Det er et resultat av kontrovers, kanonfôr for brukere som er lite relatert til den rene glede av teknologien som begge selskapene tilbyr, og likevel er det et faktum som har blitt opprettholdt siden Radeon X800. NVIDIA tok kommandoen over grafikkort i slutten av 2005 og har regjert med jernhånd i 15 år siden den gang, men hva stopper AMD fra å lansere en GPU som overgår konkurrenten?
Det er flere sentrale faktorer som NVIDIA alltid har vært tydelig på når lanseringen av nye GPU-er til markedet og som AMD har begynt å forstå i drøyt to år.

Disse faktorene er egentlig ikke aktuelle utover selve arkitekturene, men de har interessante konnotasjoner som etterlater en klar beskjed som lover å endre det gjeldende grafikkortlandskapet.
arkitektur
Vi tar utgangspunkt i at vi forstår naturen til en GPU som sådan, det vil si at de er fantastiske "gigantiske kalkulatorer" for FP-operasjoner, derfor er de gode for parallelle operasjoner. De aller fleste beregninger er gjort av FPU-enheter, og i motsetning til CPUer er disse enhetene som sådan ikke programmerbare av programvaredesignere, men er heller litt mer abstrakte og helt avhengige av driveren som støtter dem.
Dette overlater AMD og NVIDIA til å optimalisere produktene sine så få enheter på en PC har. Samtidig er dette bare begynnelsen på problemet med hovedargumentet i denne artikkelen, og det er at NVIDIA tildeler så store mengder ressurser at utviklingsgruppen internt blir referert til som "NVIDIA Army".

Antall programvareutviklere de har er langt bedre enn AMD, og her er en del av overlegenheten til deres GPUer. Det må forstås at i arkitekturen og fra nøyaktig slutten av 2005 har grafikkortene de samme enhetene som skal fungere: ALUer / FPU TMUer og ROPer (bortsett fra de tilsvarende cachene og tydelig VRAM), og bare Turing har pålagt den nye RT Kjerner og Tensorkerner for forskjellige oppgaver.
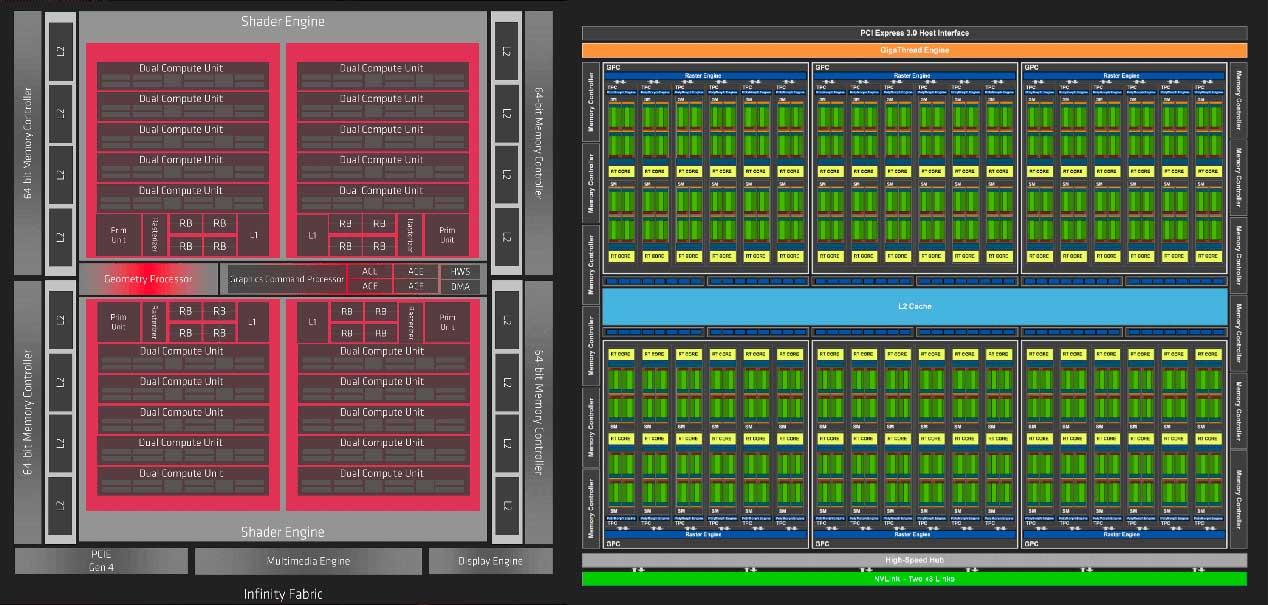
Dette antar igjen at programvareoptimalisering kombinert med arkitektoniske forbedringer utgjør en større forskjell for hver generasjon hvis du ikke går raskere enn rivalen. For å være spesifikk inkluderer Navi som arkitektur to Shader-motorer blokkerer at AMD igjen deler seg i den berømte Asynchronous Compute Motors (ACE) , der hver har 5 WGP og to CUer.
For ren sammenligning har NVIDIA i Turing 6 GPC-er med 6 TPC-er i hver og to SM-er for hver blokk. Denne enkle visjonen om strukturen til hver arkitektur får oss til å se at parallelliseringen av Huangs er mye høyere og mer konfigurerbar enn AMD, som har mye kraftigere blokker helt, men som samtidig innebærer å være mindre energieffektiv enn konkurrentens valg.
Til slutt må det forstås at det er en radikal forskjell i tilnærmingen til driften av begge arkitekturer, som kommer fra fortiden ved enkel evolusjon av det samme: NVIDIA jobber med skalare utførelsesenheter, AMD bruker på sin side enheter som jobber med vektorer.
Hva innebærer dette? En helt annen optimalisering for å fungere av utviklere og samtidig for sin opasitet, det er en vegg som AMD prøver å bryte ned og tilbyr enheter som er enklere å programmere og med bedre ressurser.
Forbruk
Et annet problem som AMD har hatt i årevis, og at selv med en litografisk prosess som er mye mer avansert enn konkurrenten, klarer den ikke å være foran. Igjen, alt er et arkitektur- og optimaliseringsproblem.
NVIDIA er i stand til å deaktivere alle grupper av TPC-er og til og med hele GPC-er i millisekunder, i stor grad variere arbeidsmengden og at de sammen med forskjellige teknologier som flislagt eller fargekomprimering på høyt nivå gjør at enhetene deres fungerer mer effektivt og derfor klarer de å øke ytelse ved å forbruke mindre energi.
Optimalisering er nøkkelen, og her klarer NVIDIA ved drift av enhetene å gjøre mer enn AMD i samme klokkesyklus. Du bør ikke se på dette så mye fra ytelsen (som åpenbart er bedre), men fra forbruket.
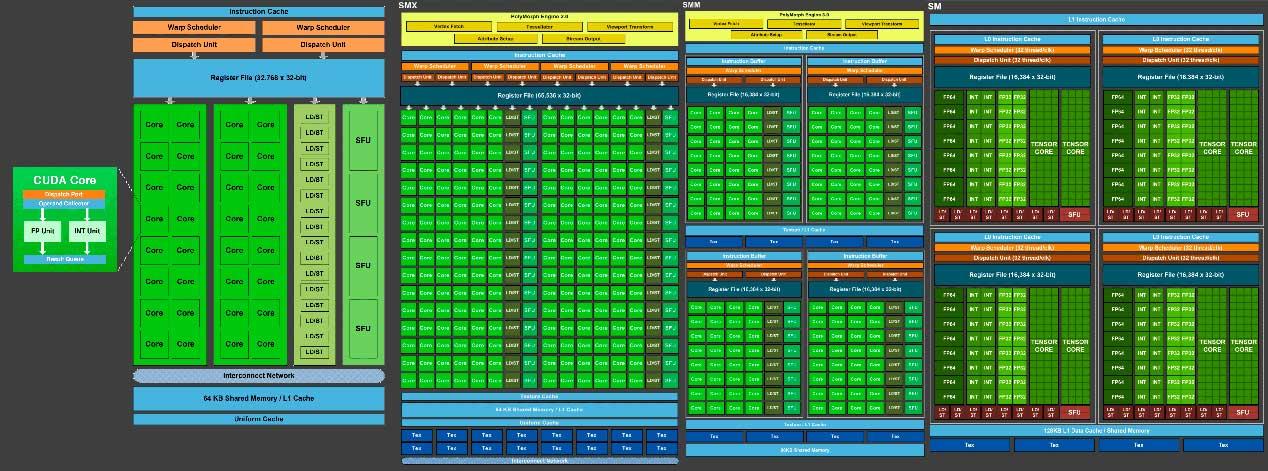
En skalar enhet tillater en flytende instruksjon og ett heltall samtidig og per klokkesyklus. Omorganiseringen av arkitekturen i NVIDIA gjør det mulig for en programmerer å jobbe med vektoroperasjoner på en enklere måte enn i AMD, spesielt nå som Turing har tre forskjellige godt differensierte motorer innen hver SM.
Dette gjør at rasterisering kan fokuseres bedre på disse motorene, det være seg INT32 , FP32 eller Tensor-kjerner , tillater, hvis ikke nødvendig, å deaktivere komplette GPC-er eller noen av disse motorene, sparer forbruket og er mer effektive på jobb. .
Prisene

Det er en avgjørende faktor når vi snakker om hvilken GPU som er “bedre”. For NVIDIA har strategien med høye priser som tilbyr innovative teknologier fungert denne gangen, men realiteten er at både Ray Tracing og DLSS ikke har vært et så stort skritt visuelt som det var ment, og de har ikke vært fri for kontrovers eller problemer.
Å tilby et lavere produkt til en lavere pris gjør det ikke bedre i seg selv, du må vite hvordan du skal plassere det på en attraktiv måte. Delene av forbruk og arkitektur fører direkte til det og gjør at AMD blir sett på som det rimeligste alternativet etter pris til et større antall brukere.
Navi overrasket NVIDIA på dette punktet, siden de arkitektoniske forbedringene har vært dype, og det har vært et betydelig sprang som gjorde at Huang lanserte en ny serie kort for å dekke hull. Men virkeligheten over hele verden er at brukeren verdsetter teknologiene, ytelsen og forbruket som NVIDIA tilbyr til en høyere pris. Det er ikke for ingenting at det eier mer enn 60% av verdensmarkedet, så vi er i posisjonen til de som kan velge å betale noe mer for at en NVIDIA GPU skal dra nytte av sin nye teknologi og de som rett og slett ikke vil å gå gjennom den ringen av forskjellige grunner.
I alle fall har AMD normalt vært på slep i mer enn 15 år i denne delen. NVIDIA setter priser med sine nye GPUer og AMD fyller ut hullene med sine GPUer.