이기는하지만 AMD 이와 관련하여 공식적인 내용을 명시하지 않았거나 RDNA2 건축과 같은 개선을 위해, 우리는 그것이 특정 단위를 도입하는 두려운 작업을 어떻게 달성 할 것인지에 대한 아이디어를 가지고 있습니다. 광선 추적 GPU에서. 이것은 콘솔의 iGPU로 확장 될 것이므로 모든 부문이 공유하는 참신함에 직면하고 있지만 어떻게 할 것인가?
그것이 일어난 것처럼 NVIDIA, AMD는 현재 아키텍처의 순수한 제한으로 인해 Ray Tracing 기술에 대한 하이브리드 접근 방식을 수행해야합니다. 즉, 실시간으로 레이아웃 광선에 생명을 불어 넣으려면 텍스처 프로세서에 다시 의존해야합니다.

따라서 BVH 알고리즘은 NVIDIA와 매우 유사한 고정 기능 유닛을 통해 새로운 RDNA 2 아키텍처가 제공 할 성능을 아는 데 핵심적인 역할을합니다. 그럼에도 불구하고 AMD는 구현 방식이 다르기 때문에 Huang을 복사한다고 말할 수는 없지만 개념은 형태면에서 비슷합니다.
셰이더는 고정 장치의 성능에 핵심적 역할을합니다
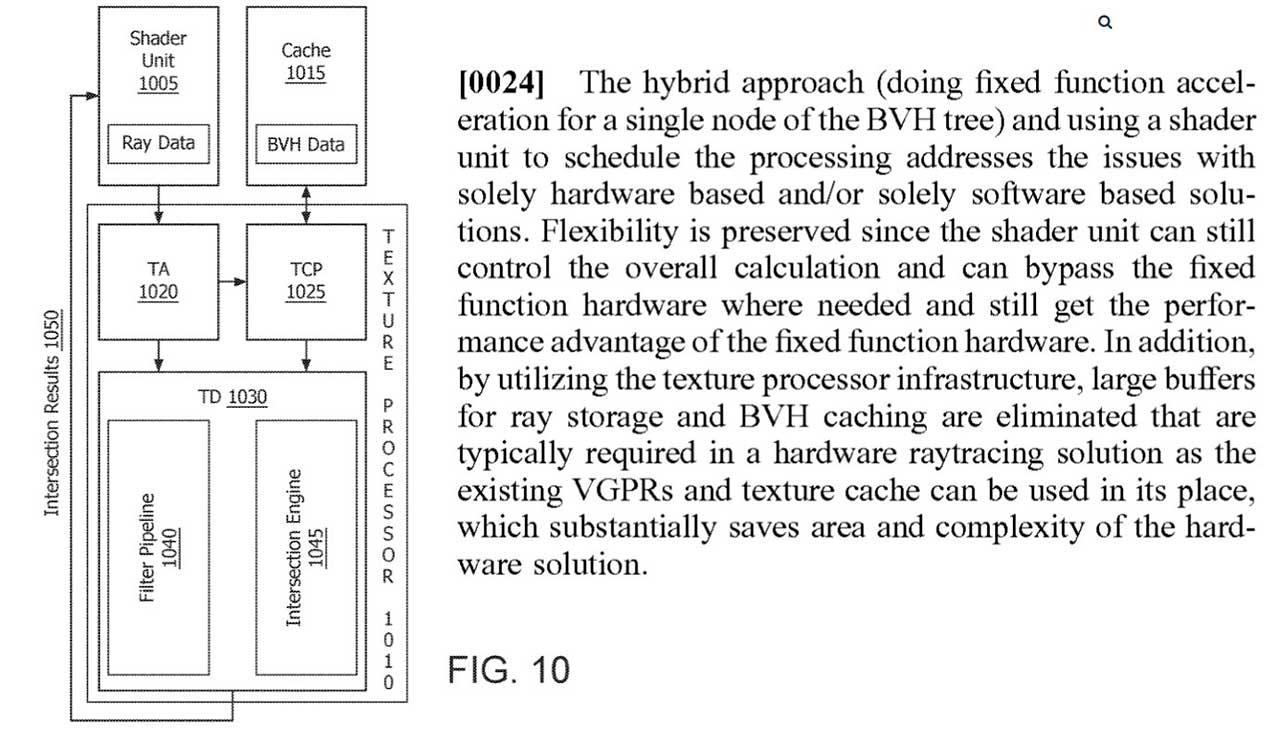
NVIDIA의 경우 RT Cores라는 고정 기능 단위에 대해 많이 이야기 했으므로 AMD는 자체적으로 동일한 기능을 수행합니다. “고정 기능 광선 교차 엔진” 고정 함수로서 광선의 교차 엔진과 같은 것입니다.
실제로이 이름 뒤에 BVS 알고리즘을 전문으로하는 일부 하드웨어 장치 (파스칼에서와 같은 소프트웨어를 통해 동일한 그래픽 출력에서 Turing에 대한 결과를 이미 보았 음)가 있지만 동시에 NVIDIA 옵션과 같이 복잡합니다.
AMD의 아이디어는 텍스처 시스템의 현재 메모리 버퍼를 사용하여 광선 추적 특정 데이터의 스토리지 의존성을 줄이는 것입니다. 여기에는 두 가지 긍정적 인 요소가 있습니다. 칩 영역이 확대되지 않고 동시에 아키텍처를위한보다 단순한 디자인입니다.
추가 하드웨어 스케줄러가 없으면 Ray Tracing에 대한 AMD의 접근 방식이 최적입니까?
현재 명확하지 않은 RDNA 2077에서 Cyberpunk 2을 시연했다는 소문이 있습니다. GPU 대 RTX 2080 슈퍼 레이 트레이싱에서 AMD 옵션이 훨씬 빠릅니다. 물론,이 정보를 핀셋으로 가져 가면 소문 일뿐입니다.
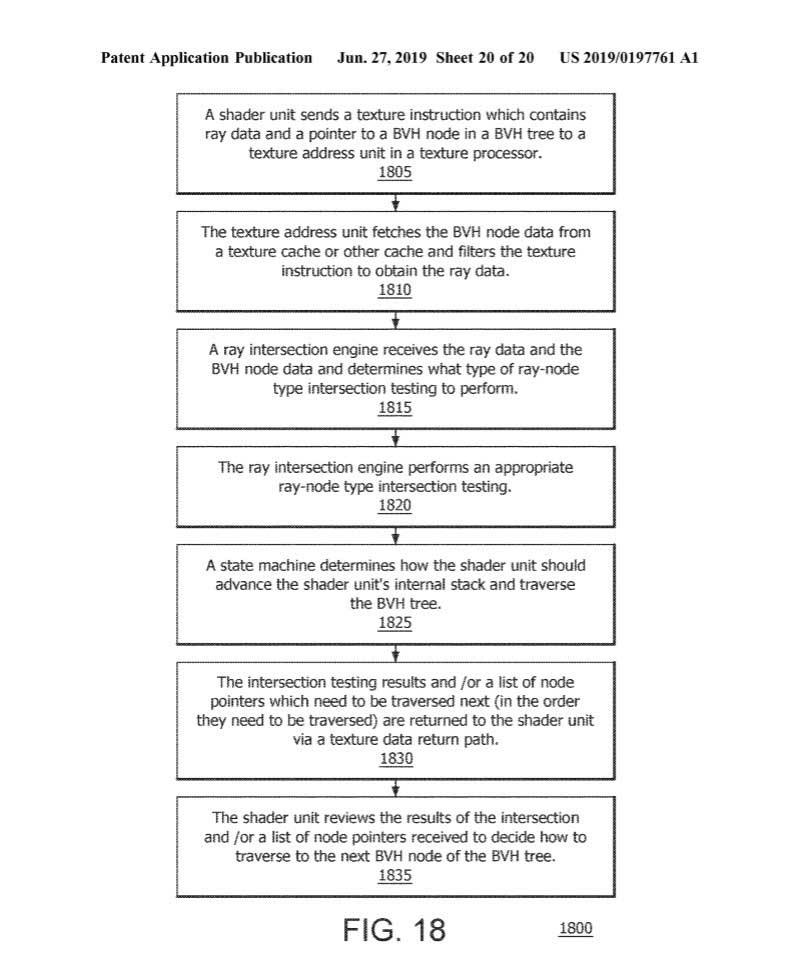
어쨌든 모든 것이 AMD의 접근 방식이 쉐이더가 광선 추적 데이터를 텍스처 파이프 라인으로 전송하여 고정 교차 모터가 처리하도록하는 것으로 나타납니다. 이것이 종이에 무엇을 의미합니까? 이론적으로, 초당 더 많은 교차점이 처리되고 이러한 계산을 수행하는 데 더 적은 클럭 사이클이 필요하므로 성능이 향상됩니다.
이를 위해 아키텍처에는 일련의 단위가 있습니다. 셰이더, 텍스처 프로세서 또는 TP, 더 큰 캐시 그리고 무엇보다도 상호 연결 번개 교차로 모터와 이들 중. 요약하면, AMD의 시스템은 개발자의 NVIDIA보다 훨씬 간단합니다. Huang의 경우 프로그래머는 적어도 두 개의 다른 엔진을 사용해야합니다. (쉐이더 + RT) . 대신, AMD는 새로운 교차 모터 만 참신한 많은 장치와 버스를 재사용합니다.
플롯을 활용하여 동일한 캐시에 저장된 계산을 수행하고 프로그래머가 작동 할 수있는 드라이브 및 경로에 전원을 공급하여 성능을 최적화하고 소비를 줄이며 더 큰 칩을 만들 필요가 없습니다.
종이에 작동하는 두 가지 하이브리드 접근법이 있습니다. 우리는 둘 다 기다려야합니다. RDNA2 과 암페어 어떤 기술이 가장 최적인지 알아보기 위해 시장에 나와야합니다.