長く語られていることのXNUMXつは、 のパフォーマンスが悪い AMD レイ トレーシングのグラフィックス カード 、特に比較して NVIDIAの。 しかし、Radeon Technology Groupによる必要なハードウェアの実装が非常に貧弱で、文字通りこのテクノロジーの採用をボイコットしているように見えると言うと、多くの人が手を挙げます. これは、コンピューター グラフィックスの特定の視覚的問題を解決するのに理想的であり、GeForce メーカーの発明でもないことを思い出してください。
私たちにとって、グラフィックス カードの主な機能は、ビデオ編集や 3D の作成など、より専門的なタスクに必要な場合に、ゲームを簡単かつ高性能にプレイできるようにすることです。モデル、それで十分です。 彼の作品で。 AMD のレイ トレーシングのパフォーマンスがほとんどないと私たちが言うとき、私たちは NVIDIA を屋根の上に置いているわけではありません。

レイ トレーシング アルゴリズム
レイ トレーシングにおける AMD カードのパフォーマンスの低さを理解するには、これが実際には完全なシーンを生成するための再帰アルゴリズムであることを理解する必要があります。最も単純なバージョンでは、次のように要約できます。
- シーン内の各ピクセル
- 可視光線を計算する
- 雷が物体に落ちた場合は、物体の色を評価します。
- そうでない場合、そのピクセルには背景色があります。
- 可視光線を計算する
光線は、カメラから移動し、シーンを「記録」し、ポイントまたはメッシュのマトリックスを横切るベクトルにすぎません。これらの各ポイントはピクセルです。 そのたびにシーンにチェックエフェクトがかかります。 フル HD のシーンがある場合、これは 2 万回のチェックを実行する必要があることを意味します。ゲームが 60 FPS の場合、これは 120 秒あたり XNUMX 億 XNUMX 万回のチェックです。
数学的には、それをチェックするための最も一般的な式は単純な演算ではなく、ベクトルを含む複雑な方程式であり、ある程度の力が必要です。 このタスクの実行を担当する並列ユニットがないという単純な事実だけで、パーセンテージ パフォーマンスが XNUMX 桁の数字にまで低下する可能性があります。
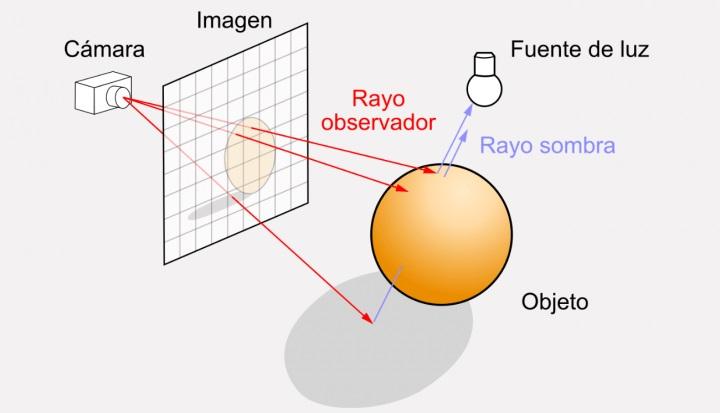
ハードウェア交差ユニット
そのため、NVIDIA には RT コアがあり、AMD にはレイ アクセラレータ ユニットがあります。これらは同じタイプのユニットであり、同じタスクに使用されるため、同じです。 ただし、前世代の RX 6000 には制限がありましたが、幸いにも RTG が RDNA 3 で解決し、その結果、RX 7000 の範囲で解決されました。

では、何が問題なのですか?
- RDNA 2 に欠けていたものが RDNA 3 に含まれるようになったことは、良いことであり、したがってポジティブなことです。
- AMD でレイ トレーシングのパフォーマンスが低下する原因は、次のとおりです。 光線と三角形の相互作用の量 計算できるということです。 競合他社のパフォーマンスが世代間で 50 倍になった場合、わずか XNUMX% のジャンプは非常に貧弱です。
市場に登場した最初の 3D カードは、この点で最も一般的な三角形のラスタライズの操作をますます高速化したことを忘れないでください。 この部分はレイトレーシングでも同じです。 したがって、AMD がこの点でこのような小さな飛躍を遂げたという事実は残念です。
全体的なパフォーマンスにどのように影響しますか?
光線の交差はセットの一部ではありますが、すべてのシーンに共通する重要な要素です。 XNUMXつが通常よりも遅くなると、その後のパフォーマンスに影響を与えるという段階を経るプロセスであることを忘れないでください.
したがって、ステージを高速化できれば、同じフレームを生成するための時間が短縮されます。つまり、ミリ秒が短くなり、XNUMX 秒あたりのフレーム数が増えます。 明確にする必要があるのは、レイ トレーシングでは交差プロセスが再帰的かつ連続的であるため、この部分が優れたパフォーマンスを発揮する必要があるということです。
その他の問題: 浮動小数点のパフォーマンス
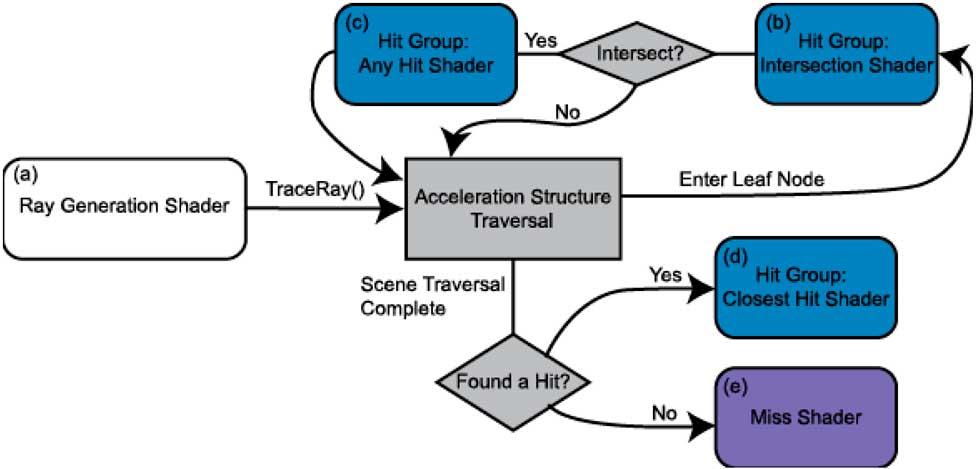
GPU は通常、データのブロックを一斉に処理し、同じ命令を適用します。 そのため、その典型的なタイプのユニットが SIMD ユニットと呼ばれるものであり、その名前が示すように、同じ命令を複数の異なるデータに同時に適用します。 さて、RTX 30 の NVIDIA は、クロック サイクルおよびコアごとに 32 倍の XNUMX ビット浮動小数点演算を計算できる、かなり興味深い改善を行いました。
トリックは、各サブコアに 16 番目の 64 要素 SIMD ユニットを追加して、ユニットごとに合計 XNUMX の追加 op を内部に追加することでした。 GPU. ただし、整数の単位で交換されているため、レコード数やアクセス数は増加しませんでした。 これは何に翻訳されますか? RTX 30 と RTX 40 の両方が、常にではありませんが、特定の条件下で倍精度浮動小数点のパフォーマンスを達成します。
一方、AMDは、デュアルイシューと呼ばれる別の解決策を模索していますが、技術仕様では、浮動小数点ユニットの数は増加していないが、特定の条件下では同時に2つの命令をパックできると述べています. ただし、コアまたはコンピューティング ユニットあたりのユニット数は、NVIDIA の場合のように 64 ではなく、依然として最大 128 です。
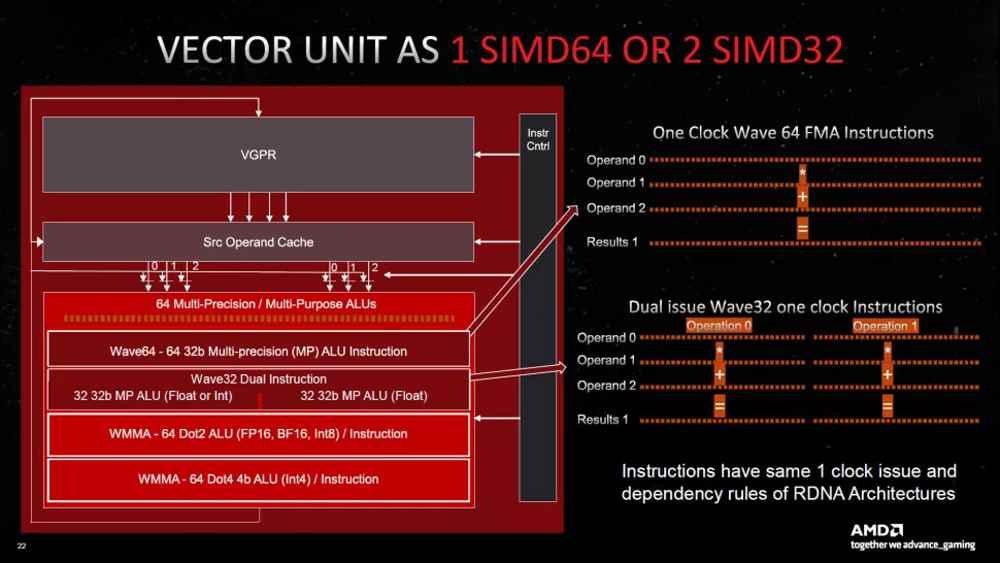
RDNA 3 における AMD の「デュアルイシュー」とは何を意味しますか?
ただし、AMD によって与えられた浮動小数点演算の数を数えると、通常は理論上の最大値で与えられ、100% の時間で FMA 演算または浮動小数点乗算による加算を実行しますが、これは非現実的です。メモリアクセスと、プログラムが常に上記の命令を使用するとは限らないという事実を考慮しますが、グラフィックスを生成するときに最も使用されることを考慮に入れます。 実際には、命令は2つの操作です。
AMD が行ったことは、特定の命令を計算ユニットに 2 つずつパッケージ化して、特定の条件下で RDNA XNUMX を使用して浮動小数点の XNUMX 倍の電力を実現できるようにすることです。 NVIDIA GPU の場合と同じです。 追加の浮動小数点数は一般に XNUMX 倍にはなりませんが、特定の条件下でのみです。 したがって、それは一般的な問題です。 いずれにせよ、TFLOPS での測定は、今日でもマーケティングのトリックです。
では、なぜ AMD のレイ トレーシングのパフォーマンスにとって重要なのでしょうか? それは、光線の交差ではないレイ トレーシングの残りの段階で使用される単位の計算能力を測定するのに役立つという事実によるものです。 いずれにせよ、AMD 自体は、世代間の改善は同じクロック速度で 18% であると主張しています。
レイ トレーシングにおける AMD GPU のパフォーマンス: 数値
NVIDIA と AMD の異なる世代のグラフィックス カードで異なる交差ユニットのパフォーマンスを比較すると、何が問題なのかがわかります。
| GPU | 交差点/秒 (百万) | 色 | メガヘルツ | 交差 (コアと MHz) |
|---|---|---|---|---|
| RTX 2080Ti | 105600 | 68 | 1545 | XNUMXつ |
| RTX 3090Ti | 312480 | 84 | 1860 | 2 |
| RTX 4090 | 1290240 | 144 | 2520 | 3.6 |
| RX 6950 XT | 184800 | 80 | 2310 | XNUMXつ |
| RX7900XTX | 360000 | 96 | 2500 | 1.5 |
一見すると、この側面の生のパワーは RTX 3090 Ti よりも高いです。はい、3.6 番目の列を見てください。 ただし、重要なのは後者であり、GPU のコアおよびクロック サイクルごとに計算されるインターセプトの数がわかります。 そして失望は、AMD が RTX 40 で 2 の結果を出すように求められていないにもかかわらず、RTX 30 で少なくとも XNUMX に達するように求められているという事実から来ています。これが AMD グラフィックス カードのパフォーマンスが低い主な理由です。レイ トレーシングで。 そして、彼らがもっとうまくやれたはずだと私たちが考える理由。
レイ アクセラレータ ユニットはそれ自体がブラック ボックスであり、アーキテクチャの残りの部分に影響を与えることなく交換できるため、それはまだ終わっていません。 AMDは、現在のRDNA 7のすべての利点を保持する来年のRX 50×3シリーズをピックアップして作成できますが、RAUが改善され、フレームレートに関してXNUMX桁の割合でゲームパフォーマンスが向上することが懸念されています.
RDNA 3 のレイ トレーシングを使用した AMD ゲームのパフォーマンスはどのくらいですか?
最後に、おまけとして、ゲームでのパフォーマンスについて説明します。 AMD は 50% の改善を公に主張しているため、同様に大きな飛躍が期待できます。 ただし、後で、それらがワットあたりのパフォーマンス、これらの特定の量、および指定されていない特定のゲームを参照していることを発見しました. したがって、重要なことは、特に RX 6000 からのレイ トレーシングのかなり低いパフォーマンスから始まるという事実のために、この面で前世代と比較してどのような改善が行われたかを知ることです.