
HBM-PIMは、によって提示されたいわゆる高帯域幅メモリの変形です。 サムスン 2021年に、その頭字語PIMは「Processingin Memory」と翻訳されました。これは、内部にプロセッサが統合されたバリアントに直面していることを意味します。 プロセス能力を備えたこのタイプのHBMはどのように提示され、誰を対象とし、その有用性は何ですか?
この記事を書いている時点で最初に理解しなければならないのは、HBM-PIMは、さまざまなメモリ標準の作成を担当する300社の委員会であるJEDECによって承認された標準ではないということです。または永続的。 。 現時点では、Samsungによる提案と設計であり、新しいタイプのHBMメモリに変換してサードパーティが製造するか、それができない場合は韓国のファウンドリの独占製品にすることができます。
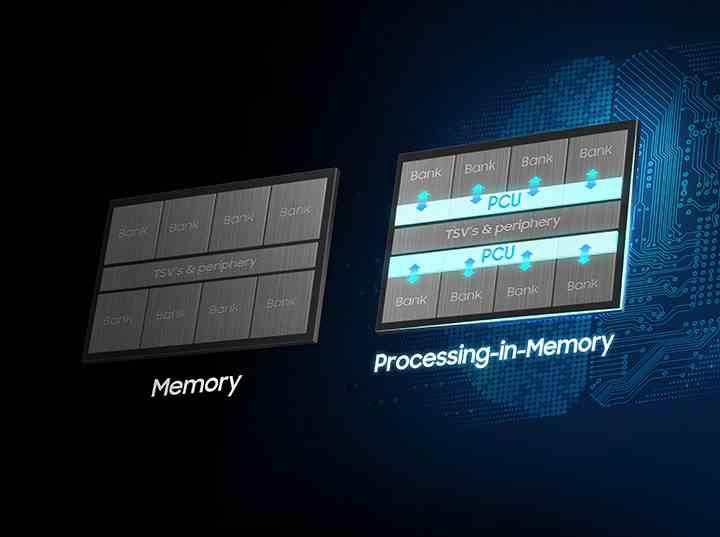
標準になるかどうかにかかわらず、HBM-PIMはザイリンクスのAlveo AI Accelerator用に製造されます。これは、私たちが完全に買収したことを覚えている会社です。 AMD。 したがって、これは紙の概念ではなく、実験用製品でもありませんが、このタイプのHBMメモリは大量に製造できます。 もちろん、ザイリンクスÁlveoは、データセンターで使用されるFPGAベースのアクセラレータカードです。 これはマスマーケット向けの製品ではなく、HBMメモリのバリエーションにすぎないことを覚えておく必要があります。これは、それ自体が非常に高価で製造が少なく、ゲーム用グラフィックカードなどの商用製品での使用が少なくなります。またはプロセッサ。
インメモリコンピューティングの概念

私たちがPCで実行するプログラムは、 RAM & CPU、両方をXNUMXつのチップに収めることができれば完璧です。 残念ながら、これは不可能であり、システムメモリと中央処理装置の間の遅延の結果である、コンピュータのアーキテクチャに固有の一連のボトルネックにつながります。
- 距離が長くなると、データの送信が遅くなります。
- エネルギー消費は、プログラムを実行する処理装置とプログラムが配置されているストレージ装置との間にあるスペースが増えるほど増加します。 これは、転送速度または帯域幅がプロセス速度よりも遅いことを意味します。
- この問題を解決する通常の方法は、CPU、GPU、またはAPUにキャッシュ階層を追加することです。 内部のRAMからデータをコピーして、必要な情報にすばやくアクセスします。
- 他のアーキテクチャは、組み込みRAMと呼ばれるスクラッチパッドRAMと呼ばれるものを使用します。これは自動的には機能せず、その内容はプログラムによって制御される必要があります。
そのため、プロセッサに統合されたRAMには問題があり、その容量が原因です。トランジスタの大部分はストレージではなく処理命令専用であるため、物理的なスペースの制限により、内部にデータをほとんど保存しません。

インメモリコンピューティングの概念は、ビットセルの重みが大きいロジックを追加するRAMについて話しているため、DRAMや組み込みSRAMとは逆に機能します。 したがって、複雑なプロセッサを統合することは問題ではなく、ドメイン固有のプロセッサ、さらにはハードウェアに配線された、または固定機能のアクセラレータを統合することです。
そして、このタイプのメモリの利点は何ですか? 少なくとも各命令に対して任意のプロセッサでプログラムを実行すると、そのCPUに割り当てられたRAMまたは GPU。 インメモリコンピューティングの考え方は、プログラムをPIMメモリに格納することに他なりません。また、CPUまたはGPUは、単一の呼び出し命令を使用し、メモリコンピューティングの処理ユニットがプログラムを実行して最終応答を返すのを待つだけで済みます。他のタスクのために無料であるCPUに。
サムスンHBM-PIMのプロセッサ
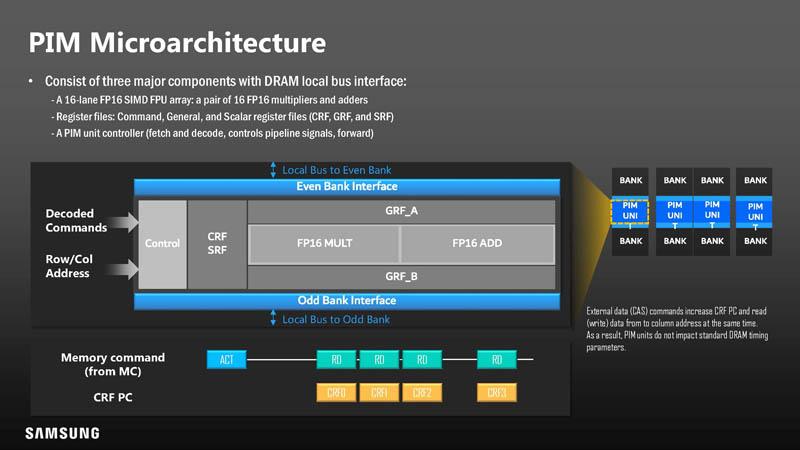
小さなCPUがHBM-PIMチップのスタック内の各チップに統合されているため、のストレージ容量は、メモリセルに送られるトランジスタを、統合された論理ゲートに割り当てるように指示することによって影響を受けます。プロセッサと私たちが以前に進歩したように、それは非常に単純なものです。
- 既知のISAは使用しませんが、合計で命令がほとんどない独自のISAを使用します:9。
- それぞれ16ビットの精度を持つ16個の浮動小数点ユニットのXNUMXつのセットがあります。 最初のセットには加算を実行する機能があり、XNUMX番目のセットには乗算を実行する機能があります。
- SIMDタイプの実行ユニットなので、これはベクトルプロセッサです。
- その算術機能は、A + B、A * B、(A + B)* C、および(A * C)+ Bです。
- 70回の操作あたりのエネルギー消費量はCPUが同じタスクを実行した場合よりもXNUMX%低くなります。ここでは、エネルギー消費量とデータとの距離の関係を考慮する必要があります。
- サムスンは、PCUの名前でこの小さなプロセッサにバプテスマを施しました。
- 各プロセッサは、その一部であるメモリチップ、またはスタック全体でのみ動作します。 また、HBM-PIMのユニットは連携して、それを必要とするアルゴリズムまたはプログラムを高速化できます。
その単純さから推測できるように、複雑なプログラムの実行には適していません。 その見返りとして、Samsungは、機械学習アルゴリズムを高速化するユニットとして関連付けるという考えの下でそれを推進していますが、ベクトルおよび非テンソルプロセッサであるため、複雑なシステムを処理することはできません。 そのため、この分野での機能は非常に限られており、音声認識、テキストと音声の翻訳など、あまり電力を必要としないものに焦点を当てています。 その計算能力は1.2TFLOPSであることを忘れないでください。
PCでHBM-PIMを確認しますか?

サムスンがHBM-PIMの利点の例として挙げているアプリケーションは、PC内の他のコンポーネントによってすでに高速化されています。さらに、このタイプのメモリの製造コストが高いため、自宅のコンピューター。 あなたが人工知能を専門とするプログラマーである場合、最も安全なことは、SamsungのHBM-PIMよりもはるかに高い処理能力を備えたハードウェアをコンピューターに搭載していることです。
現実には、韓国の巨人のマーケティング部門がAIについて話すのは悪い選択のように思えます。 はい、それは誰もが口にするファッショナブルなテクノロジーであることを考慮に入れていますが、HBM-PIMにはその機能を活用できる他の市場があると考えています。
これらのアプリケーションは何ですか? たとえば、何百もの企業が毎日使用する大規模なデータベースでの情報の検索を加速するのに役立ち、年間数百万ドルを動かす巨大な市場であると私たちは信じています。 いずれにせよ、まだ完成していないHBM3がHBM-PIMのアイデアの一部を継承している可能性はありますが、国内レベルや科学計算で使用されているとは考えていません。