
Se hai letto le specifiche complete di alcuni dei più recenti Intel CPU, lo farai ho visto apparire degli acronimi misteriosi: GN. In realtà è un piccolo processore o meglio un coprocessore che ha il compito di accelerare determinati Deep Learning algoritmi e che, quindi, sono strettamente legati all'implementazione dell'intelligenza artificiale. Spieghiamo in cosa consiste questo coprocessore e quali sono le sue funzionalità.
Processori dedicati a velocizzare alcune attività quotidiane, utilizzando modelli sviluppati tramite intelligenza artificiale, sono apparsi negli ultimi anni in tutte le configurazioni e dimensioni e non sorprende che Intel non abbia voluto essere lasciata indietro.
Cos'è l'Intel GNA?
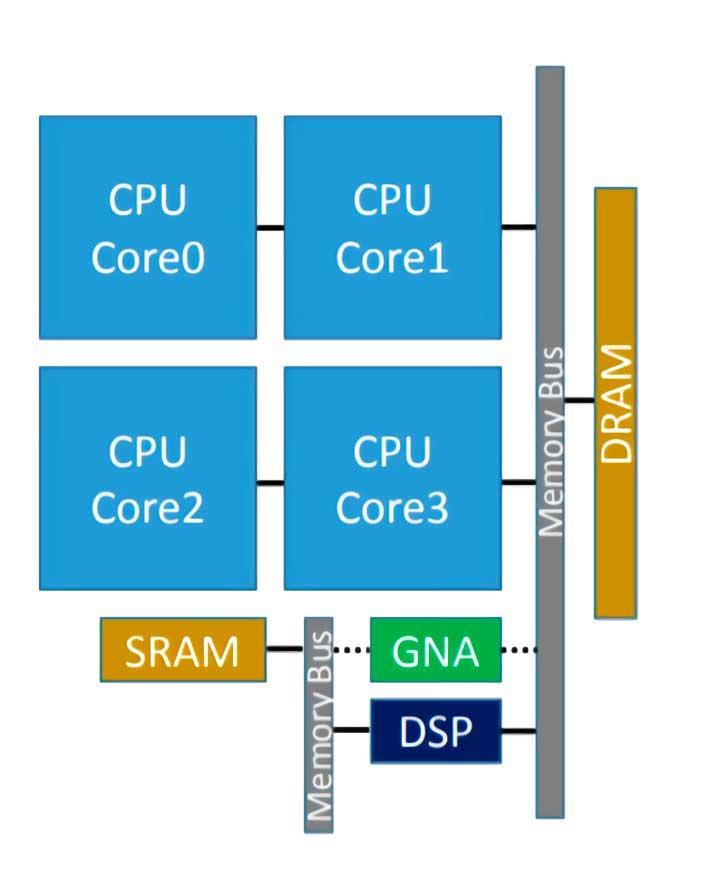
L'Intel GNA è il coprocessore che alcune CPU Intel hanno integrato e che serve per accelerare l'esecuzione di alcuni algoritmi di inferenza. Detto questo, molti di voi sapranno già che quindi siamo di fronte a un processore di tipo neurale, che in questo caso è stato introdotto per la prima volta nell'Intel Ice Lake, e il suo acronimo significa Acceleratore neurale gaussiano ( RNG ), ed essendo integrato nel proprio processore funziona a bassissimo consumo.
È concepito per essere utilizzato per attività come la trascrizione audio in tempo reale o la rimozione del rumore fotografico, tipiche dell'IA, ma non richiedono un acceleratore ad alta potenza.
È stato recentemente migliorato a Tiger Lake, dove è stata implementata la versione 2.0 del GNA, che dovrebbe essere utilizzata anche per cancellare il rumore ambientale e ridurre il rumore nelle fotografie. Con questo possiamo dedurre che il GNA è progettato per ambienti di lavoro collaborativo, soprattutto quelli basati sul telelavoro in cui la trascrizione del testo e che la comunicazione avviene senza rumori di alcun tipo è molto importante.
Cosa puoi fare con noi?
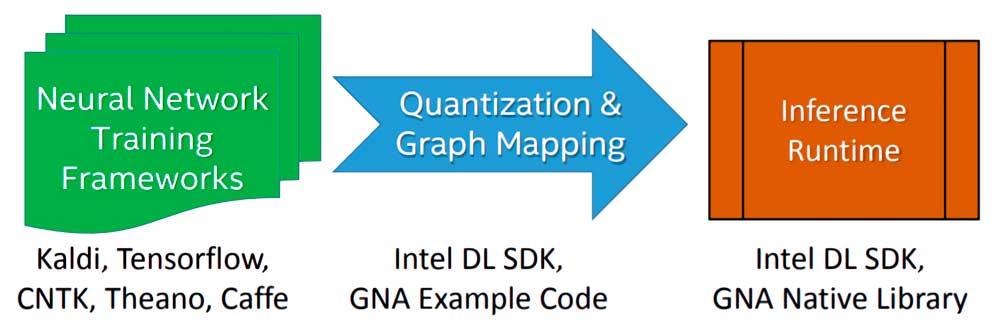
Intel GNA non è un'unità di esecuzione di CPU quindi abbiamo a che fare con un processore all'interno di un altro e serve per accelerare determinate attività per il suo ospite. Ciò significa che deve essere richiamato esplicitamente nel codice tramite un'API, in questo caso l'API Intel dedicata.
L'implementazione di un algoritmo o modello di Deep Learning che deve essere eseguito dall'Intel GNA durante la fase di inferenza avviene in tre fasi:
- Iniziamo addestrando l'algoritmo utilizzando una rete neurale in virgola mobile con un framework a scelta libera.
- Il modello risultante dal training viene importato utilizzando l'Intel Deep Learning SDK Deployment Tool che permette di importare qualsiasi modello generato dai framework di Deep Learning più famosi e utilizzati.
- Si collega al motore di inferenza Intel Deep Learning SDK o alle librerie GNA native, di cui ce ne sono due: una per Intel Quark e l'altra per Intel Atom e Intel Core.
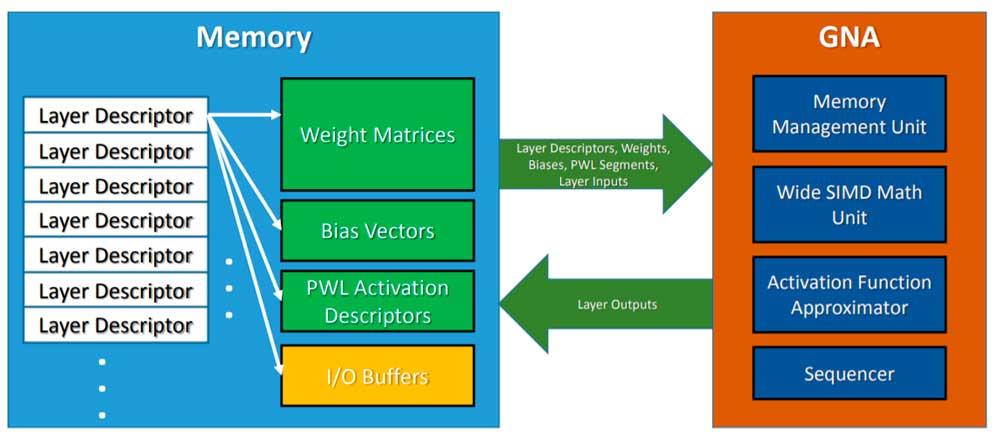
Per invocare il GNA, ciò che la CPU fa è lasciare in memoria il modello di inferenza, e il GNA viene invocato per adottare detto algoritmo ed eseguirlo parallelamente al lavoro del processore di cui è l'host. Si deve anche tenere conto del fatto che si tratta di un'unità a bassa potenza, quindi non possiamo aspettarci gli stessi risultati dell'utilizzo di una rete neurale ad alte prestazioni o di un FPGA configurato come tale, ma è abbastanza buono per attività semplici da un giorno all'altro .
Intel GNA al di fuori delle CPU Intel

Sebbene GNA sia esso stesso un processore integrato come parte delle CPU x86, può essere distribuito al di fuori della CPU se lo si desidera, il caso più famoso è il Kit di sviluppo per abilitazione vocale Intel , utilizzato soprattutto per inferire i comandi vocali per le applicazioni per Amazon Alexa dispositivi.