Selv om BIG Navi med RDNA2-arkitektur og Navi 2x-brikkene ennå ikke har kommet på markedet som sådan, er sannheten at AMD (og i mindre grad NVIDIA) jobber allerede med å implementere etterfølgeren til dette (som ikke vil være HBM2E): HBM3 . Selv om vi ikke vet for mye om det i dag, har det blitt lekket en serie komparative data HBM2 det er ganske interessant og kan tippe resultatbalansen mellom de to selskapene, hvor mye er forbedringen?
Som vi vet, HBM2 og HBM2E er to typer VRAM med en rekke viktige begrensninger for implementering og utvikling for GPU chips. De har mange fordeler fra ytelse og forbruk, de er nåtiden av nødvendighet, men de vil ikke være fremtiden som sådan.
For dette ankommer HBM3, som innenfor det lille vi vet om det, vil avslutte problemene med de to tidligere versjonene. Inntil i dag visste vi ikke ytelsen, og fremfor alt hvor mye forbedring vi kan snakke om sammenlignet med versjonen den erstatter.

HBM2 vs HBM3: de første sammenligningene og prestasjonssimuleringene kommer
Som vi sier, de første dataene er allerede her, bortsett fra at de, som vanligvis skjer i disse tilfellene, ikke tilbys ved hjelp av båndbredde, FPS eller noen annen vanlig metrikk i spillsektoren.
Som et høyytelses TOP-minne er næringslivet interessert i å lære om forbedringer i forhold til HBM2 i et Eksascale servermiljø, som til slutt er verdensdominerende for sin enorme kraft. Derfor gjenspeiler dataene vi skal se denne situasjonen og fokuserer på å trekke konklusjoner for organisering, båndbredde, latenstid, kapasitet og makt.
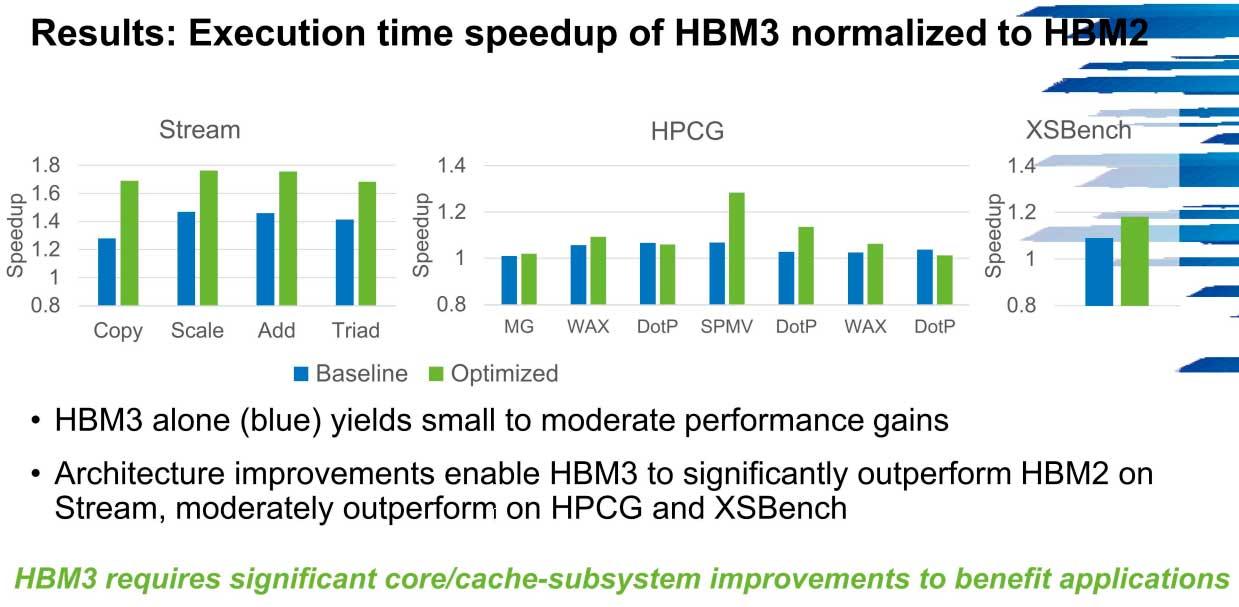
Spørsmålet er klart og sentralt: i hvilken grad vil fremtidige PCer dra nytte av HBM3 vs. HBM2? Dataene er ganske klare.
Som vi kan se, vil optimaliseringen av HBM3 være en mer enn viktig pilar i Exascale-systemer, og det er at det er mulig å oppnå opp til en 1.7x økning i hastighet i systemer over HBM2 med lite mer enn antall kjerner og delsystem-cacher.
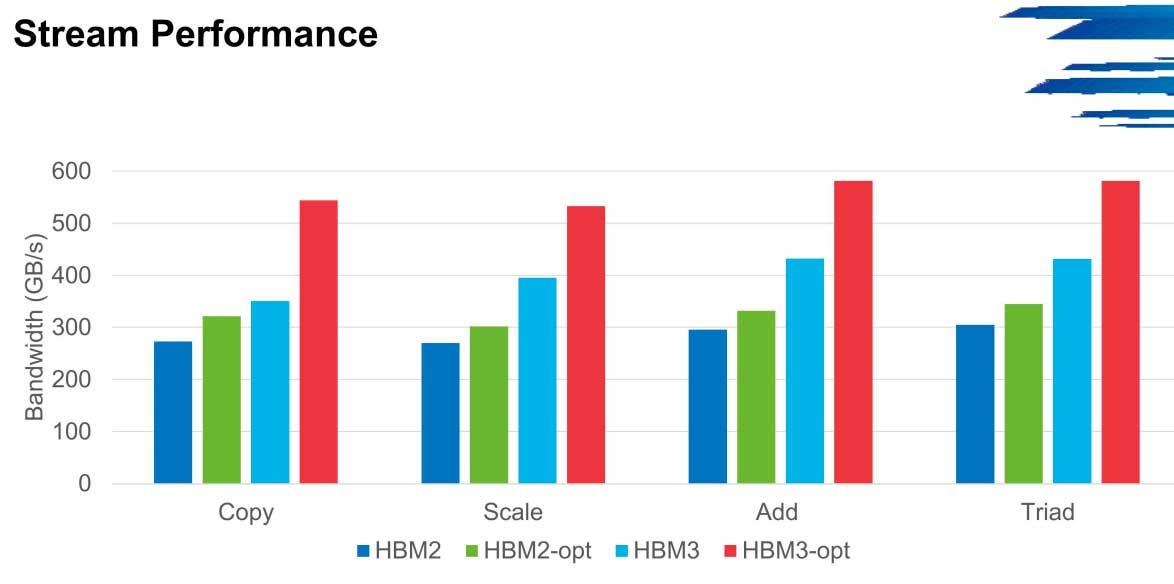
I HPCG kan ytelsen i båndbredde skyte opptil 600 GB / s i disse miljøene fra de 300 GB / s som de første versjonene starter med lave hastigheter, et scenario som gjentas for eksempel i Stream.
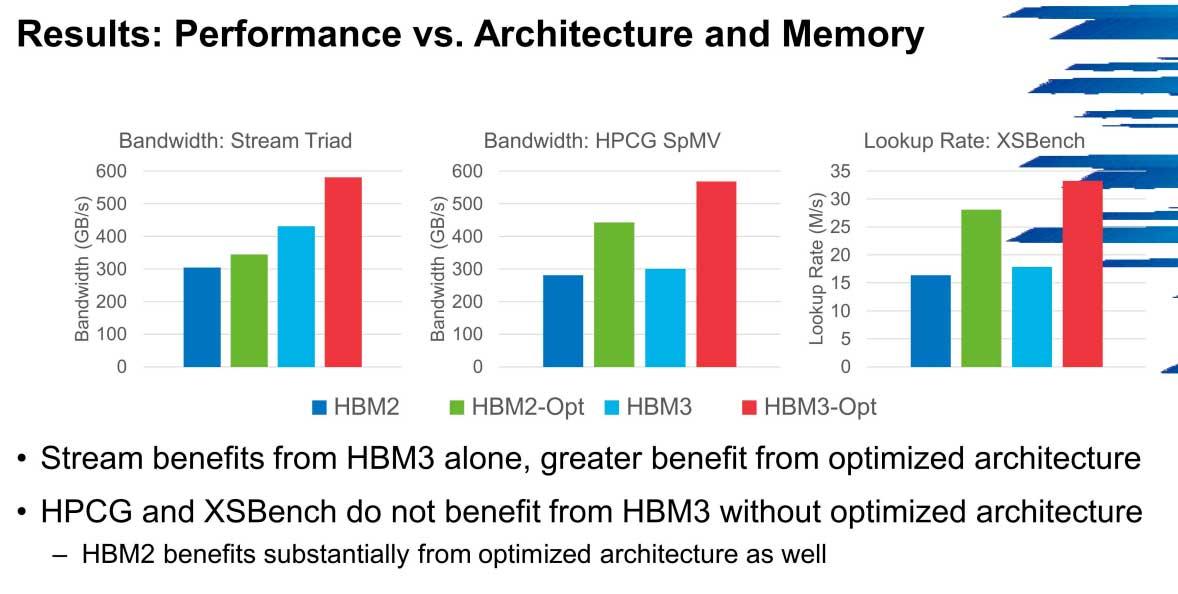
Hovedproblemet som HBM3 kommer til å dra er nettopp NoC-nettverkene, der båndbredden er en flaskehals. Klyngene vil ha en liten forbedring i disse tilfellene så lenge det ikke er en slik flaskehals, men det er ikke en type minne som ser ut til å være for optimal for systemer som ikke er nøyaktig optimalisert.
Antall tråder, typer og størrelser på hurtigbuffer samt kataloger er nøkkelen
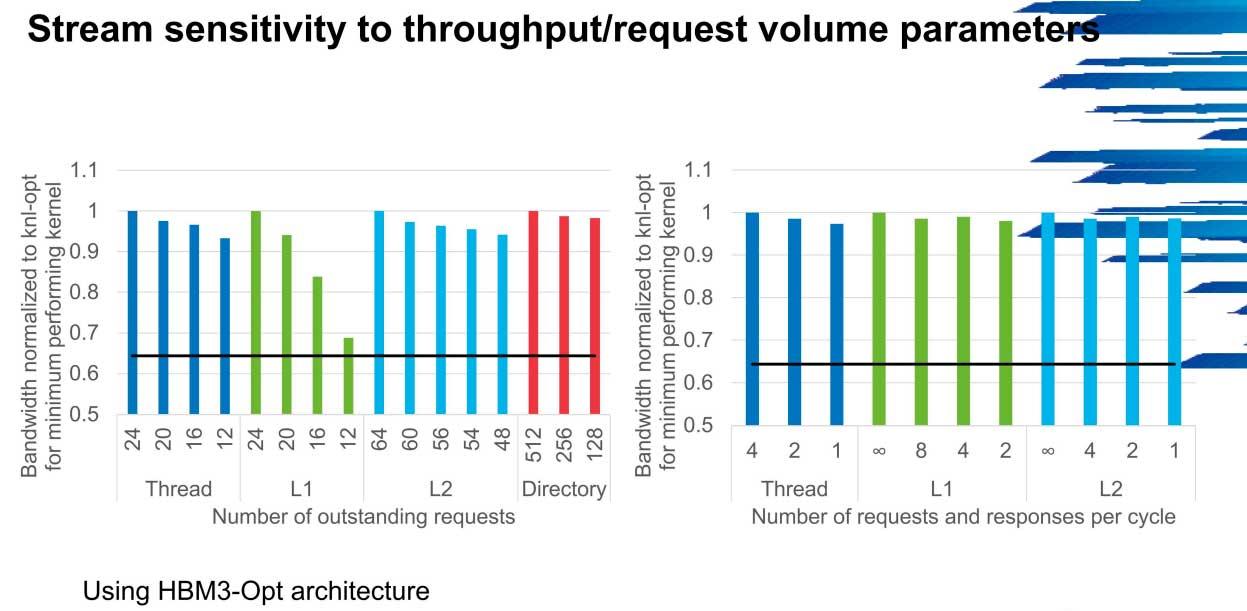
Frekvensen og antall kjerner har også mye å si, siden økningen i båndbredde går fra 1 til 2 GHz i 300 GB / s til 600 GB / s hvis nettverksfrekvensen er 5 GHz, noe som akkurat nå er utenfor rekkevidde av nesten alle servere i verden.
Det mest realistiske scenariet er en frekvens på 4 GHz, der det er et lite fall i driftsbåndbredden, spesielt i skala og kopi, men det er akseptabelt med tanke på dagens effekt.
Antall tråder, størrelse på L1- og L2-buffer, samt antall kataloger er også viktig, spesielt i L1-cache. Skalerbarhet er nesten 80% når man går fra 12 til 24, noe som ikke gjenspeiles i de andre parametrene, men indikerer viktigheten fremtidige arkitekturer vil ha på dette tidspunktet, noe AMD har jobbet med i noen tid og som Intel tok seg selv på alvor for et drøyt år siden.
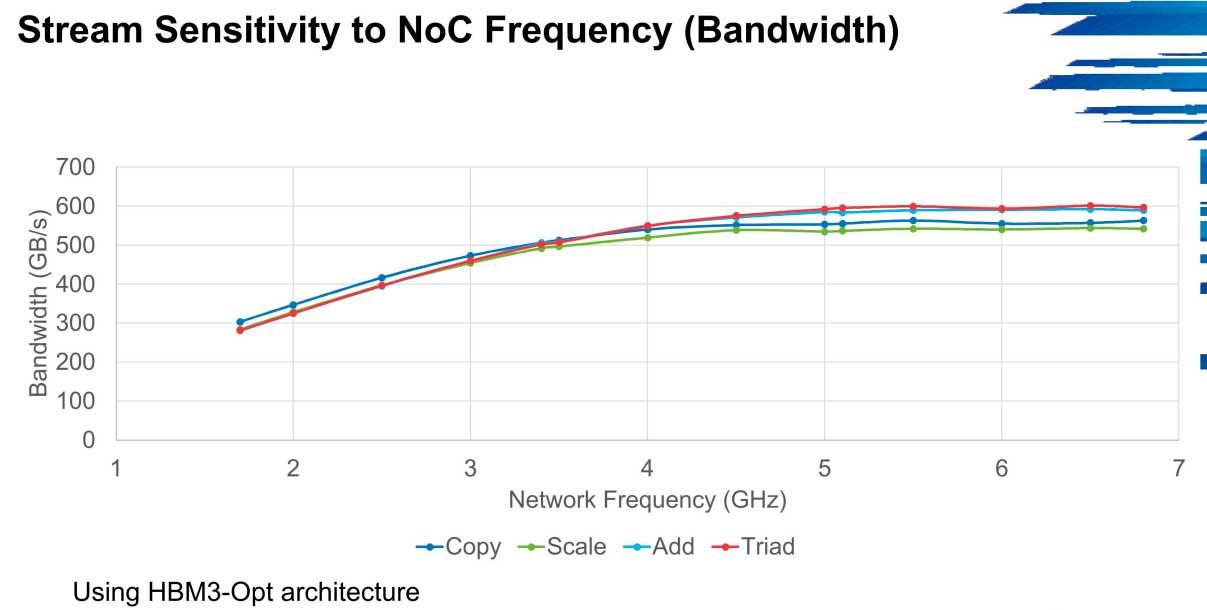
Kort oppsummert, HBM3 for servere er enormt avhengig av NoC-ressurser, vil en maksimal optimalisering være nødvendig for å dra full nytte av det når det gjelder båndbredde (mye mer når de øker sin endelige hastighet i JEDEC), og til syvende og sist er det et type minne som er veldig avhengig av skalerbarhet og ressurser.
I spill vil det igjen være et veldig dyrt minne med null fordeler, der det allerede har vært ved flere anledninger som ikke gir noen fordel ved høye oppløsninger og hertz. Det vil imidlertid sikkert bli brukt av AMD i sin high-end GPU når forbruket skyter opp og GDDR6 er ikke et alternativ på grunn av dens spenning, der vi bare håper at RDNA 2 vil være mer effektiv og dermed unngå implementering og kostnader på Lisa Su utstyr.
På den annen side har NVIDIA ingen overtoner av bruk av GPU Tesla og vil fokusere på GDDR6 minner 18 Gbps for å øke båndbredden mens de opprettholder det samlede forbruket av kortene deres, spesielt ved å utnytte nye noder 7 nm og 8 nm fra TSMC og Samsung.