サーバーがある場合 Linux または、オペレーティングシステム自体と個人または作業ファイルおよびフォルダの両方の内部に多くの情報を含むNASサーバー(Linuxベースのオペレーティングシステムもあります)では、ハードドライブと SSD ドライブは正常であり、警告なしにすぐに破損することはありません。 このため、サーバーのハードドライブまたはSSDを継続的に監視して、サーバーの破損によるデータの損失を回避することが非常に重要です。 今日のこの記事では、ディスクの状態をチェックするためにLinuxサーバーでチェックする必要があるすべてのものを紹介します。

ディスクのスマートとは何ですか
すべてのハードドライブとSSDドライブには、SMARTと呼ばれるテクノロジ、または「Self Monitoring AnalysisandReportingTechnology」の略であるSMARTとも呼ばれるテクノロジがあります。 ハードドライブとSSDのファームウェアに組み込まれているこのテクノロジは、ハードドライブの物理エラーや、内部フラッシュメモリへの書き込みによるSSDドライブの予期しない障害を予測することを目的として、ハードドライブで発生する可能性のある障害を検出することで構成されます。 。 SMARTの目標は、データを失うことなくドライブをバックアップおよび交換できるようにユーザーに警告することです。 SMARTを無視すると、ハードドライブが壊れてデータが失われる時期が来るので、ディスクのSMARTデータに常に注意を払うことが不可欠です。
SMARTを使用するには、サーバーのBIOSまたはUEFIがこのテクノロジーと互換性があり、アクティブ化されている必要があります。さらに、ディスクにSMARTが組み込まれている必要があります。 現在、すべてのサーバー、オペレーティングシステム、およびディスクがこのテクノロジを使用してハードディスクの問題を検出しています。これは「ユニバーサル」であり、常に使用されていると言えます。
このテクノロジは、ディスクプラッタの速度、不良セクタ、キャリブレーションエラー、周期的冗長性チェック(一般的なCRCエラー)、ディスク温度、データ読み取り速度、起動時間(スピン- up)、再割り当てされたセクターカウンター、検索速度(シーク時間)、およびその他の非常に高度なパラメーターにより、何が重要かを知ることができます。ハードドライブがすぐに故障するかどうか。
内部的にSMARTには「正常」と見なすことができる値の範囲があり、パラメーターがこれらの値から外れると、つまりアラームが鳴ると、BIOS / UEFIはそれを検出し、オペレーティングシステムに障害があることを通知しますシステム内。 ディスクとそれは深刻になる可能性があります。 Linuxオペレーティングシステムでは、ディスクが正しく機能しているかどうかを確認するためにSMARTテストを実行する可能性があります。さらに、パフォーマンスへの影響を最小限に抑えるためにこれらのテストをプログラミングする可能性があります。
ディスクの状態を表示する方法
ほとんどのLinuxベースのディストリビューションには、smartmontoolsというパッケージがあります。 このパッケージがディストリビューションにプリインストールされている場合もあれば、自分でインストールする必要がある場合もあります。 このパッケージには、XNUMXつの異なるプログラムがあります。
- スマートコントロール :は、ハードドライブとSSDをオンデマンドで検証できるコマンドラインプログラムです。または、オペレーティングシステムの一般的なcronを使用してその動作をプログラムできます。
- スマート :は、指定された間隔のハードドライブまたはSSDに障害が発生していないことを確認するデーモンまたはプロセスです。 サーバーのメインsyslogに任意のタイプの警告またはディスクエラーを登録できます。また、管理者がすべてが正しいことを確認できるように、これらの同じ警告およびエラーを電子メールで管理者に送信することもできます。
smartmontoolsパッケージは、ハードドライブとSSDドライブの監視を担当し、SATA、SCSI、SAS、またはNVMEインターフェイスを使用しているかどうかに関係なく、あらゆるタイプのデータインターフェイスをサポートします。 もちろん、このプログラムは完全に無料です。
インストール
このプログラムのインストールは、Linuxディストリビューションにデフォルトでインストールされていない場合は、ディストリビューションのパッケージマネージャーを使用して行います。 たとえば、aptを使用するDebianオペレーティングシステムでは、次のようになります。
sudo apt install smartmontools
ディストリビューションのパッケージマネージャーに応じて、いずれかのコマンドを使用する必要があります。重要なことは、このパッケージがすべてのUnixベースのディストリビューションとLinuxで利用できるため、FreeBSDにも問題なくインストールできることです。
smartctlの使用
このプログラムを使用してハードドライブの状態を確認するには、まず、ハードドライブの数と、問題のハードドライブまたはSSDを調べるためのパスを確認する必要があります。 ディスクがどこにあるかを知るには、次のコマンドを実行する必要があります。
df -h
fdiskを使用して、サーバー上にあるディスクのリストを取得することもできます。
sudo fdisk -l
これらのコマンドは、ユニットとパーティションのリストを表示します。 このプログラムは、パーティションレベルではなく、ハードディスクまたはSSDレベルで使用する必要があります。 通常、Linuxシステムでは、ディスクは/ dev/sdXパスにあります。
SMARTを介してヘルスをチェックするために分析するドライブがわかったら、実行できるテストが全部でXNUMXつあることを知っておく必要があります。
- ショートテスト –このテストは、ディスクの問題を検出するために最もよく使用されます。 このテストを実行すると、ディスク全体を詳細に分析する必要なしに、最も重要なエラーと警告が表示されます。 cronを介したこの短いテストを毎週行うようにスケジュールできます。このようにして、毎週XNUMX回、この分析を実行し、エラーが検出された場合は通知します。 このテストは、ほとんどまたはまったく使用されていないときに実行することをお勧めします。就業時間中、夜明けに実行することはお勧めしません。
- ロングテスト –このテストは、ドライブとその容量によっては、かなり長い時間がかかる場合があります。 この包括的なテストを実行することにより、ディスク全体で検出されたすべての警告またはエラーが表示されます。 cronを使用してこの長いテストを毎月実行するようにスケジュールできます。つまり、毎月XNUMX回、このテストを実行してディスクの状態をチェックします。 夜明けなど、ディスクをほとんど使用しないときにこのテストを実行することをお勧めします。そうしないと、読み取りと書き込みのパフォーマンスとデータアクセスの待ち時間が大幅に増加します。
使用できるXNUMX種類のテストがわかったら、最初に知っておく必要があるのは、ハードドライブまたはSSDでSMARTが有効になっているかどうかです。
sudo smartctl -i /dev/sda
ディスクがSMARTをサポートしているがアクティブ化されていない場合は、次のコマンドを実行してアクティブ化できます。
sudo smartctl -s on /dev/sda
問題のディスクの製造元のすべてのSMART属性を表示するには、次のコマンドを実行できます。
sudo smartctl -a /dev/sda
簡単なテストを実行するために、以下を実行します。
sudo smartctl -t short /dev/sda
長いテストを実行するには、次の手順を実行します。
sudo smartctl -t long /dev/sda
短いテストまたは長いテストを実行したら、次のコマンドを実行してすべての結果を確認できます。
sudo smartctl -H /dev/sda

SMARTの可能性を使用するために実行できるすべてのコマンドが記載されているsmartctlのマニュアルページを読むことをお勧めしますが、主なコマンドは説明したものです。
どのような値を見るべきですか?
SMARTテストを実行すると、ハードドライブまたはSSDの多数の属性が表示されます。 これらの値のいくつかは、ディスクがすぐに故障するという「手がかり」を与える可能性があるため、私たちが細心の注意を払うことが重要です。
- Reallocated_Sector_Ct:読み取りエラーが発生したために、ディスクの他の領域に再割り当てされたセクターの数です。 このエラーは、ディスクが非常に古く、耐用年数の終わりに近づいている場合に非常に一般的です。
- Spin_Retry_Count:ディスクの起動に必要な試行回数です。これは、ディスクに重大なハードウェアの問題があり、次回は起動しない可能性があることを示しています。
- Reallocated_Event_Count –正常または失敗のいずれかで実行された再割り当ての数。 数値が大きいほど、ハードドライブの状態が悪化します。
- Current_Pending_Sector:間もなく再割り当てが保留されているセクターの数。
- offline_Uncorrectable:ディスクのさまざまなセクターにアクセス(読み取りまたは書き込み)したときの修正不可能なエラーの数。
- Multi_Zone_Error_Rate:セクターの書き込み中のエラーの総数。
次の画像では、XigmaNASオペレーティングシステムを搭載したNASからのWDRed4TBハードドライブのステータスを確認できます。

前のスクリーンショットでは多くの情報を見ることができますが、それが孤立した障害なのか、ディスクがすぐに故障する可能性があるのかを知る必要があります。
QNAPNASのディスクのステータス
QNAP、Synology、またはASUSTOR NASサーバーを使用している場合は、Webアクセスが可能なオペレーティングシステムを介してハードドライブとSSDのSMARTステータスを確認することもできます。SSHまたはTelnet経由で入力してコマンドを実行する必要はありません。 。 以下の例では、QNAP NASサーバーを使用していますが、他のメーカーとのプロセスは非常に似ています。
私たちが最初にやらなければならないことは、「 ストレージとスナップショット 」セクション、ここで、「 ストレージ/ディスク 」と表示されます。次のようになります。

「 ディスクの状態 」、私たちは私たちが見たいすべてのディスクのどれを選択する必要があります。 HDDハードドライブとSSDドライブの両方を選択できます。ディスクエラーがあるかどうかを確認するための内部SMART情報もあるため、タイプに関係なく選択できます。

「概要」メニューでは、ディスクの一般的なステータスを確認できます。エラーや重大な警告が発生した場合は、SMARTの詳細な分析を実行しなくても、一般的な状態を簡単かつ迅速に確認できます。値。 もちろん、ディスクアクセス履歴や問題があったかどうかも確認できます。

QNAPは非常にわかりやすい情報を提供してくれますが、すべての生の値を確認したい場合は、問題なく実行することもできます。 さらに、「ステータス」とそれが良いか悪いかを示す追加の列があります。
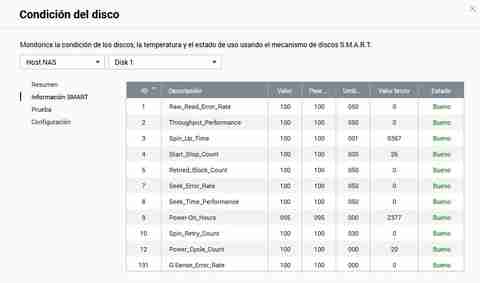
ここから迅速または完全なテストを行うことができます。テスト方法を選択し、[テスト]ボタンをクリックするだけです。

最後に、これらのテストを非常に簡単な方法でプログラムすることもできます。クイックテストまたは完全なテストをアクティブ化するかどうかを選択し、頻度を選択するだけです。さらに、このテストの開始時間を定義できます。

ご覧のとおり、サーバー内のハードドライブとSSDのヘルスステータスを確認および検証することは、データの損失を回避するために非常に重要です。 何らかのエラーが発生した場合、データの損失を防ぐために、新しいドライブを購入してバックアップを作成することが非常に重要です。 さらに、特にZFS RAID 0またはStripeを構成している場合は、ストレージプール全体が失われる可能性があるため、RAIDのステータスも確認する必要があります。