SWAR-konseptet vil virke rart for mange, men hva skjer hvis vi forteller deg at SIMD-enhetene til CPU-ene dine, GPU-ene i systemene dine stort sett er av SWAR-typen? Denne typen enheter skiller seg fra konvensjonelle SIMD-enheter og har sin opprinnelse i multimedia-utvidelsene på slutten av 90-tallet. Hva er de og hva bruker de i dag?
Ytelsen til en prosessor kan måles på to måter, på den ene siden hvor raskt den utfører instruksjonene i serie, og at de derfor ikke kan parallelliseres, siden de bare påvirker enhetsdata. På den annen side, de som jobber med flere data og kan parallelliseres. Den tradisjonelle måten å gjøre det på CPUer og GPUer? SIMD-enhetene, hvorav det er en undertype som er sterkt brukt i CPUer og GPUer, SWAR-enhetene.

ALU og deres kompleksitet
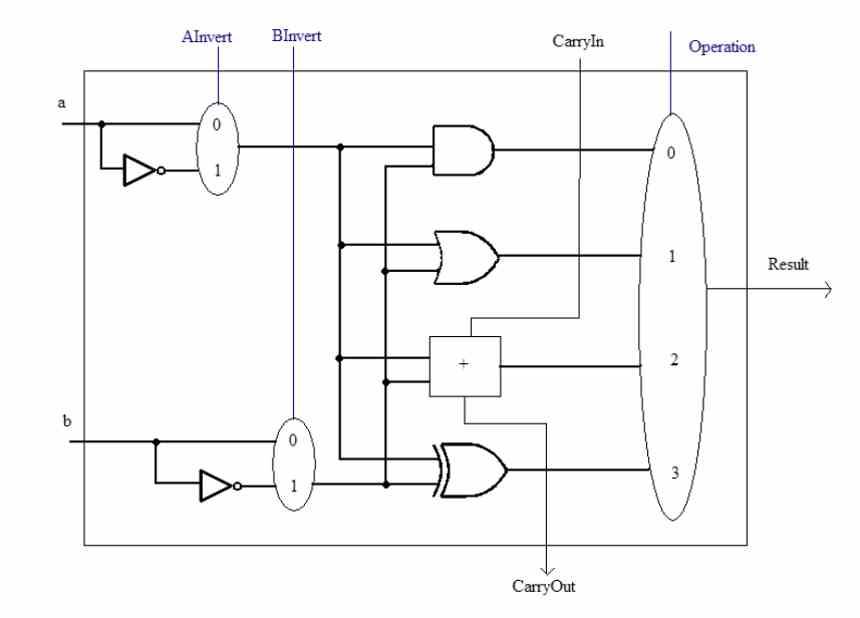
Før vi snakker om SWAR-konseptet, må vi huske at ALU er enhetene til a prosessor som er ansvarlige for å utføre aritmetiske og logiske beregninger med de forskjellige tallene. Disse kan vokse i kompleksitet på to måter, en fra kompleksiteten i instruksjonene de må utføre. Den interne kretsen til en ALU som kan utføre, for eksempel, beregningen av en kvadratrot er ikke den samme som for en enkel sum.
Den andre er presisjonen de jobber med, det vil si antall biter som de manipulerer samtidig hver gang. En ALU kan alltid håndtere data som er lik eller mindre enn antall biter den er designet for. For eksempel kan vi ikke få et 32-bit tall beregnet av en 16-bit ALU, men vi kan gjøre det motsatte.
Men hva skjer når vi har flere data med lavere presisjon? Normalt skal de løpe i samme hastighet som full presisjon, men det er en måte å øke hastigheten på dem, og det er SIMD-registeret som er overregistrert. Som også er en måte å lagre transistorer i en prosessor.
Hva er SWAR-konseptet?
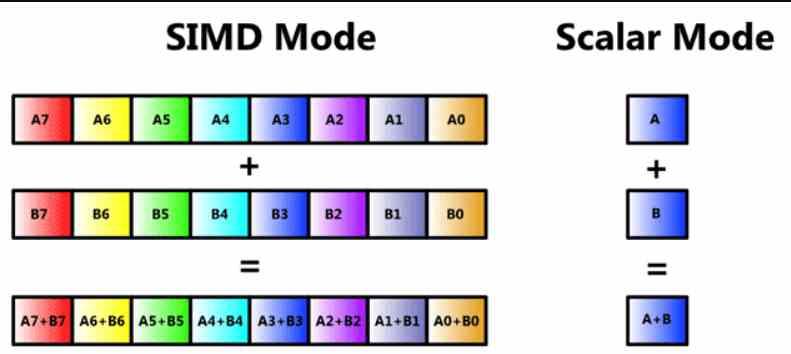
Nå vil mange av leserne vite at det er en SIMD-enhet, men vi skal gjennomgå den slik at ingen mister tråden i denne artikkelen fra begynnelsen. En SIMD-enhet er en type ALU der flere data blir manipulert gjennom en enkelt instruksjon samtidig, og derfor er det flere ALUer som deler nedslagsdelen av hva selve instruksjonen er og dens dekoding, men hvor i hver en annen informasjon blir behandlet.
SIMD-enheter består vanligvis av flere ALUer, men det er tilfeller der ALUene er delt inn i enklere, samt akkumuleringsregisteret der de midlertidig lagrer dataene sine for å beregne dem. Dette kalles SIMD på et register eller ved akronymet på engelsk SWAR, som betyr SIMD Within a Register eller SIMD i et register.
Denne typen SIMD-enhet er sterkt brukt og lar en presisjons-n-bit ALU utføre den samme instruksjonen, men bruker data med mindre presisjon. Vanligvis med en halv eller en kvart presisjon. For eksempel kan vi få en 64-bit ALU til å fungere som to 32-bit ALUer ved å utføre instruksjonen parallelt, eller fire 16-bit.
Går du dypere inn i SWAR-konseptet?
Dette konseptet er allerede flere tiår gammelt, men første gang de dukket opp på PC var på slutten av 90-tallet med utseendet til SIMD-enheter i de forskjellige typer prosessorer som eksisterte. Veteranene på stedet vil huske konsepter som MMX, AMD 3D Now!, SSE og lignende var SIMD-enheter bygget under SWAR-konseptet.
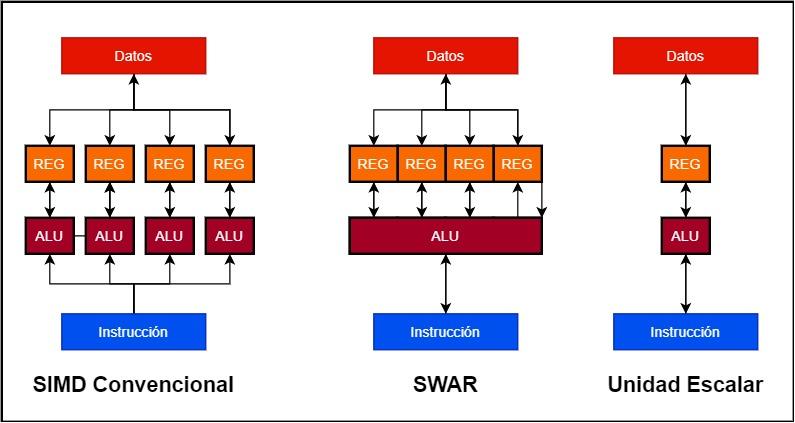
Anta at vi vil bygge en 128 bit SIMD-enhet
- I konvensjonelle SIMD-enheter har vi flere ALUer som arbeider parallelt, og hver av dem har sitt eget dataregister eller akkumulator. Dermed kan en 128-bit SIMD-enhet bestå av 4 32-bit ALUer og 4 32-biters registre.
- I stedet er en SWAR-enhet en enkelt ALU som kan fungere i svært høy presisjon så vel som akkumulatorregisteret. Dette gjør at vi kan bygge SIMD-enheten ved hjelp av en enkelt 128-bit ALU med SWAR-støtte.
Fordelen som implementeringen av en SWAR-enhet har over en skalar er enkel å forstå. Hvis en ALU ikke inneholder SWAR-mekanismen som gjør at den kan fungere som en SIMD-enhet med mindre presisjonsdata, vil den utføre dem samtidig hastighet. data med høyeste presisjon. Hva betyr dette? En 32-biters enhet uten SWAR-støtte, i tilfelle den må bruke samme instruksjon på 16-biters data, vil gjøre det i samme hastighet som en 32-biters. På den annen side, hvis ALU støtter SWAR, vil den kunne utføre to 16-biters instruksjoner i samme syklus, i tilfelle begge kommer suksessivt.
SWAR som en patch for AI

Kunstig intelligensalgoritmer har en egenart, de har en tendens til å jobbe med data med svært lav presisjon, og i dag opererer de fleste ALUer med 32-biters presisjon. Dette betyr å legge til presisjon 16-, 8- og til og med 4-bit ALUer til en prosessor for å øke hastigheten på disse algoritmene. Noe som skal komplisere prosessoren, men ingeniørene falt ikke inn i den feilen og begynte å trekke SIMD-registeret på en bestemt måte, spesielt på GPUer.
Er det mulig å kombinere en konvensjonell ALU SIMD med et SWAR-design? Vel, ja, og dette er for eksempel AMD som gjør i GPU-ene sine, hvor hver av de 32-biters ALU-ene som utgjør SIMD-enhetene til RDNA-GPUene, støtter SIMD over register og derfor kan deles inn i to 16-bits, 4 på 8 bits eller 8 på 4 bits.
Ved NVIDIA, de har gitt byrden med å akselerere algoritmene for AI til Tensor Cores, dette er systoliske arrays sammensatt av 16-biters flytende ALU-er som er sammenkoblet i hverandre i en tre-akset matrise, derav enhetsnavnet. Tensor. De er ikke SIMD-enheter, men hver av deres ALU-er støtter SIMD over register ved å kunne utføre dobbelt så mange operasjoner med 8-biters presisjon og fire ganger med 4-biters presisjon. I alle fall er Tensorenheter viktige fordi de er designet for å akselerere matrise-til-matrise-operasjoner med mye høyere hastighet enn med en SIMD-enhet.