
Jeśli przeczytałeś pełną specyfikację niektórych najnowszych Intel Procesory, będziesz widzieli pojawiające się tajemnicze akronimy: GNA. W rzeczywistości jest to mały procesor, a raczej koprocesor, który jest odpowiedzialny za przyspieszenie niektórych głęboki Learning algorytmów i dlatego są one silnie związane z wdrażaniem sztucznej inteligencji. Wyjaśniamy, z czego składa się ten koprocesor i jaka jest jego funkcjonalność.
Procesory dedykowane do przyspieszania niektórych codziennych zadań, wykorzystujące modele opracowane za pomocą sztucznej inteligencji, pojawiały się w ostatnich latach we wszystkich konfiguracjach i rozmiarach i nic dziwnego, że Intel nie chciał zostać w tyle.
Co to jest Intel GNA?
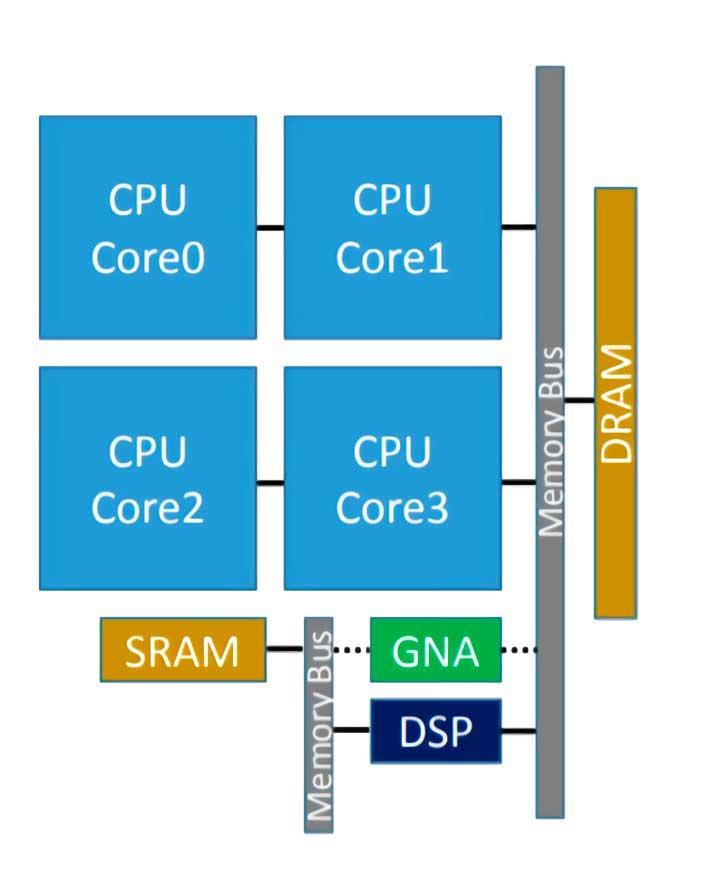
Intel GNA to koprocesor zintegrowany z niektórymi procesorami Intela, który służy do przyspieszenia wykonywania niektórych algorytmów wnioskowania. To powiedziawszy, wielu z was już wie, że w związku z tym mamy do czynienia z procesorem typu neuronowego, który w tym przypadku został po raz pierwszy wprowadzony w Intel Ice Lake, a jego akronim oznacza Akcelerator neuronów Gaussa ( GNA ), a integracja z własnym procesorem działa przy bardzo niskim zużyciu.
Jest przeznaczony do zadań takich jak transkrypcja dźwięku w czasie rzeczywistym lub usuwanie szumów fotograficznych, które są typowe dla sztucznej inteligencji, ale nie wymagają akceleratora o dużej mocy.
Niedawno został ulepszony w Tiger Lake, gdzie zaimplementowano wersję 2.0 GNA, która ma być również używana do usuwania szumów otoczenia i redukcji szumów na zdjęciach. Na tej podstawie możemy wywnioskować, że GNA jest przeznaczona do środowisk biznesowych opartych na współpracy, zwłaszcza tych opartych na telepracy, w których transkrypcja tekstu i komunikacja odbywa się bez jakiegokolwiek hałasu, jest bardzo ważne.
Jak to działa?
Intel GNA nie jest jednostką wykonawczą platformy CPU więc mamy do czynienia z procesorem w innym i służy to przyspieszeniu niektórych zadań dla jego gościa. Oznacza to, że musi być jawnie wywoływany w kodzie za pośrednictwem interfejsu API, w tym przypadku dedykowanego interfejsu Intel API.
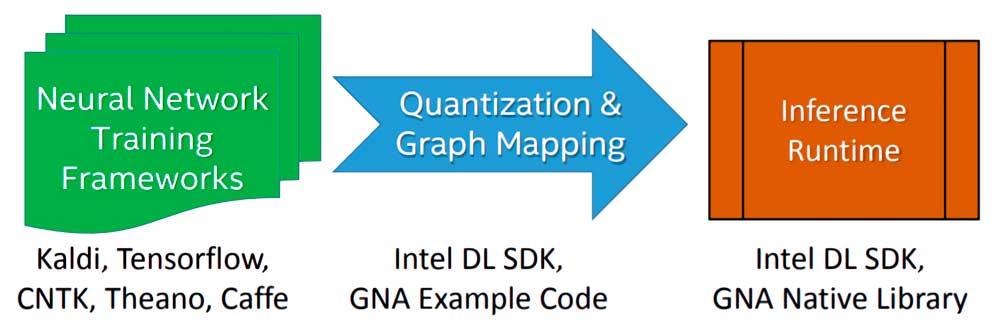
Implementacja algorytmu lub modelu Deep Learning do wykonania przez Intel GNA na etapie wnioskowania odbywa się w trzech etapach:
- Zaczynamy od szkolenia algorytmu przy użyciu zmiennoprzecinkowej sieci neuronowej z ramą dowolnego wyboru.
- Model wynikający ze szkolenia jest importowany przy użyciu narzędzia Intel Deep Learning SDK Deployment Tool, które umożliwia importowanie dowolnego modelu wygenerowanego przez najbardziej znane i używane platformy Deep Learning.
- Łączy się z silnikiem wnioskowania Intel Deep Learning SDK lub natywnymi bibliotekami GNA, z których są dwie: jedna dla Intel Quark, a druga dla Intel Atom i Intel Core.
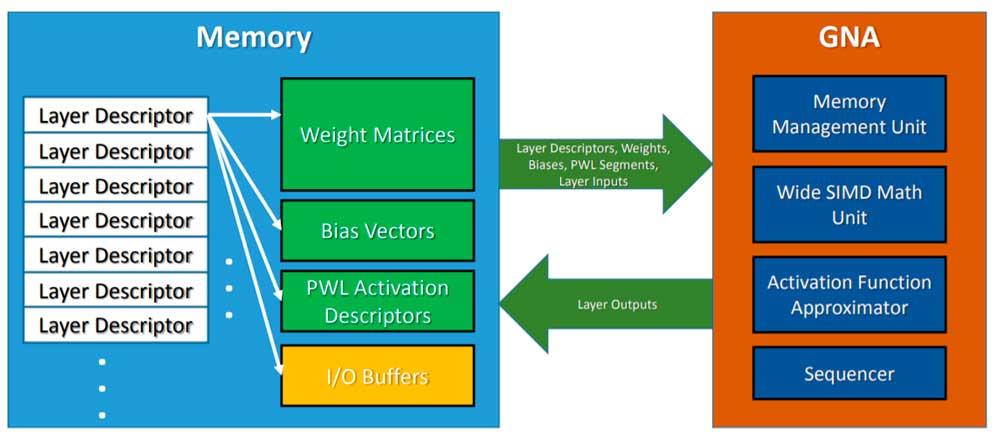
W celu wywołania GNA, procesor pozostawia model wnioskowania w pamięci, a GNA jest wywoływany w celu przyjęcia wspomnianego algorytmu i wykonania go równolegle do pracy procesora, którego jest hostem. Trzeba też wziąć pod uwagę, że jest to jednostka małej mocy, więc nie możemy oczekiwać takich samych rezultatów, jak przy korzystaniu z wysokowydajnej sieci neuronowej lub tak skonfigurowanego FPGA, ale jest wystarczająco dobry do zadań prostych z dnia na dzień .
Intel GNA poza procesorami Intel

Chociaż sam GNA jest procesorem zintegrowanym jako część procesorów x86, w razie potrzeby można go wdrożyć poza procesorem, najbardziej znanym przypadkiem jest Zestaw deweloperski umożliwiający obsługę mowy Intel , który jest używany szczególnie do wnioskowania poleceń głosowych dla aplikacji dla Amazon Alexa urządzeń.