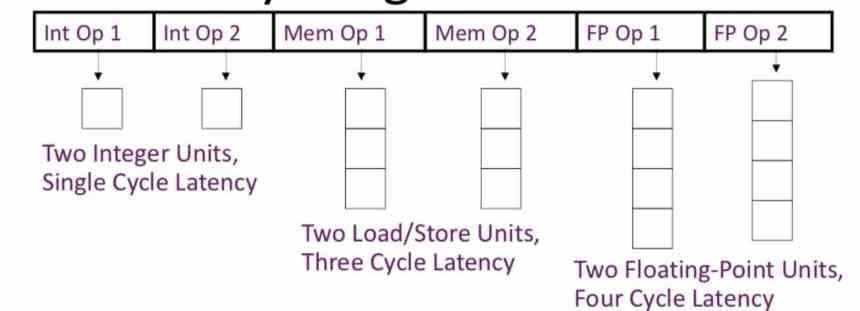
Aby lepiej to zrozumieć, wyobraź sobie, że zgrupowałeś instrukcje VLIW 3, które wymagają wykonania pierwszych 4 cykli, drugich 7 cykli i trzecich 10 cykli. Jednostka wykonawcza odpowiedzialna za wykonanie pierwszej instrukcji będzie składać się z 6 cykli zegara bez robienia czegokolwiek, drugiej 3, a wszystko to dlatego, że trzecia będzie potrzebowała 10 cykli do działania.
Z drugiej strony musimy dodać fakt, że chociaż na poziomie instrukcji pliki binarne się nie zmieniają, to przy opracowywaniu nowego procesora możliwe jest, że instrukcja już istnieje, zwiększa lub zmniejsza liczbę cykli. To sprawia, że inny kompilator jest konieczny nawet dla nowych iteracji nowego procesora, co utrudnia uruchomienie bardziej zaawansowanych wersji procesora i wymaga w wielu przypadkach utworzenia kompilatora binarnego na binarny, który zmienia kolejność instrukcji dla nowego procesora.
Generowanie instrukcji przez kompilator

Abyś mógł to lepiej zrozumieć, przygotowaliśmy kilka list, pierwsza to wykonanie w procesorze superskalarnym lub znanym jako ILP, druga to procesor typu VLIW.
Zaczynając od procesora typu ILP, lista jego instrukcji wyglądałaby następująco:
- Załaduj A1
- Załaduj B1
- Załaduj A2
- Opłata B2
- Pomnóż wartości A1 i B1
- Dodaj wartości A2 i B2
- Dodaj A1 i A2
- Ładunek A3
- Obciążenie B3
- Pomnóż A3 przez B3
- Dodaj B1 i B2.
Z drugiej strony procesor VLIW zgrupuje kilka instrukcji w jedną:
- A2 i B2 są ładowane jednocześnie
- Załaduj A2 i B2, pomnóż A1 i B1, dodaj A2 i B2.
- Załaduj A3, B3, pomnóż A3 przez B3 i dodaj B1 i B2.
Fakt, że udało nam się pogrupować 11 instrukcji w tylko 3 bardzo duże instrukcje, oznacza, że ilość czasu potrzebna na każdą z instrukcji VLIW będzie co najwyżej czasem potrzebnym na wykonanie najbardziej złożonej instrukcji w grupie instrukcji.
Dostęp do pamięci tego typu procesorów

Jak wspomnieliśmy wcześniej, procesory VLIW zależą od kompilatora i wielokrotnie dodają do kodu instrukcje NOP podczas kompilacji. Powodem tego jest to, że tworzenie procesora VLIW z instrukcjami o zmiennym rozmiarze jest niezwykle złożone, więc robi się to po to, aby utworzyć stały rozmiar bitów, przy których procesor odczytuje instrukcje i pobiera tę ilość danych z pamięci w każdym cyklu . i instrukcje.
Oznacza to, że procesory VLIW wymagają znacznie szerszych magistral danych niż konwencjonalne procesory, ponieważ grupują dużą liczbę bitów za każdym razem, gdy przechwytują nowe instrukcje do wykonania. Jest to jego wielka pięta achillesowa, ponieważ w procesorach ILP, powszechnych w procesorach komputerów PC, stosowane są mniejsze szerokości danych, a tym samym prostsze kontrolery pamięci.
Normalną rzeczą w procesorach VLIW jest to, że przechwytują one następujące instrukcje do wykonania podczas wykonywania bieżącej instrukcji VLIW. Ponieważ grupując kilka instrukcji w jedną, skraca się czas przechwytywania każdej z nich z osobna.