Een van de belangrijkste concepten om de architectuur en prestaties van de huidige Intel en AMD CPU's is het concept van microoperaties, evenals eenheden zoals hun cache. In dit artikel zullen we u op een toegankelijke manier vertellen wat ze zijn en waarom de huidige processors al hun operaties daarop baseren om de maximaal mogelijke prestaties te bereiken.
A CPU tegenwoordig kan een groot aantal verschillende instructies worden uitgevoerd, en dit met frequenties die tot 5,000 keer hoger zijn dan die van vroege personal computers. We hebben de neiging om en volledig ten onrechte te denken dat de grotere hoeveelheid MHz of GHz te wijten is aan de nieuwe fabricage. De realiteit is heel anders, en dit is waar micro-operaties van pas komen, die de sleutel zijn tot het bereiken van de enorme rekenkracht van de huidige microprocessors.

Wat zijn micro-operaties?
Een van de vergelijkingen met de werkelijkheid die meestal worden gebruikt om uit te leggen wat een programma is, is de vergelijking met een kookrecept. Waarin we in een werkwoord een reeks acties kunnen zien die we moeten uitvoeren. Ik kan bijvoorbeeld een recept ingeven dat je een stuk vlees in de pan bakt, maar voor jou zal het toch even zoeken naar de pan blijken te zijn, doe hetzelfde met de olie, doe die laatste in de pan, wacht zodat het heet is en leg het stuk vlees erin. Zoals je kunt zien, hebben we iets dat in principe wordt gedefinieerd door een enkel werkwoord omgezet in een reeks acties.
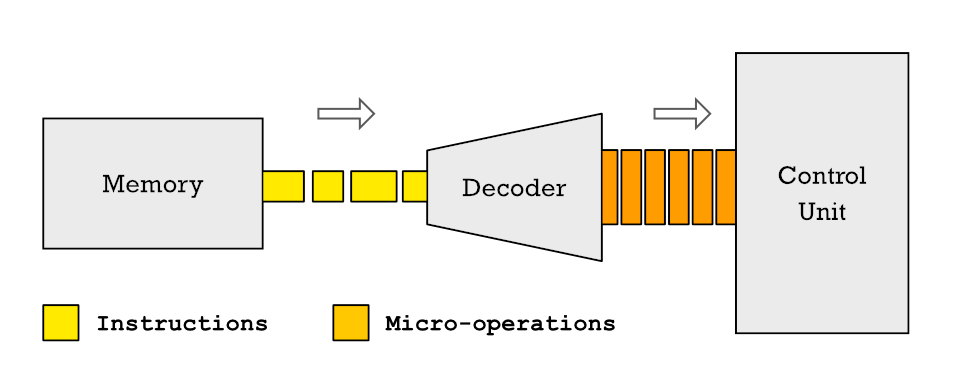
Welnu, de instructies van een CPU kunnen worden opgesplitst in kleinere die we microoperaties noemen. En waarom geen micro-instructies? Welnu, vanwege het feit dat een instructie, gewoon door hem in verschillende cycli te segmenteren voor uitvoering, meerdere klokcycli nodig heeft om op te lossen. Een microoperatie daarentegen duurt een enkele klokcyclus.
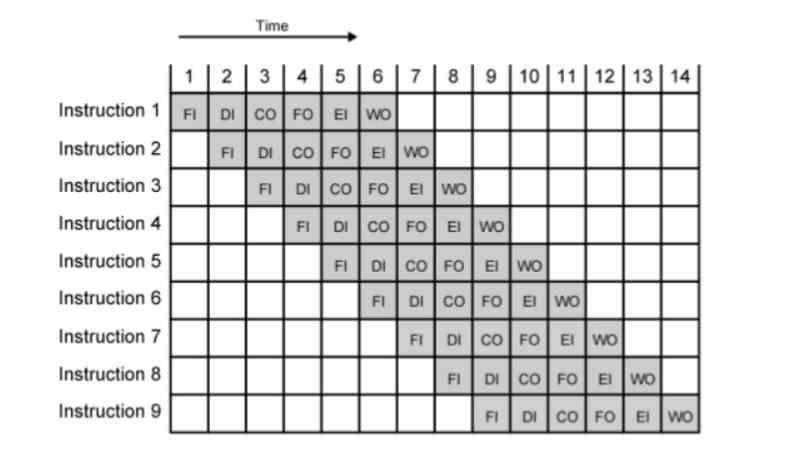
Een manier om de meeste MHz of GHz te krijgen, is pipelining, waarbij elke instructie wordt uitgevoerd in verschillende fasen die elk één klokcyclus duren. Omdat frequentie het omgekeerde van tijd is, moeten we de tijd verkorten om meer frequentie te krijgen. Het probleem is dat het punt wordt bereikt waarop een instructie niet meer kan worden ontleed, het aantal fasen in de pijplijn kort wordt en dus de te behalen kloksnelheid laag is.
Deze werden eigenlijk geboren met het verschijnen van de out-of-order uitvoering van de Intel P6-architectuur en zijn afgeleide CPU's zoals de Pentium II en III. De reden hiervoor is dat de segmentatie van de P5 of Pentium ze slechts toestond om iets meer dan 200 MHz te bereiken. Met de microbewerkingen, door het aantal fasen van elke instructie nog meer te verlengen, overtroffen ze de GHz-barrière met de Pentium 3 en waren ze in staat om 16 keer hogere kloksnelheden te hebben met de Pentium 4. Sindsdien worden ze gebruikt in alle CPU's met out-of-order uitvoering, ongeacht merk en register en instructieset.
Je CPU's zijn noch x86, noch RISC-V, noch ARM
In huidige CPU's worden, wanneer instructies bij de CPU-besturingseenheid aankomen om te worden gedecodeerd en toegewezen aan de besturingseenheid, ze eerst opgesplitst in verschillende microbewerkingen. Dit betekent dat elke instructie die de processor uitvoert, bestaat uit een reeks basismicrobewerkingen en de reeks ervan in een geordende stroom wordt microcode genoemd.

De ontleding van instructies in micro-operaties en de transformatie van programma's die zijn opgeslagen in RAM in microcode wordt tegenwoordig in alle processors aangetroffen. Dus als je telefoon ISA is ARM CPU of de x86 CPU van uw pc voert programma's uit, de uitvoeringseenheden lossen geen instructies op met die sets registers en instructies.
Dit proces heeft niet alleen de voordelen die we in de vorige sectie hebben uitgelegd, maar we kunnen ook instructies vinden die, zelfs binnen dezelfde architectuur en onder dezelfde set registers en instructies, anders zijn onderverdeeld en de programma's volledig compatibel zijn. Het idee is vaak om het aantal benodigde klokcycli te verminderen, maar meestal is het om de strijd te vermijden die optreedt wanneer er meerdere verzoeken zijn aan dezelfde bron binnen de processor.
Wat is de micro-op-cache?
Het andere belangrijke element om de maximaal mogelijke prestaties te bereiken, is de cache voor micro-operaties, die later is dan de micro-operaties en dus dichterbij in de tijd. De oorsprong ervan is te vinden in de trace-cache die Intel in de Pentium 4 heeft geïmplementeerd. Het is een uitbreiding van de cache van het eerste niveau voor instructies die de correlatie opslaat tussen de verschillende instructies en de microbewerkingen waarin ze eerder zijn gedemonteerd door de besturingseenheid .

De x86 ISA heeft echter altijd een probleem gehad met het RISC-type, terwijl deze laatste een vaste instructielengte in de code hebben, in het geval van de x86 kan elk tussen de 1 en 15 bytes meten. We moeten in gedachten houden dat elke instructie wordt opgehaald en gedecodeerd in verschillende micro-operaties. Hiervoor is tot op de dag van vandaag een zeer complexe besturingseenheid nodig die zonder de nodige optimalisaties tot een derde van zijn energie kan verbruiken.
De micro-operatiecache is dus een evolutie van de tracecache, maar maakt geen deel uit van de instructiecache, het is een hardware-onafhankelijke entiteit. In een microoperatiecache is de grootte van elk ervan vastgelegd in termen van het aantal bytes, waardoor bijvoorbeeld een CPU met ISA x86 zo dicht mogelijk bij een RISC-type kan werken en de complexiteit van de besturingseenheid en daarmee consumptie. Het verschil met de Pentium 4-plotcache is dat de huidige micro-op-cache alle micro-ops die bij een instructie horen op één regel opslaat.
Hoe werkt het?
Wat de cache voor microbewerkingen doet, is het werk van het decoderen van de instructies vermijden, dus wanneer de decoder zojuist genoemde taak heeft uitgevoerd, slaat hij het resultaat van zijn werk op in genoemde cache. Op deze manier, wanneer het nodig is om de volgende instructie te decoderen, wordt er gezocht of de microbewerkingen die deze instructie vormen zich in de cache bevinden. De motivatie om dit te doen is niets anders dan het feit dat het minder tijd kost om de cache te raadplegen dan om een complexe instructie niet te ontleden.
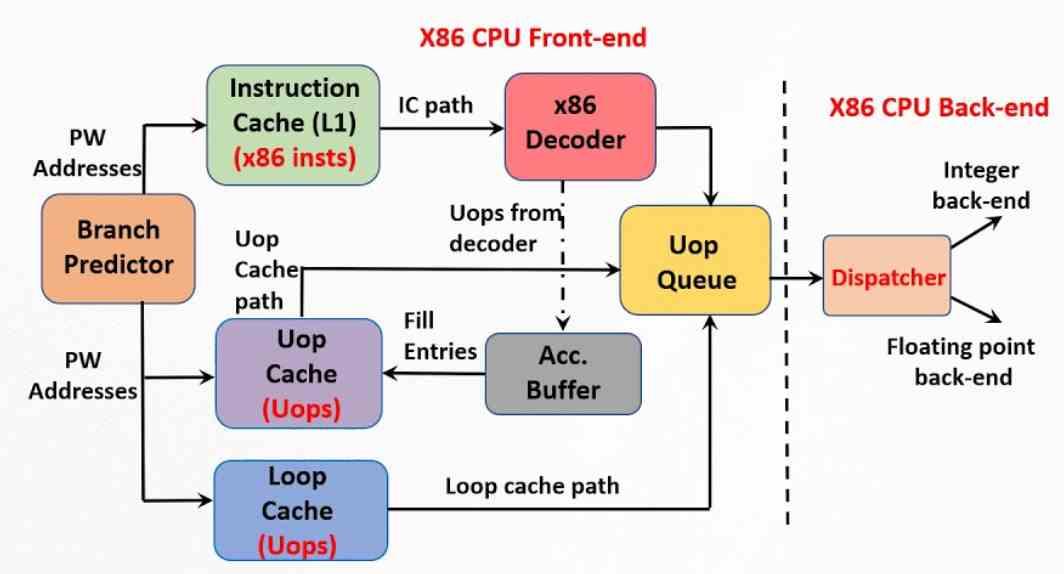
Het werkt echter als een cache en de inhoud wordt in de loop van de tijd verschoven als er nieuwe instructies binnenkomen. Wanneer er een nieuwe instructie is in de instructiecache van het eerste niveau, wordt de micro-operatiecache doorzocht als deze al is gedecodeerd. Zo niet, ga dan verder zoals gewoonlijk.
De meest voorkomende instructies die eenmaal zijn ontleed, maken meestal deel uit van de cache voor microbewerkingen. Wat er echter voor zorgt dat er minder worden weggegooid, is dat degenen die sporadisch worden gebruikt, vaker zullen zijn, om ruimte te laten voor nieuwe instructies. Idealiter zou de grootte van de microoperatiecache groot genoeg moeten zijn om ze allemaal op te slaan, maar het zou klein genoeg moeten zijn zodat het zoeken erin de prestaties van de CPU niet beïnvloedt.