
Så langt har normen i både PC-prosessorer og APU-er vært en homogen design i CPUer, noe som betyr at bruk av en enkelt type kjerne gjentas et visst antall ganger. Men bruken av heterogene konfigurasjoner med kjerner av ulik kompleksitet har begynt å vises på PC. Vi forklarer hva store og små kjerner er forskjellige i slike APUer og CPUer for PC
Ankomsten av CPUer og APUer til PC-er som bruker heterogene kjerner og derfor kjerner av ulik kompleksitet og størrelse er et faktum. Men hvordan skiller disse heterogene kjernene seg i natur og ytelse? Det er spørsmålet som mange stiller seg når de leser om de forskjellige arkitekturene som dukker opp på markedet. Hvorfor etter mer enn et tiår å bruke en enkelt type kjerne har spranget til bruk av store og små kjerner i CPUer.
Hvorfor bruk av forskjellige typer kjerner?

Det er flere grunner til dette, den mest kjente er den som har blitt brukt i det nå klassiske big. LITTLE CPUer for smarttelefoner, der to samlinger av kjerner med forskjellig strøm og forbruk blir byttet i bruk i henhold til type applikasjoner i henhold til til arbeidsmengden på smarttelefonen til enhver tid. Dette ble gjort for å øke batterilevetiden til slike enheter.
I dag har dette konseptet utviklet seg, og det er allerede mulig å bruke begge typer kjerner samtidig og ikke på en byttet måte. Så den kombinerte designen er ikke lenger basert på å spare energi, men på å oppnå høyest mulig ytelse. Det er her vi kommer inn på to forskjellige måter å forstå ytelse på, avhengig av hvordan heterogene kjerner brukes.
Den mest brukte av dem, fordi den er enklest å implementere, består i å tilordne de letteste trådene når det gjelder arbeidsbelastning til kjernene med minst mulig kraft, en oppgave som operativsystemet må utføre. Som er programvaren som har ansvaret for å administrere bruken av maskinvareressurser inkludert GPU. Denne måten å jobbe på er den samme som Intel Lakefield og dets fremtidige arkitekturer som Alder Lake, så vel som ARM kjerner med DynamiQ.
Uansett hva det er, er organisasjonen basert på bruk av to kjerner med samme sett med registre og instruksjoner, men med forskjellige spesifikasjoner. Hva er forskjellene mellom de forskjellige heterogene kjernene? La oss se.
Store kjerner vs. små kjerner i dag

Først av alt, la oss komme inn i det åpenbare, den første forskjellen mellom de to typer kjerner er i størrelse. Siden store kjerner er mer komplekse enn små kjerner, har de en mer kompleks struktur og består derfor av et større antall transistorer. Ergo er større enn små kjerner som har en mye enklere struktur. Dette betyr at innenfor chipområdet kan vi inkludere flere Little cores i chip space enn Big cores.
For alt dette er det første du vil spørre deg selv: hva er ytelsesfordelen når du bruker de to typer kjerner? Vi må huske på at på PC-en i dag, på PC-ene våre, kjører flere applikasjoner samtidig, hver utfører flere tråder for kjøring. Hva faktumet med å legge til et større antall kjerner, selv om det er basert på å gjøre det med kjerner lettere i kraft, ender opp med å legge til den totale ytelsen.
I virkeligheten er de mindre kjernene bare en måte å lette arbeidet til de større og mer komplekse kjernene, og ta bort arbeidet å gjøre. Ikke bare det, men til og med ytterligere kjerner kan brukes til å håndtere de vanligste forstyrrelsene i de forskjellige perifere enhetene, slik at resten av kjernene ikke trenger å stoppe driften når som helst for å kunne delta på dem kontinuerlig og til enhver tid. .
Fremtidens arkitekturer går gjennom heterogene konfigurasjoner
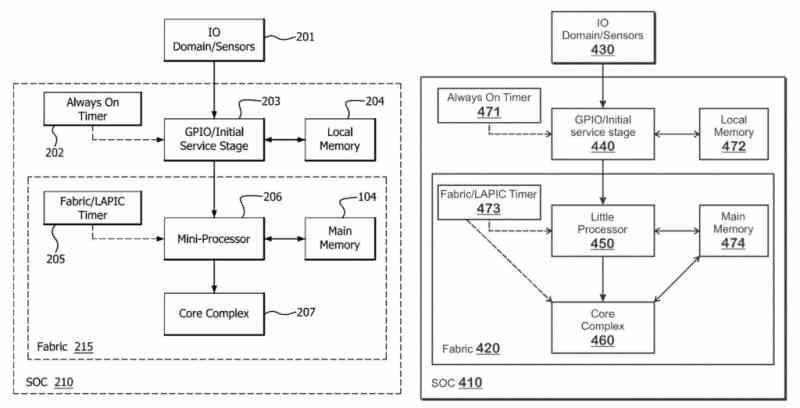
Den andre metoden er mer kompleks for å implementere store og små kjerner er forskjellig fra den forrige, siden den består i å dele settet med registre og instruksjoner fra ISA og gjenta det i to klasser av kjerner. Årsaken er at ikke alle instruksjonene har det samme energiforbruket, men det enkleste vil alltid konsumere mer i de mer komplekse kjernene. Så ideen er ikke å distribuere kjøringstrådene til deres tilsvarende kjerne, men heller at kjøringen av en enkelt kjøringstråd deles mellom to eller flere kjerner på en sammenflettet måte.
Derfor er implementeringen mye mer kompleks enn den gjeldende modellen, siden de forskjellige kjernene som har ansvaret for den samme utførelsestråden må ha den nødvendige maskinvaren for å koordinere når de kjører programmene. Fordelen med dette paradigmet er at det i prinsippet ikke krever operativsystemets arbeid for å administrere de forskjellige trådene som prosessor må utføre. Men i dette tilfellet, som vi allerede har kommentert, avhenger delingen av heterogene kjernetyper av hvordan instruksjonssettet fordeles mellom begge kjernene.
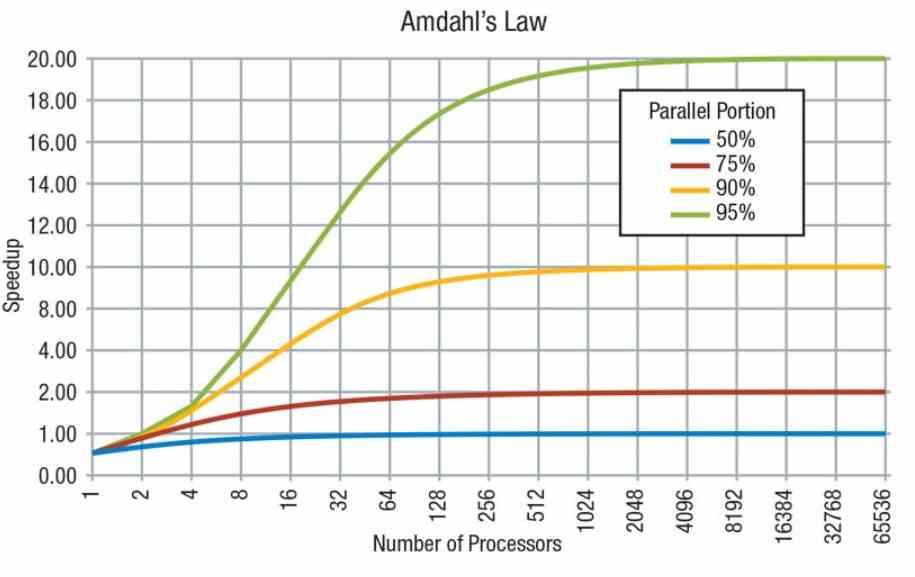
Driften av denne metoden har å gjøre med den såkalte Amdahls lov og måten programmene skalerer på ytelse. På den ene siden har vi sekvensielle deler som ikke kan fordeles mellom flere kjerner, da de ikke kan utføres parallelt og på de andre delene som kan. I det første tilfellet vil kraften ikke avhenge av antall kjerner, men av kraften til hver kjerne, mens den andre vil avhenge av hver kjerne.
Tradisjonelt er de mest komplekse instruksjonene i en CPU implementert fra en rekke enklere instruksjoner for å dra nytte av maskinvaren mye bedre. Men de nye fabrikasjonsnodene vil tillate at mer komplekse instruksjoner kobles direkte til de mer komplekse kjernene, i stedet for å være en sammensetning av flere kjerner. Dette vil også tjene til å øke den generelle ytelsen til programmene, siden det tar mye mindre tid å utføre når disse instruksjonene utføres.