Con la comparsa di sistemi di confezionamento come Foveros di Intel e SoIC di TSMC, a poco a poco le tecnologie che fanno uso dei cosiddetti circuiti integrati o 3DIC si stanno evolvendo, ma tutte hanno un punto in comune. L'uso di interconnessioni verticali per comunicare i diversi elementi di questi potenti processori eterogenei.
Una delle maggiori sfide durante la progettazione di un processore è il consumo di energia che si verifica durante l'elaborazione e lo spostamento delle informazioni. Il problema arriva quando negli ultimi anni tutto lo sforzo ingegneristico non è stato concentrato sull'ottenimento delle unità di esecuzione più veloci, ma sull'avere una comunicazione sufficiente in modo che l'elaborazione fosse abbastanza veloce.

Indipendentemente dal fatto che un computer utilizzi il modello Harvard o Von Neumann, avrà bisogno di una memoria a cui il processore accede per funzionare. Nei sistemi più semplici, questa memoria è su un chip separato e deve essere accessibile tramite un'interconnessione o un cavo. Ebbene, il grosso problema si presenta quando si tiene conto di una serie di principi di base.
Il primo e più importante è il fatto che la resistenza in un cavo aumenta quanto più è lungo, se prendiamo in considerazione la legge di Ohm sapremo che la tensione è il risultato della moltiplicazione della resistenza per l'intensità. Cosa c'entra questo con i semiconduttori? Non dimentichiamo che sono circuiti elettrici di piccola scala e quindi se aumenta la distanza da cui devono operare i dati, aumenterà il consumo di energia.
La ragione di ciò si trova nella formula di base per calcolare il consumo di energia, che è: P = V 2 *C*f. Dove V è la tensione, C è la capacità di carico che il semiconduttore può sopportare e f è la frequenza. Bene, abbiamo visto come la tensione cresce con la resistenza e dobbiamo aggiungere che cresce anche con la velocità di clock.
Interconnessioni verticali
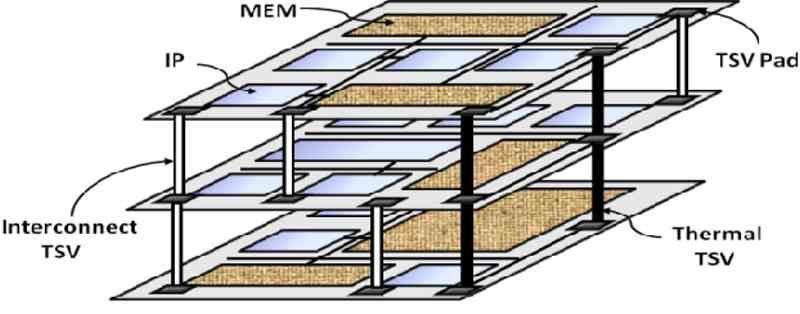
Ora che abbiamo il principio di base scopriamo che la soluzione è accorciare i cavi per avvicinare la memoria all'elaborazione. Fin dall'inizio troviamo un limite e non è altro che la comunicazione tra CPU ed RAM avviene orizzontalmente sul PCB e instradando l'interfaccia di comunicazione corrispondente a ciascuna estremità, in modo che in un punto non saremo in grado di continuare a ridurre la distanza.
Poiché il consumo di energia aumenta esponenzialmente con la velocità di clock, allora la soluzione migliore è aumentare il numero di interconnessioni esistenti nell'interfaccia di comunicazione, ma siamo limitati dalle sue dimensioni e poiché si trova sul perimetro del processore ciò significa aumentare le sue dimensioni, che lo rende più costoso da produrre. La soluzione? Posizionare detta memoria sopra il chip, in modo tale da poter avere un cablaggio a matrice.
Entrambe le cose combinate ci consentono di aumentare il numero di interconnessioni, che per ottenere la stessa larghezza di banda ci consente di ridurre la velocità di clock, ma abbiamo anche il vantaggio di aver ridotto la distanza del cablaggio di comunicazione, quindi riduciamo anche i consumi a quel punto. Il risultato? Riduci del 10% il costo energetico del traffico dati.
Il problema della LLC e il consumo

In un design multicore, parliamo di una CPU o di un GPU, c'è sempre una cache chiamata LLC o ultimo livello che è la più lontana dal processore, ma la più vicina alla memoria, il suo lavoro è:
- Dare coerenza nell'indirizzare la memoria dei diversi nuclei che ne fanno parte.
- Consentono la comunicazione tra i diversi core senza doverlo fare in RAM, riducendo così i consumi.
- Permette ai diversi core che ne fanno parte di accedere bene ad una memoria comune.
Il problema nasce quando in un progetto decidiamo di separare più core l'uno dall'altro per creare più chip, ma senza perdere la funzionalità nel suo insieme per tutti loro. Il primo problema che abbiamo dovuto affrontare? Separandoli abbiamo allungato la distanza e con essa la resistenza del cablaggio, ergo il consumo di energia è aumentato di conseguenza.
Implementazioni di interconnessione

Questo a certi livelli di consumo non è un problema, ma in una GPU lo è e all'improvviso scopriamo che non possiamo creare un processore grafico composto da chiplet utilizzando i metodi di comunicazione tradizionali. Da qui lo sviluppo dei citofoni verticali per comunicare i diversi chip, il che significa che devono essere cablati verticalmente con una base interfonica comune che chiamiamo Interposer.
I progetti multi-chip esistono quando è necessario raggiungere un livello di complessità in cui la dimensione di un singolo chip è controproducente in termini di produzione e costi, ma qui le interconnessioni verticali sono generalmente prodotte tra i diversi elementi sopra l'interpositore con esso. Ma non è efficiente come un'interconnessione diretta, perché anche una relativa distanza di intercomunicazione.

D'altra parte, quando si parla di un'implementazione con un chip di piccola scala, si finisce per optare per impilare due o più chip uno sopra l'altro e intercomunicarli verticalmente. Possono essere due memorie, due processori o la combinazione di memoria e processore. Abbiamo già diversi casi di questo nell'hardware attuale, come la memoria HBM o la 3D-NAND Flash, il già ritirato Lakefield di Intel e i core Zen 3 con V-Cache di AMD.
Quindi il 3DIC non è fantascienza, è qualcosa che abbiamo da diversi anni nel mondo dell'hardware e consiste nel creare circuiti integrati in cui l'interazione tra i componenti avviene verticalmente anziché orizzontalmente. Il che porta con sé i vantaggi a cui abbiamo accennato prima riguardo alle interconnessioni verticali a fronte del consumo energetico.