多くの点で 建築 of NVIDIA 過去2006年間のGPUですが、重要なターニングポイントは、XNUMX年にグリーンのTeslaアーキテクチャが発売されたときです。この記事では、NVIDIAアーキテクチャがどのように進化したかをもう一度見ていきます。 テスラからチューリングへ 、現在のアーキテクチャ(アンペレの到着がない場合)、より具体的にはその方法 SM (ストリームマルチプロセッサ)はそれを実行しました。
この記事では、NVIDIAアーキテクチャがテスラからチューリングにどのように進化したかを確認します。そのため、次の表に要約されているように、バックグラウンドを理解し、これらの各アーキテクチャに何が特有であったかを確認する良い機会です。 。

| 年 | アーキテクチャ | シリーズ | 死 | リソグラフィプロセス | 最も代表的なグラフ |
|---|---|---|---|---|---|
| 2006 | テスラ | GeForce 8 | G80 | 90nm | 8800 GTX |
| 2010 | フェルミ | GeForce 400 | GF100 | 40nm | GTX 480 |
| 2012 | ケプラー | GeForce 600 | GK104 | 28 nmの | GTX 680 |
| 2014 | マクスウェル | GeForce 900 | GM204 | 28 nmの | 980 GTXはTi |
| 2016 | パスカル | GeForce 10 | GP102 | 16nm | 1080 GTXはTi |
| 2018 | チューリング | GeForce 20 | TU102 | 12nm | RTX 2080 Ti |
行き詰まり:NVIDIAテスラ以前の時代
2006年にテスラが到着するまで、NVIDIAは GPU デザインは、レンダリングAPIの論理状態に関連付けられていました。 ザ・ のGeForce GTX 7900 ダイG71を搭載し、8つのセクションで製造されました(24つは頂点処理専用(16ユニット)、もうXNUMXつはフラグメントを生成するため(XNUMXユニット)、もうXNUMXつはこれらを結合するため(XNUMXユニット))。
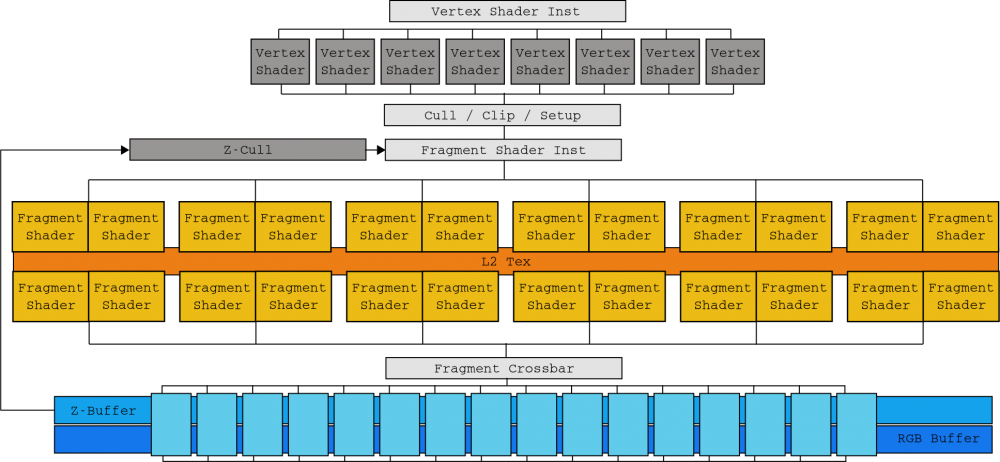
この相関関係により、設計者とエンジニアは、各層のバランスを適切に保つために、ボトルネックの場所を想像する必要がありました。 これに追加されたのは DirectXの10 ジオメトリシェーディングを使用したため、NVIDIAエンジニアは、グラフィカルAPIの次のステージをいつどのように行うかを知らなくても、岩盤と難しい場所の間にダイを配置することができました。
変更する時が来ました アーキテクチャの設計方法 .
NVIDIA Teslaアーキテクチャ
NVIDIAは、2006年に最初の「統合」されたテスラアーキテクチャで複雑さの増大の問題を解決しました。 G80が死んだ レイヤー間の区別はなくなりました。 ストリームマルチプロセッサ (SM)単一のカーネルで区別せずに頂点処理、シャード生成、およびシャード結合を実行できるため、以前のすべてのドライブが置き換えられました。 したがって、さらに、各瞬間のニーズに応じて各SMによって実行される「コア」を交換することにより、負荷が自動的に分散されます。
したがって、シェーダーユニットは、整数またはfloat32命令をそれ自体で処理できる「コア」(SIMD互換ではなくなりました)になります(SMは、ワープと呼ばれる32のグループのスレッドを受信します)。 理想的には、ワープ内のすべてのスレッドが同じステートメントを同時に実行するのは、異なるデータ(したがって、SIMTという名前)だけです。 マルチスレッド(MT)命令ユニットは、命令ポインター(IP)が収束または異なる場合に、各ワープでスレッドを有効または無効にする責任があります。
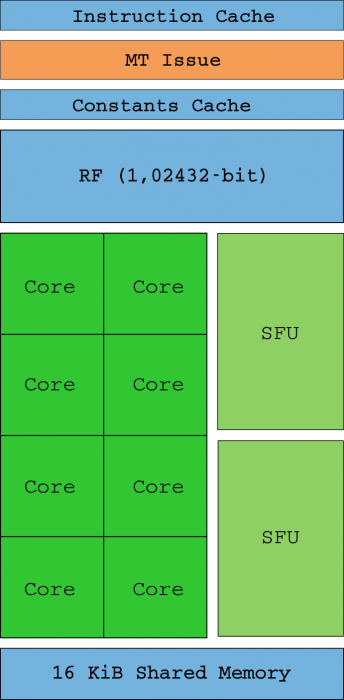
ツー SFU 単位(上の図で確認できます)は、逆平方根、正弦、余弦、exp、rcpなどの複雑な数学計算の支援を担当します。 これらのユニットは、クロックサイクルごとに64つの命令を実行することもできますが、XNUMXつしかないため、実行速度はそれぞれのXNUMXで除算されます(つまり、XNUMXつのコアごとにXNUMXつのSFUがあります)。 floatXNUMX計算のハードウェアサポートはありません。これらはソフトウェアによって実行されるため、パフォーマンスが大幅に低下します。
実行キューに常にプログラム可能なワープを配置することでメモリレイテンシを排除できる場合、およびワープのスレッドに相違がない場合(つまり、制御フローの目的であり、常に同じに維持されているため)指示のパス)。 ログファイル( 4KB RF )はスレッドの状態が保存される場所であり、実行キューを大量に消費するスレッドは、そのログに保持できるスレッドの数を減らし、パフォーマンスも低下させます。
このNVIDIA Teslaアーキテクチャの「主力」ダイは、有名なGeForce 90 GTXで発表された90ナノメートルのリソグラフィプロセスに基づくG8800でした。 1つのSMは、テクスチャユニットとTex L8キャッシュと共に、テクスチャプロセッサクラスタ(TPC)にグループ化されます。 80つのTPCで、G128は345.6コアを備え、8800 GFLOPの総電力を生成しました。 GeForce XNUMX GTXは、当時非常に人気がありました。
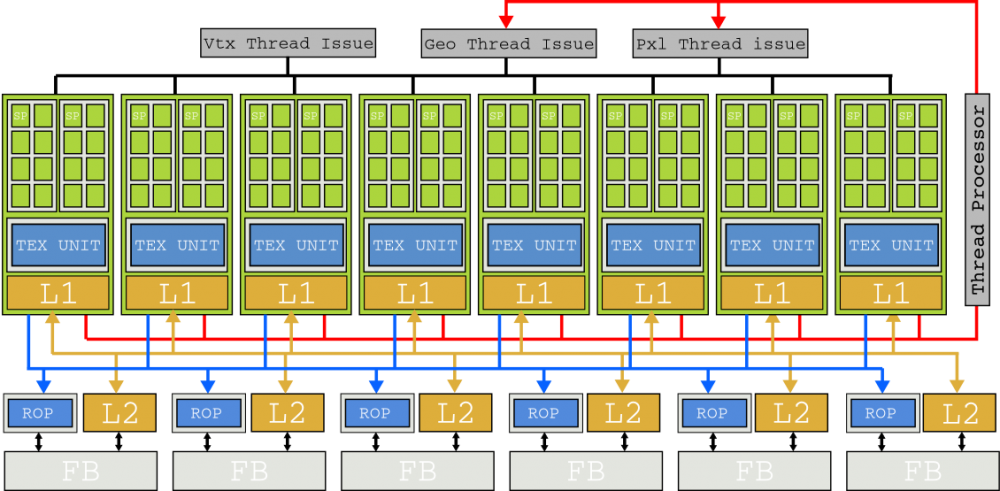
NVIDIAはテスラアーキテクチャとともに、C99のスーパーセットであるCでCUDA(コンピューティングユニファイドデバイドアーキテクチャ)プログラミング言語も導入しました。これは、GLSLシェーダーとテクスチャーでGPUをだます方法を歓迎したGPGPU愛好家を歓迎する救済でした。
このセクションでは、SMを広く取り上げましたが、システムの半分にすぎませんでした。 SMには、GPUのグラフィックスメモリに常駐する命令とデータを供給する必要があるため、停滞を回避するために、GPUはプロセッサ(CPU)のように大量のキャッシュメモリによるメモリの「トリップ」を回避せず、むしろメモリを乱雑にします。管理する数千のスレッドからのI / O要求用のバス。 このため、G80チップにはXNUMXつの双方向DRAMメモリチャネルを通じて高いメモリパフォーマンスが実装されました。
フェルミ建築
テスラは非常に危険な動きでしたが、それは非常に優れていることが判明し、非常に成功したため、今後2010年間、NVIDIAアーキテクチャの基盤となりました。 XNUMX年、NVIDIAは GF100 新しいに基づいて死ぬ フェルミ 内部に多数の新機能を備えたアーキテクチャ。
実行モデルはまだSMにプログラムされた32ワイヤーワープを中心に展開しており、それは 40nmリソグラフィ (テスラの90nmと比較して)NVIDIAはほぼすべてを16倍にしました。 SMは、16組の4 CUDAコアのおかげで、XNUMXつのメディアワープ(XNUMXスレッド)を同時にプログラムできるようになりました。 各コアがクロックサイクルごとにXNUMXつの命令を実行すると、XNUMXつのSMがサイクルごとにXNUMXつのワープ命令を実行できました(これはTesla SMの容量のXNUMX倍です)。

SFUカウントも強化されましたが、「64」が100倍されて合計32ユニットとなったため、SFUカウントは減少しました。 24つのCUDAコアを組み合わせて実行する、Teslaにはなかったfloat32計算用のハードウェアサポートも追加されました。 GFXNUMXは、XNUMXビットALU(vs. TeslaではXNUMXビット)のおかげで、単一のクロックサイクルで整数の乗算を実行でき、floatXNUMX精度が高くなります。
プログラミングの観点から見ると、Fermiの統合メモリシステムにより、CUDA Cに仮想オブジェクトやメソッドなどのC ++機能を追加することができました。
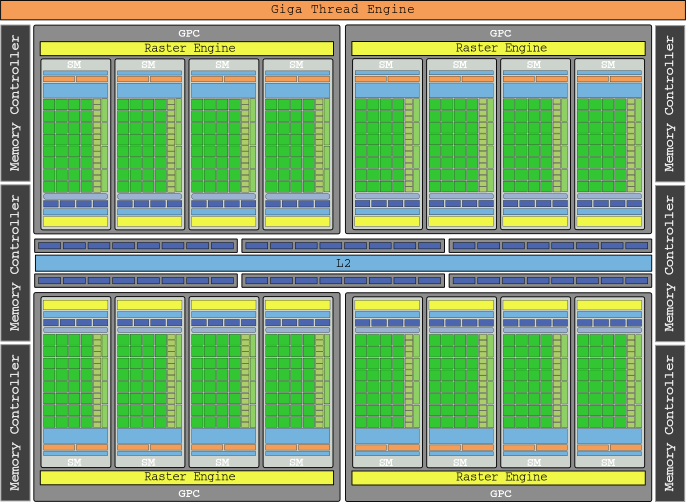
テクスチャユニットがSMの一部となったため、TPCの概念はなくなり、480つのSMを備えたグラフィックプロセッサクラスター(GPC)に置き換えられました。 最後に重要なことですが、オブジェクトの頂点、ビューの変換、テッセレーションを処理するための「ポリモーフ」エンジンが追加されました。 この世代のグラフィックスの旗艦はGTX 512で、1,345コアでXNUMX GFLOPの総電力を備えていました。
NVIDIA Keplerアーキテクチャ
2012年にNVIDIA Keplerアーキテクチャが登場しました。これにより、ダイのエネルギー効率が大幅に向上し、クロック速度を下げて中央クロックをカードの周波数と統一しました(以前は480倍の周波数でした)。これにより、前世代のGTX XNUMX(非常に熱くなり、消費量が非常に多かった)。
これらの変更によりパフォーマンスが低下するはずでしたが、28nmリソグラフィプロセスの実装とソフトウェアプログラマーの代わりにハードウェアプログラマーを排除したおかげで、NVIDIAはSMを追加できるだけでなく、その設計も改善することができました。 。

SMXとして知られる「次世代ストリーミングマルチプロセッサ」は、ほとんどすべてが196倍またはXNUMX倍にさえなる怪物であることが判明しました。 ワープ全体をXNUMXクロックサイクルで処理できるXNUMXつのワーププログラマー(フェルミのXNUMX分のXNUMXの設計と比較して)により、SMXにはXNUMXコアが含まれるようになりました。 各プログラマーは、現在実行されている命令から独立している場合、ワープ内のXNUMX番目の命令を実行するために二重ディスパッチを使用しますが、この二重プログラミングは常に実行可能であったとは限りません。
このアプローチはプログラミングロジックをより複雑にしましたが、XNUMXクロックあたり最大XNUMXつのワープ命令で、SMXケプラーはFermi SMのXNUMX倍のパフォーマンスを提供します。
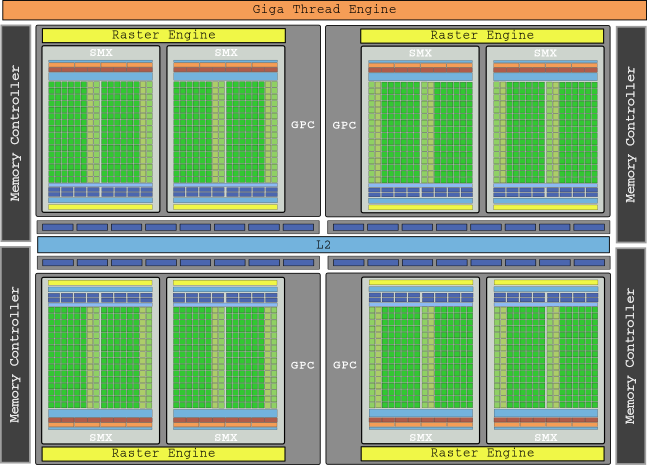
この世代のフラグシップグラフィックスは、GeForce GTX 680とそのダイGK104および8 SMXで、1536コアという驚異的な量を含み、合計で最大3,250 GFLOPの総電力を提供しました。
NVIDIA Maxwellアーキテクチャ
2014年に登場したのは、その第10世代GPUであるNVIDIA Maxwellアーキテクチャです。 彼らが技術文書で説明したように、これらのGPUの中心は「消費電力XNUMXワットあたりの卓越したエネルギー効率と並外れたパフォーマンス」でした。つまり、NVIDIAはこの世代をミニPCやラップトップなどの限られた電力システムに向けました。
主な決定は、ケプラーのSMXへのアプローチを断念し、ワープメディアを使用するというフェルミの哲学に戻ることでした。 このように、SMMはその歴史上初めて、128コアしか搭載していない旧モデルよりもコア数が少なくなっています。 経糸のサイズに合わせてコアの数を調整すると、ダイの構造が改善され、占有スペースと消費エネルギーが大幅に節約されました。
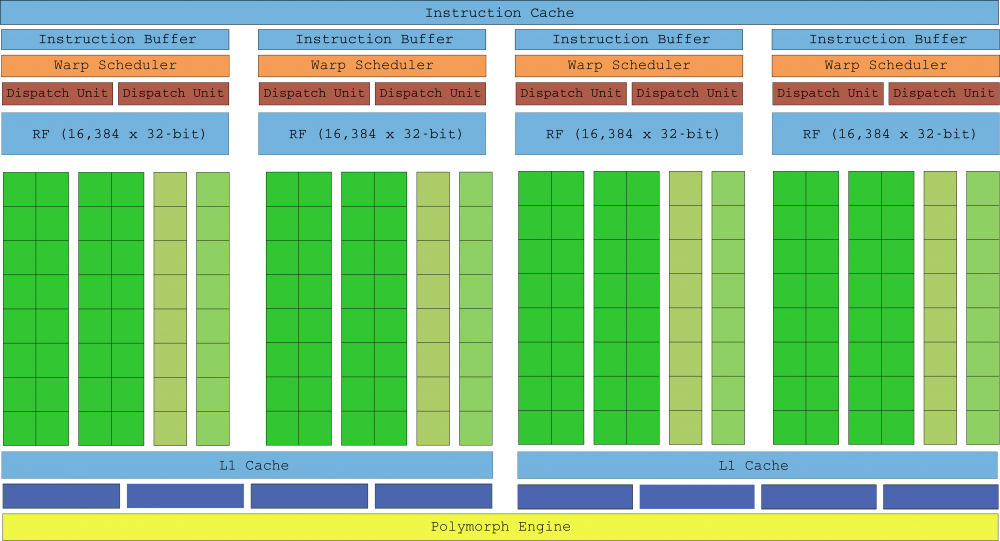
第28世代のMaxwellは、第2世代のエネルギー効率を維持しながら、パフォーマンスを大幅に向上させました。 リソグラフィプロセスが25nmで停滞しているため、NVIDIAのエンジニアはトランジスタの小型化に依存してパフォーマンスを向上させることはできませんでしたが、SMMあたりのコア数が少ないためサイズが小さくなり、より多くのSMMを搭載できました。 同じ日に。 Maxwell Gen XNUMXには、ケプラーのXNUMX倍のSMMが含まれており、ダイの面積はわずかXNUMX%です。
機能拡張のリストでは、スケジューリングの決定の冗長な再計算を減らし、計算のレイテンシを減らしてワープの占有率を向上させる、より簡素化されたスケジューリングロジックについても言及する必要があります。 メモリクロックも平均15%増加しました。
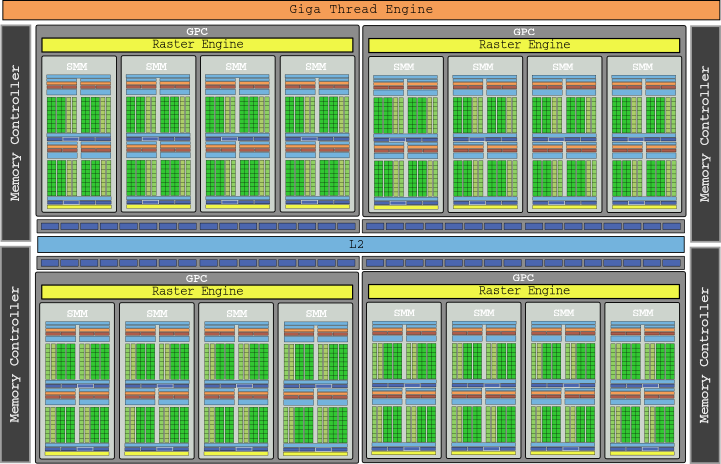
上に表示されているGM200チップの図は、目を痛めかけているようですね。 これは、980個のSMMに3072個のコアを備えたGTX 24 Tiを組み込み、6,060 GLOPの総電力を提供したダイです。
NVIDIA Pascalアーキテクチャ
2016年に次世代のNVIDIA Pascalが登場し、技術ドキュメントはMaxwellのSMMのカーボンコピーのように見えました。 しかし、SMに変更がないからといって、改善がなかったことを意味するわけではありません。実際、これらのチップで使用される16nmプロセスは、同じチップにさらに多くのSMを配置できるため、パフォーマンスが大幅に向上しました。
ハイライトする他の重要な改良点は、GDDR5Xメモリシステムでした。これは、10つのメモリコントローラーのおかげで最大256 Gbpsの転送速度を提供する斬新なもので、その43ビットインターフェイスは前世代よりXNUMX%多い帯域幅を提供します。
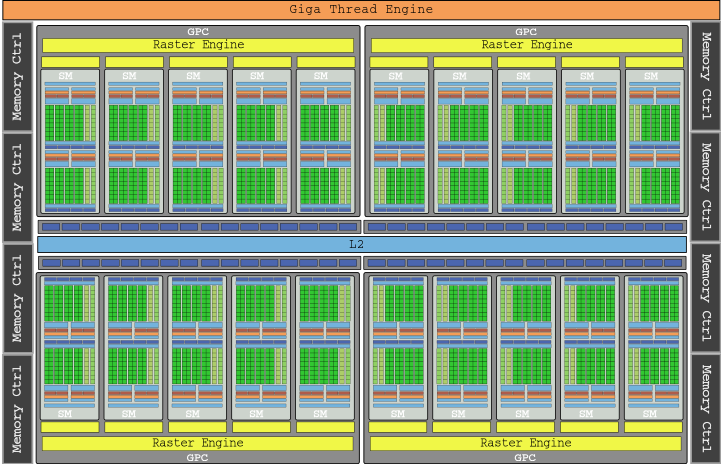
Pascal世代のグラフィックスフラッグシップはGTX 1080 Tiで、上の画像に表示されているダイのGP102と28 SMで、総電力が3584 GLOPの合計11,340コアを搭載しています(すでに11.3 TFLOPです) )。
NVIDIA Turingアーキテクチャ
2018年に発売されたチューリングアーキテクチャは、「NVIDIAの言葉では」「XNUMX年以上で最大のアーキテクチャ上の飛躍」となりました。 SM Turingが追加されただけでなく、TensorコアとRayTracingコアを備えた専用のレイトレーシングハードウェアが最初に導入されました。 この設計では、最初に説明したテスラ以前のレイヤーのスタイルで、ダイが再び「断片化」されたと想定しています。
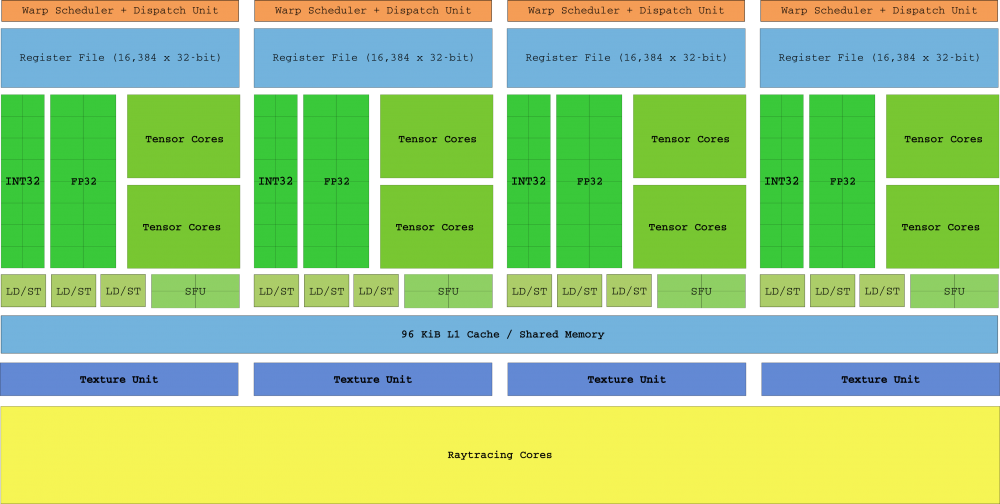
新しいカーネルに加えて、チューリングはXNUMXつの主要な機能を追加しました。XNUMXつは、CUDAカーネルがスケーラブルになり、整数命令と浮動小数点命令の両方を並行して実行できるようになりました(これにより多くの「革命的」なものが思い出されます) インテル そこにあるPentiumアーキテクチャ。 1996年)。 次に、6個のコントローラーに支えられた新しいGDDR16メモリシステム(14 Gbpsに到達可能)、そして最後に、ワープで命令ポインターを共有しなくなったスレッド。
Voltaで導入された独立したスレッドプログラミング(ユーザー中心ではないアーキテクチャであるためここには含めません)のおかげで、各スレッドは独自のIPを持ち、その結果、SMはワープでスレッドを自由にプログラムできます。彼らができるだけ早く収束するのを待つ必要性。

この世代のグラフィックスのトップはRTX 2080 Tiで、そのTU102ダイと68 TSMは4352コアを含み、総電力は13.45 TFLOPです。 前の図のように彼の完全なブロック図を配置することはしません。画面に収めるためには、ぼかしになるほど縮小する必要があるためです。
そして次に来るのは?
ご存じのとおり、次のNVIDIAアーキテクチャはAmpereと呼ばれ、TSMCから7 nmの製造ノードに確実に到着します。 すべてのデータが利用可能になり次第、この記事を更新します。