Uno dei concetti chiave per comprendere l'architettura e le prestazioni della corrente Intel ed AMD CPU è il concetto di microoperazioni, così come unità come la loro cache. In questo articolo ti diremo in modo accessibile cosa sono e perché i processori di oggi basano su di essi tutto il loro funzionamento per ottenere le massime prestazioni possibili.
A CPU oggi è in grado di eseguire un gran numero di istruzioni diverse e lo fa a frequenze fino a 5,000 volte superiori a quelle dei primi personal computer. Tendiamo a pensare e completamente erroneamente che la maggiore quantità di MHz o GHz sia dovuta a quelli nuovi di fabbricazione. La realtà è molto diversa ed è qui che entrano in gioco le microoperazioni, che sono la chiave per ottenere l'enorme potenza di calcolo dei microprocessori di oggi.

Cosa sono le microoperazioni?
Una delle similitudini con la realtà che di solito si usano per spiegare cos'è un programma è la similitudine con una ricetta di cucina. In cui possiamo vedere assegnate in un verbo una serie di azioni che dobbiamo compiere. Ad esempio, posso mettere in una ricetta che fai soffriggere un pezzo di carne in padella, ma per te risulterà dover cercare la padella, fare lo stesso con l'olio, mettere quest'ultimo in padella, aspettare che sia caldo e metterci dentro il pezzo di carne. Come puoi vedere, abbiamo convertito qualcosa che in linea di principio è definito da un singolo verbo in una serie di azioni.
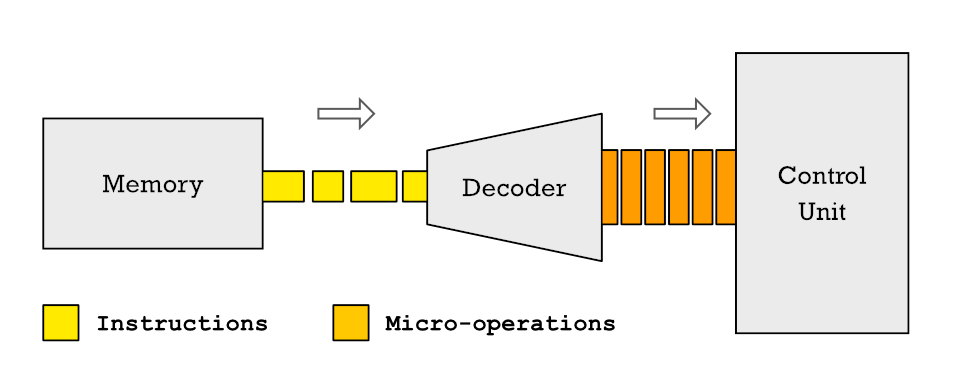
Bene, le istruzioni di una CPU possono essere suddivise in istruzioni più piccole che chiamiamo microoperazioni. E perché non le microistruzioni? Bene, a causa del fatto che un'istruzione, semplicemente segmentandola in più cicli per la sua esecuzione, richiede diversi cicli di clock per essere risolta. Una microoperazione, invece, richiede un singolo ciclo di clock.
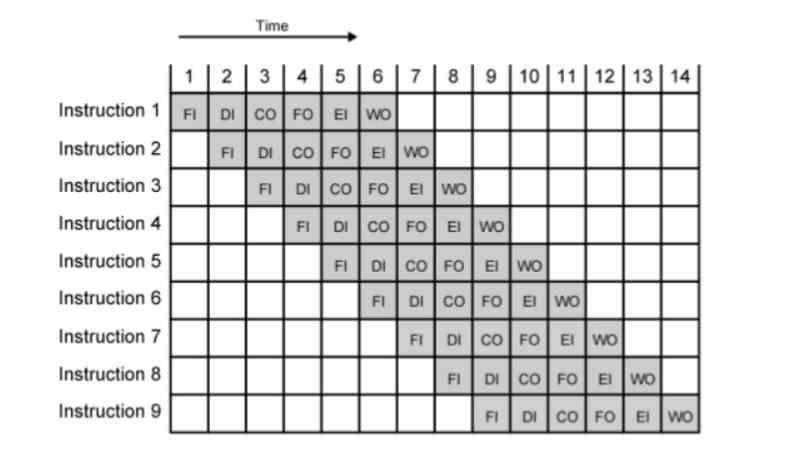
Un modo per ottenere il massimo in MHz o GHz è il pipelining, in cui ogni istruzione viene eseguita in più fasi che durano ciascuna un ciclo di clock. Poiché la frequenza è l'inverso del tempo, per ottenere più frequenza dobbiamo ridurre il tempo. Il problema è che si raggiunge il punto in cui un'istruzione non può più essere scomposta, il numero di fasi nella pipeline diventa breve e quindi la velocità di clock che può essere raggiunta è bassa.
In realtà, questi sono nati con la comparsa dell'esecuzione fuori ordine dell'architettura Intel P6 e delle sue CPU derivate come Pentium II e III. La ragione di ciò è che la segmentazione del P5 o del Pentium ha consentito loro di raggiungere solo poco più di 200 MHz. Con le microoperazioni, allungando ancora di più il numero di stadi di ogni istruzione, hanno superato la barriera dei GHz con il Pentium 3 e sono stati in grado di avere velocità di clock 16 volte superiori con il Pentium 4. Da allora sono stati utilizzati in tutte le CPU con esecuzione fuori ordine, indipendentemente dal marchio, dal registro e dal set di istruzioni.
Le tue CPU non sono né x86, né RISC-V, né ARM
Nelle CPU attuali, quando le istruzioni arrivano all'unità di controllo della CPU per essere decodificate e assegnate all'unità di controllo, vengono prima suddivise in diverse microoperazioni. Ciò significa che ogni istruzione eseguita dal processore è composta da una serie di micro operazioni di base e l'insieme di esse in un flusso ordinato è chiamato microcodice.

La scomposizione delle istruzioni in microoperazioni e la trasformazione dei programmi archiviati RAM in microcode si trova oggi in tutti i processori. Quindi, quando il tuo telefono è ISA ARM La CPU o la CPU x86 del tuo PC sta eseguendo programmi, le sue unità di esecuzione non stanno risolvendo le istruzioni con quei set di registri e istruzioni.
Questo processo non solo ha i vantaggi che abbiamo spiegato nella sezione precedente, ma possiamo anche trovare istruzioni che, anche all'interno della stessa architettura e sotto lo stesso insieme di registri e istruzioni, sono scomposte in modo diverso e i programmi sono completamente compatibili. L'idea è spesso di ridurre il numero di cicli di clock richiesti, ma il più delle volte è evitare la contesa che si verifica quando ci sono più richieste alla stessa risorsa all'interno del processore.
Cos'è la cache micro-operativa?
L'altro elemento importante per ottenere le massime prestazioni possibili è la cache delle microoperazioni, che è successiva alle microoperazioni e quindi più vicina nel tempo. La sua origine è da ricercare nella trace cache che Intel ha implementato nel Pentium 4. Si tratta di un'estensione della cache di primo livello per le istruzioni che memorizza la correlazione tra le diverse istruzioni e le microoperazioni in cui sono state precedentemente disassemblate dall'unità di controllo .

Tuttavia, l'ISA x86 ha sempre avuto un problema rispetto al tipo RISC, mentre questi ultimi hanno una lunghezza di istruzione fissa nel codice, nel caso dell'x86 ognuno di essi può misurare tra 1 e 15 byte. Dobbiamo tenere a mente che ogni istruzione viene recuperata e decodificata in diverse micro-operazioni. Per fare questo, ancora oggi, è necessaria una centralina molto complessa che possa consumare fino a un terzo della sua potenza energetica senza le necessarie ottimizzazioni.
La cache di micro-operazione è quindi un'evoluzione della cache di traccia, ma non fa parte della cache di istruzioni, è un'entità indipendente dall'hardware. In una cache di microoperazione, la dimensione di ciascuno di essi è fissata in termini di numero di byte, consentendo ad esempio ad una CPU con ISA x86 di operare il più vicino possibile ad un tipo RISC e ridurre la complessità dell'unità di controllo e con essa consumo. La differenza dalla cache della trama del Pentium 4 è che l'attuale cache micro-operativa memorizza tutte le micro-operazioni appartenenti a un'istruzione in un'unica riga.
Come funziona?
Ciò che fa la cache delle microoperazioni è evitare il lavoro di decodifica delle istruzioni, quindi quando il decodificatore ha appena eseguito tale attività, ciò che fa è memorizzare il risultato del suo lavoro in detta cache. In questo modo, quando è necessario decodificare la seguente istruzione, ciò che si fa è cercare se le microoperazioni che la compongono si trovano in detta cache. La motivazione per fare ciò non è altro che il fatto che ci vuole meno tempo per consultare detta cache che non per scomporre un'istruzione complessa.
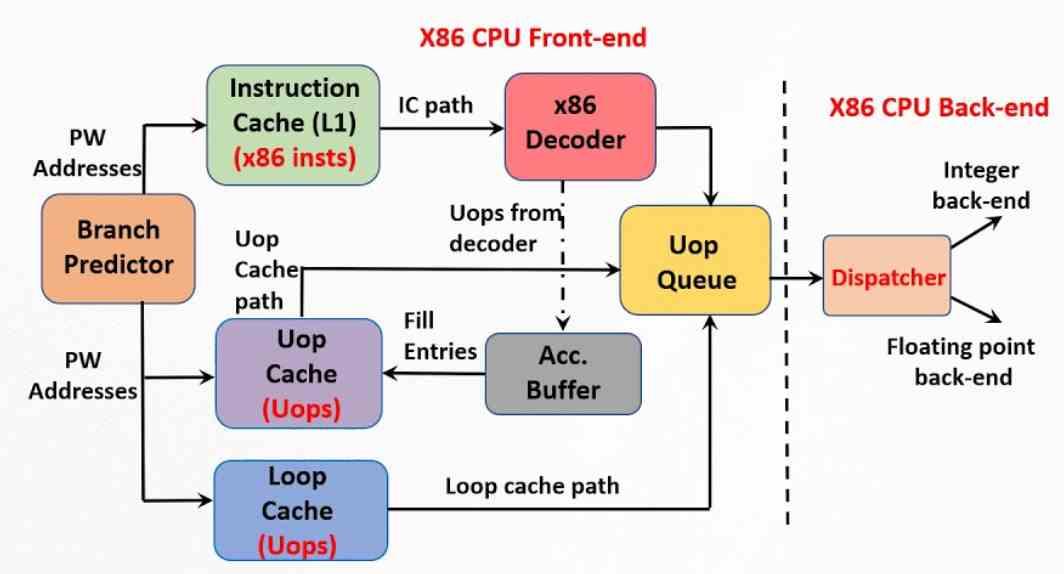
Tuttavia, funziona come una cache e il suo contenuto viene spostato nel tempo con l'arrivo di nuove istruzioni. Quando c'è una nuova istruzione nella cache delle istruzioni di primo livello, la cache delle micro operazioni viene cercata se è già decodificata. In caso contrario, procedere come al solito.
Le istruzioni più comuni una volta scomposte fanno solitamente parte della cache delle micro operazioni. Ciò che fa sì che meno vengano scartati, tuttavia, è che quelli il cui uso è sporadico lo saranno più spesso, per lasciare spazio a nuove istruzioni. Idealmente, la dimensione della cache di microoperazione dovrebbe essere sufficientemente grande per memorizzarli tutti, ma dovrebbe essere sufficientemente piccola in modo che la ricerca in essa non influisca sulle prestazioni della CPU.