Et av nøkkelbegrepene for å forstå arkitekturen og ytelsen til strøm Intel og AMD CPUer er konseptet med mikrooperasjoner, så vel som enheter som cachen deres. I denne artikkelen vil vi fortelle deg på en tilgjengelig måte hva de er og hvorfor dagens prosessorer baserer all drift på dem for å oppnå maksimal ytelse.
A prosessor i dag kan utføre et stort antall forskjellige instruksjoner, og det gjør det ved frekvenser som er opptil 5,000 ganger høyere enn for tidlige personlige datamaskiner. Vi har en tendens til å tro og helt feil at den større mengden MHz eller GHz skyldes de nye produksjonene. Virkeligheten er veldig annerledes, og det er her mikrooperasjoner kommer inn, som er nøkkelen til å oppnå den enorme datakraften til dagens mikroprosessorer.

Hva er mikrooperasjoner?
En av likhetene med virkeligheten som vanligvis brukes for å forklare hva et program er, er likheten med en matlagingsoppskrift. Der vi kan se tildelt i et verb en rekke handlinger som vi må utføre. Jeg kan for eksempel legge inn en oppskrift på at du steker et kjøttstykke i pannen, men for deg vil det vise seg å måtte lete etter pannen, gjør det samme med oljen, legg sistnevnte i pannen, vent for at den skal bli varm og legg kjøttstykket i den. Som du kan se, har vi konvertert noe som i prinsippet er definert av et enkelt verb til en rekke handlinger.
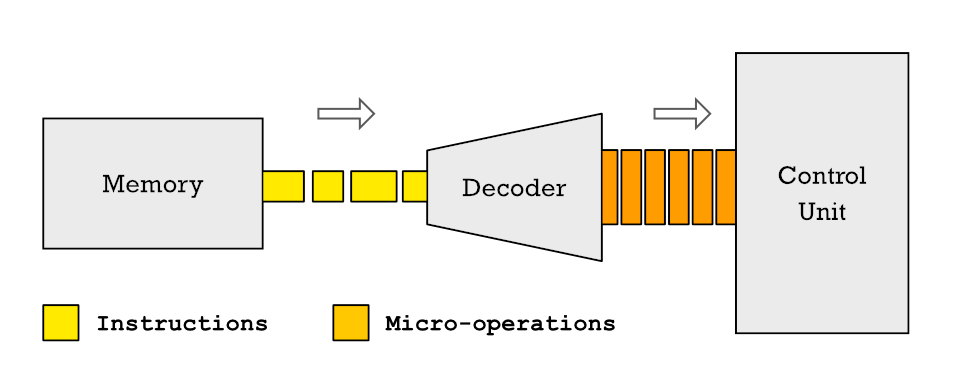
Vel, instruksjonene til en CPU kan deles opp i mindre som vi kaller mikrooperasjoner. Og hvorfor ikke mikroinstruksjoner? Vel, på grunn av det faktum at en instruksjon, bare ved å segmentere den i flere sykluser for utførelse, tar flere klokkesykluser å løse. En mikrooperasjon, derimot, tar en enkelt klokkesyklus.
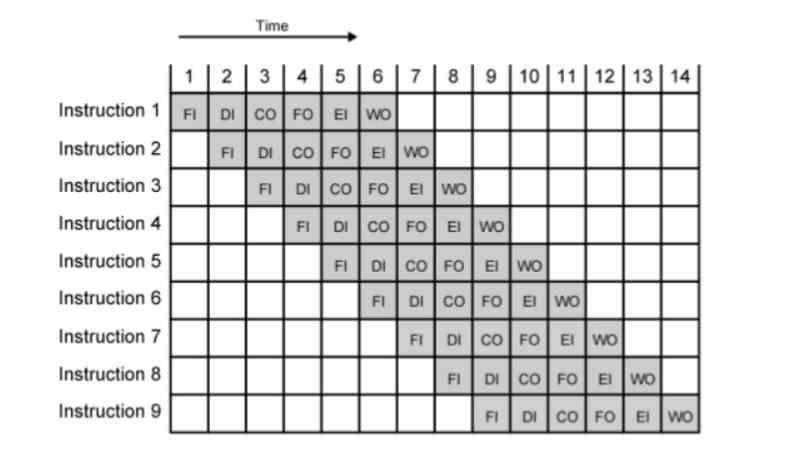
En måte å få mest mulig MHz eller GHz på er pipelining, der hver instruksjon utføres i flere trinn som hver varer en klokkesyklus. Siden frekvens er det motsatte av tid, må vi forkorte tiden for å få mer frekvens. Problemet er at punktet nås hvor en instruksjon ikke lenger kan dekomponeres, antall trinn i rørledningen blir kort og dermed er klokkehastigheten som kan oppnås lav.
Egentlig ble disse født med utseendet til utførelse av Intel P6-arkitekturen og dens avledede CPUer som Pentium II og III. Grunnen til dette er at segmenteringen av P5 eller Pentium bare tillot dem å nå litt over 200 MHz. Med mikrooperasjonene, ved å forlenge antall trinn i hver instruksjon enda mer, overgikk de GHz-barrieren med Pentium 3 og kunne ha klokkehastigheter 16 ganger høyere med Pentium 4. Siden den gang har de blitt brukt i alle CPUer med utførelse uten drift, uavhengig av merke og register og instruksjonssett.
CPU-ene dine er verken x86, RISC-V eller ARM
I gjeldende CPUer når instruksjoner kommer til CPU-kontrollenheten som skal dekodes og tildeles kontrollenheten, blir de først brutt ned i flere forskjellige mikrooperasjoner. Dette betyr at hver instruksjon som prosessoren utfører består av en serie grunnleggende mikrooperasjoner og settet med dem i en ordnet flyt kalles mikrokode.

Dekomponering av instruksjoner til mikrooperasjoner og transformasjon av programmer lagret i RAM inn mikrokode finnes i dag i alle prosessorer. Så når telefonen din er ISA ARM CPU eller din PCs x86 CPU kjører programmer, dens utførelsesenheter løser ikke instruksjoner med disse settene med registre og instruksjoner.
Denne prosessen har ikke bare fordelene som vi har forklart i forrige avsnitt, men vi kan også finne instruksjoner som, selv innenfor samme arkitektur og under samme sett med registre og instruksjoner, er brutt ned annerledes og programmene er fullt kompatible. Tanken er ofte å redusere antallet klokkesykluser som kreves, men mesteparten av tiden er det for å unngå striden som oppstår når det er flere forespørsler til den samme ressursen i prosessoren.
Hva er mikrooperasjonsbufferen?
Det andre viktige elementet for å oppnå maksimal ytelse er mikrooperasjonsbufferen, som er senere enn mikrooperasjonene og derfor nærmere i tid. Opprinnelsen kan finnes i sporingsbufferen som Intel implementerte i Pentium 4. Det er en utvidelse av cachen på første nivå for instruksjoner som lagrer korrelasjonen mellom de forskjellige instruksjonene og mikrooperasjonene der de tidligere har blitt demontert av kontrollenheten .

Imidlertid har x86 ISA alltid hatt et problem med hensyn til RISC-typen, mens sistnevnte har en fast instruksjonslengde i koden, i tilfellet med x86 kan hver av dem måle mellom 1 og 15 byte. Vi må huske på at hver instruksjon hentes og dekodes i flere mikrooperasjoner. For å gjøre dette, selv i dag, er det nødvendig med en svært kompleks kontrollenhet som kan forbruke opptil en tredjedel av energieffekten uten de nødvendige optimaliseringene.
Mikrooperasjonscachen er altså en utvikling av sporingscachen, men den er ikke en del av instruksjonsbufferen, den er en maskinvareuavhengig enhet. I en mikrooperasjonsbuffer er størrelsen på hver av dem fastsatt i form av antall byte, noe som lar for eksempel en CPU med ISA x86 operere så nært som mulig en RISC-type og redusere kompleksiteten til kontrollenheten og med den forbruk. Forskjellen fra Pentium 4 plot-cachen er at den nåværende mikrooperasjonsbufferen lagrer alle mikrooperasjonene som tilhører en instruksjon på en enkelt linje.
Hvordan virker det?
Det mikrooperasjonsbufferen gjør er å unngå arbeidet med å dekode instruksjonene, så når dekoderen nettopp har utført oppgaven, er det den gjør å lagre resultatet av arbeidet i nevnte hurtigbuffer. På denne måten, når det er nødvendig å dekode følgende instruksjon, er det som gjøres å søke om mikrooperasjonene som danner den er i cachen. Motivasjonen for å gjøre dette er ingen ringere enn det faktum at det tar mindre tid å konsultere nevnte cache enn å ikke dekomponere en kompleks instruksjon.
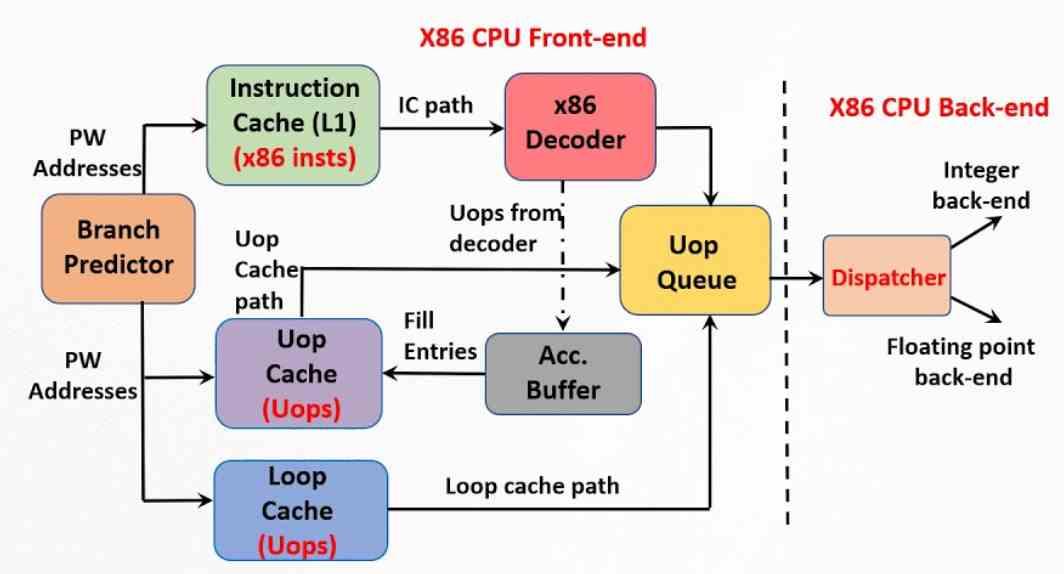
Den fungerer imidlertid som en cache, og innholdet endres over tid etter hvert som nye instruksjoner kommer. Når det er en ny instruksjon i instruksjonsbufferen på første nivå, søkes mikrooperasjonsbufferen hvis den allerede er dekodet. Hvis ikke, fortsett som vanlig.
De vanligste instruksjonene når de er dekomponert er vanligvis en del av mikrooperasjonsbufferen. Det som derimot fører til at færre kasseres, er at de som har sporadisk bruk vil være det oftere, for å gi rom for nye instruksjoner. Ideelt sett bør størrelsen på mikrooperasjonsbufferen være stor nok til å lagre dem alle, men den bør være liten nok til at søket i den ikke ender opp med å påvirke ytelsen til CPU.