de val van Facebook wereldwijd dat op maandag plaatsvond, was een voor en na in het bedrijf, en het is dat ze meer dan 5 uur volledig waren losgekoppeld van internet, iets ongekends voor een van de grootste bedrijven ter wereld. Nu het Facebook-platform, WhatsApp en Instagram 100% zijn hersteld van de crash die maandag plaatsvond, heeft het Facebook-team details gepubliceerd over hoe de crash is gebeurd, waarom het is gebeurd en ook hoe ze het hebben opgelost. Wil je alle details weten over de grootste crash in de geschiedenis van Facebook tot nu toe?

Hoe werkt Facebook en waarom vond de totale ondergang plaats?
Facebook heeft aangegeven dat de totale onderbreking van de dienstverlening wereldwijd te wijten was aan een storing van het systeem dat de capaciteit van de backbone van het bedrijf beheert. over de hele wereld, die bestaat uit duizenden servers en honderden kilometers glasvezel, omdat ze ook haar datacenters verbinden met onderzeese kabels. Sommige datacenters van Facebook hebben miljoenen servers die de gegevens opslaan en hebben een hoge rekenbelasting, maar in andere gevallen zijn de faciliteiten kleiner en zijn ze verantwoordelijk voor het verbinden van de ruggengraat met internet in het algemeen zodat mensen hun platforms kunnen gebruiken.
Wanneer een gebruiker zoals wij verbinding maakt met Facebook of Instagram, gaat het verzoek om gegevens van ons apparaat naar de dichtstbijzijnde faciliteit geografisch, om later rechtstreeks met de backbone te communiceren om toegang te krijgen tot de grootste datacenters, dit is waar het de gevraagde informatie ophaalt en wordt verwerkt, zodat we het op de smartphone kunnen zien.

Al het dataverkeer tussen de verschillende datacenters wordt beheerd door routers, die bepalen waar inkomende en uitgaande data naartoe gestuurd moeten worden. Als onderdeel van hun dagelijkse werk moet het technische team van Facebook deze infrastructuur onderhouden en taken uitvoeren zoals het upgraden van routers, het repareren van glasvezellijnen of het toevoegen van meer capaciteit op bepaalde netwerken. Dit was het probleem met de wereldwijde Facebook-crash op maandag.
Tijdens onderhoudswerkzaamheden werd een opdracht verzonden met de bedoeling de beschikbaarheid van de wereldwijde backbone-capaciteit te evalueren, maar deze verbrak per ongeluk alle backbone-verbindingen, waardoor alle Facebook-datacenters wereldwijd werden losgekoppeld. Over het algemeen gebruikt Facebook systemen om dit soort opdrachten te controleren en dergelijke fouten te verminderen of te voorkomen, maar een fout (bug) in deze controle- en wijzigingscontroletool verhinderde dat de uitvoering van de bestelling werd gestopt, en toen viel alles uit elkaar.
Wat gebeurde er op Facebook toen ik de opdracht uitvoerde?
Zodra de opdracht werd uitgevoerd, veroorzaakte dit een totale verbreking van de internet- en datacenterverbindingen, dat wil zeggen dat we geen toegang hadden tot de Facebook-services omdat ze niet langer zichtbaar waren op internet. Bovendien veroorzaakte deze totale ontkoppeling een tweede catastrofale storing in het systeem, meer bepaald in de DNS. Een van de taken die kleinere datacenterinstallaties uitvoeren, is het beantwoorden van DNS-query's. Deze query's worden beantwoord door gezaghebbende naamservers met bekende IP-adressen en die via het protocol BGP aan de rest van het internet worden geadverteerd.
Om een betrouwbaardere werking te garanderen, laat Facebook de DNS-servers die BGP-advertenties uitschakelen als ze zelf niet met de datacenters van Facebook kunnen praten, omdat dit aangeeft dat de netwerkverbinding niet goed werkt. Met de totale verstoring van de backbone, hebben deze DNS-servers de BGP-advertenties verwijderd. Het resultaat hiervan is dat de DNS-servers van Facebook onbereikbaar werden, hoewel ze perfect werkten, om deze reden had de rest van de wereld geen toegang tot Facebook-services.
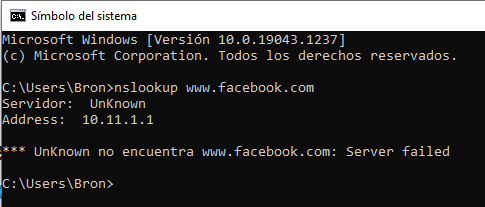
Logischerwijs was dit hele proces in een kwestie van seconden, terwijl Facebook-technici probeerden uit te zoeken wat er gebeurde en waarom, ze werden geconfronteerd met twee kritieke problemen:
- Het was niet mogelijk om normaal toegang te krijgen tot de datacenters, omdat de netwerken vanaf het eerste probleem volledig uit de lucht waren.
- De crash van DNS brak veel interne tools die vaak worden gebruikt om dit soort problemen te onderzoeken en op te lossen.
De toegang tot het hoofdnetwerk en het out-of-band netwerk waren niet beschikbaar, niets werkte, dus moesten ze fysiek een team mensen naar het datacenter sturen om het probleem op te lossen en het systeem opnieuw op te starten. Dit heeft lang geduurd omdat de fysieke beveiliging in deze centra maximaal is, sterker nog, zoals bevestigd door Facebook, is het zelfs moeilijk voor hen om fysiek toegang te krijgen tot deze centra om wijzigingen aan te brengen, om mogelijke fysieke aanvallen op hun netwerk te voorkomen of te beperken. Dit duurde lang voordat ze zich konden verifiëren bij het systeem en konden zien wat er aan de hand was.
Weer tot leven komen … maar beetje bij beetje om niet het hele systeem weg te gooien
Nadat de backbone-connectiviteit was hersteld in de verschillende regio's van de datacenters van Facebook, werkte alles weer goed, maar niet voor gebruikers. Om te voorkomen dat hun systemen zouden instorten vanwege het enorme aantal gebruikers dat binnen wilde komen, moesten ze de diensten heel beetje bij beetje activeren om te voorkomen dat ze nieuwe problemen veroorzaakten door de exponentiële toename van het verkeer.
Een van de problemen is dat de afzonderlijke datacenters heel weinig stroom verbruikten, waardoor het elektriciteitsnet plotseling niet in staat zou zijn om zoveel extra stroom op te nemen en dat elektrische systemen in gevaar zouden kunnen komen als plotseling al het verkeer werd omgekeerd. Ik heb ze gecached. Facebook heeft getraind voor dit soort evenementen, dus ze wisten heel goed wat ze moesten doen om meer problemen te voorkomen in het geval van een wereldwijde crash zoals die is gebeurd. Hoewel Facebook veel problemen en crashes van hun servers en netwerken had gesimuleerd, hadden ze nooit een totale daling van de ruggengraat overwogen, dus ze hebben al aangegeven dat ze op korte termijn zullen zoeken naar een manier om dit te simuleren om te voorkomen dat het komt rug. voorbij en het duurt zo lang om te repareren.
Facebook heeft ook aangegeven dat het erg interessant was om te zien hoe fysieke beveiligingsmaatregelen om ongeautoriseerde toegang te voorkomen, ervoor zorgden dat de toegang tot servers enorm vertraagde terwijl ze wereldwijd probeerden te herstellen van deze storing. In ieder geval is het beter om je dagelijks te beschermen tegen dit soort problemen en een wat trager herstel te hebben, dan de beveiligingsmaatregelen van de datacenters te versoepelen.