
時が経つにつれて、ますます強力なプロセッサが登場するのを見てきましたが、ある時点以降、それらのパフォーマンスは新しいノードで自然にスケーリングしなくなると何度も言われています。 これにはいくつかの理由がありますが、最も重要なもののXNUMXつは、RC遅延として知られる現象です。
私たちのPCのハードウェアは、異なる電圧でコンポーネント間で電気信号を送信するというXNUMXつのことだけを行います。 使用する電圧に応じて、送信される情報には何らかの意味があります。 新しい製造ノードが作成されると、新しい現象が発生しましたが、最も悪化したのはRC遅延です。
RC遅延とは何ですか?

RC遅延は、回路のその部分の抵抗と静電容量の組み合わせによって生成される電気信号の遅延として解釈できます。 私たちが抵抗について話すとき、私たちは電子が回路のその特定の部分を通過しなければならない難しさについて話します。 一方、静電容量は、回路のその部分が電荷を蓄積しなければならない容量です。
RC遅延は、近年、新しい製造ノードの下で新しいチップを設計する人にとって最大の問題のXNUMXつになっています。 理由? 私たちは通常、チップはトランジスタで構成された論理ゲートで構成されているという概念を持っています。 現実には、これらの論理ゲートは、回路を通り、さまざまな電気信号が送信されるマイクロ配線を介して相互に接続されています。
ある論理ゲートを別の論理ゲートから分離する信号が、不要な情報の変化につながる可能性のある電気信号の変化なしに送信されるように、行われるのは、信号が通るケーブルの間に誘電体の層を配置することです。送信されます。 問題は、新しい製造ノードで面積あたりの密度が大きくなると同時に、マイクロ配線間の距離が短くなり、信号が歪むリスクが高まることです。
信号と回路

私たちは、デジタル集積回路がXNUMXとXNUMXを利用することによって機能することを理解する傾向があります。これは、概念を単純化したものです。 実際には、チップが連続的に変化するXNUMXつの異なる電圧の下で、チップの内部マイクロ配線を介して情報を送信することについて話しています。
回路で重要なのは、信号が正しく送信されるだけでなく、適切な期間に送信されることです。 RC遅延は、電子が電気回路を循環する速度も想定しているため、プロセッサの最終的なクロック速度に影響を与えます。
最後のノードの問題? トランジスタは予想内にスケーリングされていますが、配線は同程度にスケーリングされておらず、前のノードに比べて比較的大きいため、クロック速度は予想どおりにスケーリングされていません。 言い換えれば、MHzレースの終焉をもたらしたのは、プロセッサのさまざまなロジックコンポーネントとその内部メモリ間の相互接続です。
家賃ルールとそのRC遅延との関係
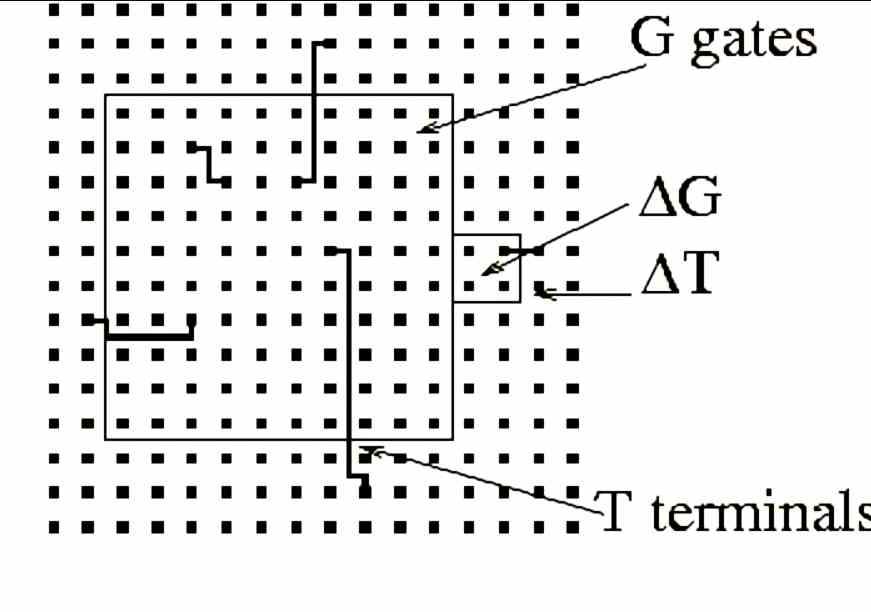
Rentのルールは、チップ内の計算ロジックの編成、特に、プロセッサが設計テーブル上にあるときにプロセッサの一部であるさまざまなロジックモジュールを相互接続する配線に関連しています。 家賃のルールは何ですか? さて、マイクロプロセッサがいくつの相互接続を持っているかを知るために。
家賃ルールの計算式は次のとおりです。
T = AK p
ここで、Tは端子の数、したがってチップ全体のマイクロケーブルの数、Aは各論理ブロック内のマイクロケーブルの平均数、Kはチップ内の各ブロックの論理ゲートの平均数です。 RC遅延とは何の関係がありますか? 賃貸料ルールにより、システムアーキテクトは設計の配線と場所だけでなく、マイクロ配線の長さ、したがってRC遅延も知ることができます。
ケーブルの距離もエネルギー消費に関係し、ケーブルが長いほどデータ転送の消費量が増えることも忘れられません。そのため、設計者は予想されるクロック速度とチップの消費電力のバランスをとる方法を知っている必要があります。
すべての希望が失われるわけではありません
既存の問題であるにもかかわらず、RC遅延は、新しいマイクロプロセッサとメモリの作成者によって無視されているものではありません。 近年、新しい製造ノードで増大するRC遅延の問題を軽減することを目的とした進歩があり、特にXNUMXつのタイプの進歩が並行して使用されています。
これらの最初のものは、端子間で分配される電気信号のより効率的な分離を可能にする新しい誘電体材料の検索です。 したがって、新しいCPU、GPU、およびメモリを作成するための新しい製造ノードの研究開発の大部分は、トランジスタのサイズを縮小するだけでなく、新しいノードで発生する問題を解決することに基づいています。
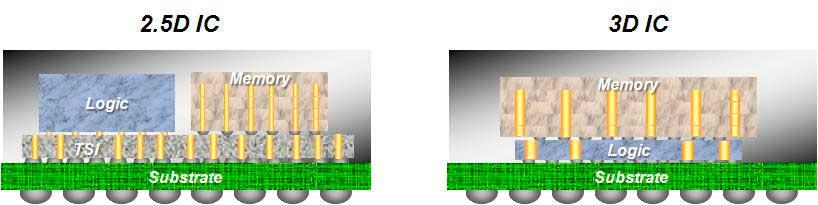
XNUMXつ目は、要素の相互通信に垂直構造を使用することです。これにより、端子の数を増やすことはありませんが、それらの間の距離が原因で、あるマイクロケーブルからの信号が別のマイクロケーブルに影響を与える可能性を減らすことになります。これらの間の距離。 このアプローチの唯一の問題は? 現時点では、メモリとメモリ、さらにはロジックとメモリの垂直相互接続が大規模に実装されていることを確認しましたが、将来的には、のクロック速度をスケーリングするためにロジックとロジックを比較する予定です。異なるプロセッサ。