L'Infinity Cache è la differenza più notevole tra le schede grafiche della serie RX 6000 recentemente introdotte (RX 6800, RX 6800 XT e RX 6900) con il Xbox SoC serie X GPU, anch'esso basato su RDNA 2. ¿Ma cos'è esattamente l'Infinity Cache, a cosa serve e come funziona? Vi sveleremo tutti i suoi segreti.
Fin dalle settimane precedenti la presentazione della RX 6000 si sapeva dell'esistenza di questo enorme pool di memoria all'interno della GPU, enorme perché si tratta della cache più grande nella storia delle GPU con circa 128 MB di capacità . Ma AMD non ha dato molte informazioni al riguardo, ci ha semplicemente raccontato della sua esistenza.

Ecco perché è necessaria una spiegazione dettagliata per capire perché AMD ha inserito una cache di tali dimensioni nella versione del suo RDNA 2 per PC.
Individuazione dell'Infinity Cache

Il primo punto che è necessario per capire quale sia la funzione di un pezzo all'interno dell'hardware è dedurre la sua funzione dalla sua posizione all'interno del sistema.
Dal RDNA 2 è un'evoluzione di RDNA , prima di tutto, dobbiamo dare uno sguardo alla prima generazione dell'attuale architettura grafica AMD, di cui conosciamo due chip che sono Navi 10 e Navi 14.
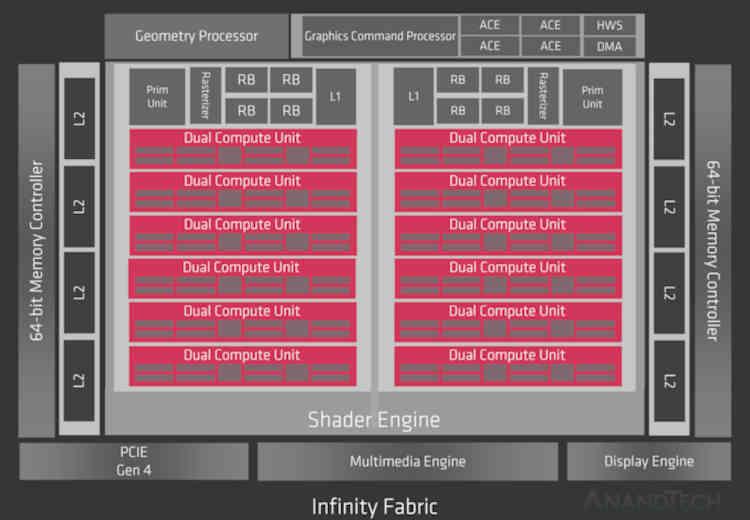
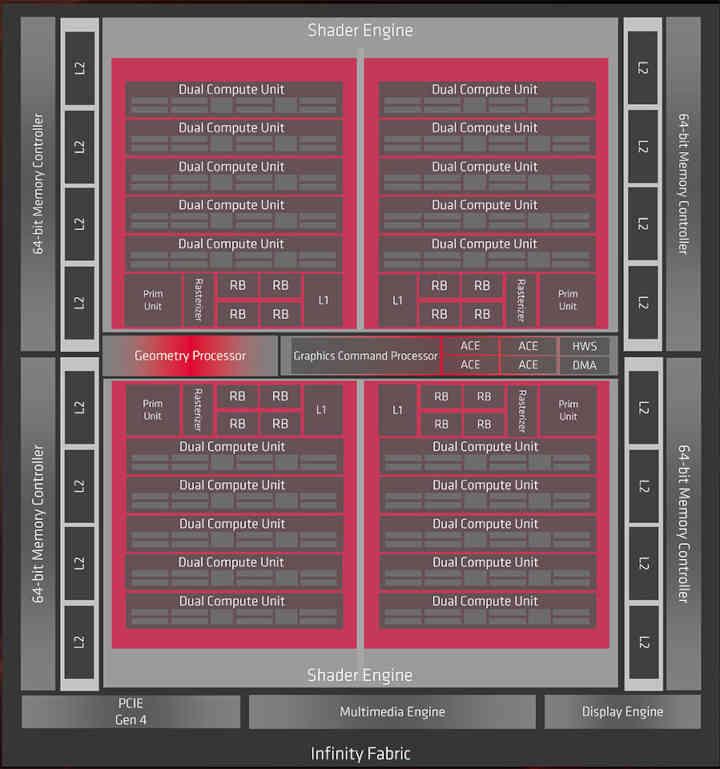
Bene, se Infinity Cache fosse stato implementato in RDNA, sarebbe nella parte che dice Infinity Fabric del diagramma, quindi a livello di organizzazione della cache andremmo da questo:
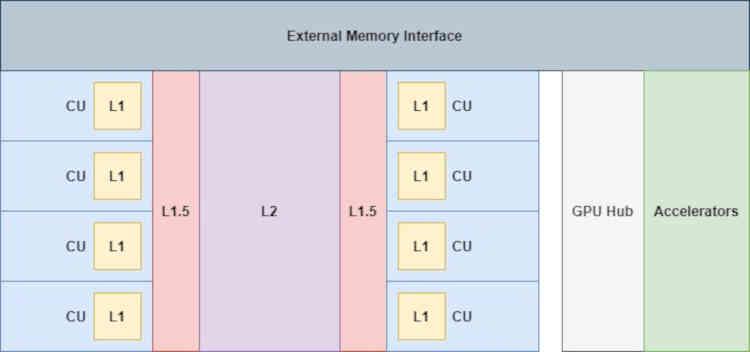
Dove gli acceleratori collegati al GPU Hub (il codec video, il display controller, le unità DMA, ecc.) Non hanno accesso diretto alle cache, nemmeno alla cache L2.
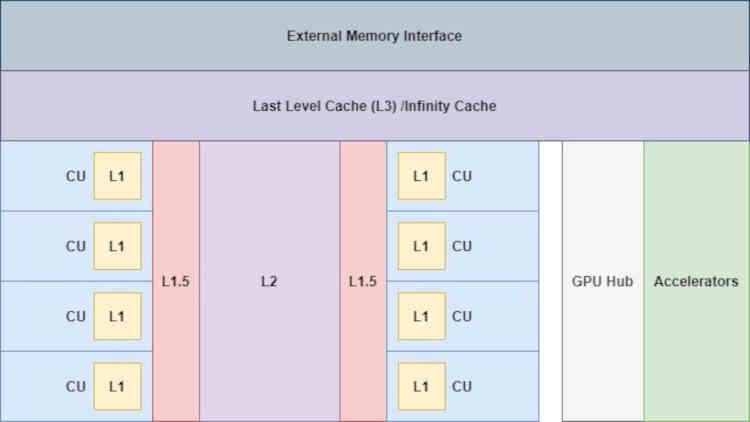
Con l'aggiunta dell'Infinity Cache le cose cambiano già "un po '", visto che ora gli acceleratori hanno accesso a questa memoria,
Questo è molto importante, soprattutto per Display Core Next, che è responsabile della lettura del buffer dell'immagine finale e della sua trasmissione alla corrispondente Display Port o interfaccia HDMI in modo che l'immagine venga visualizzata sullo schermo, questo è importante per ridurre gli accessi a VRAM da queste unità.
Ricordando il sistema di cache RDNA

In RDNA, le cache sono collegate tra loro nel modo seguente:

La cache L2 è collegata all'esterno a 16 canali da 32 byte / ciclo ciascuno, se guardiamo il diagramma Navi 10 allora vedrai come questa GPU ha circa 16 partizioni cache L2 e un bus GDDR256 a 6 bit a cui sono collegati.
Tieni presente che GDDR6 utilizza 2 canali per chip che operano in parallelo, ciascuno di 16 bit.
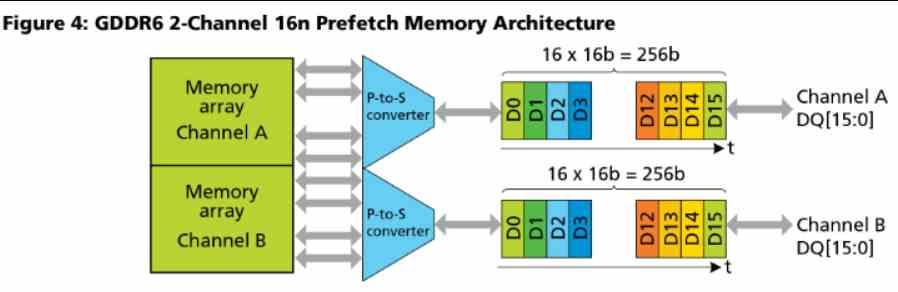
In altre parole, il numero di partizioni cache L2 nelle architetture RDNA è uguale al numero di canali GDDR16 a 6 bit collegati al processore grafico. In RDNA e RDNA 2 ogni partizione è di 256 KB, questo è il motivo per cui Xbox Series X che ha un bus a 320 bit e quindi 20 canali GDDR6 ha circa 5 MB di cache L2.
Un nuovo livello di cache: Infinity Cache

Poiché si tratta di un livello aggiuntivo di cache, l'Infinity Cache deve essere collegata direttamente alla cache L2, che è il livello precedente nella gerarchia della cache, questo ci viene confermato da AMD stessa in un piè di pagina:
Misurazione calcolata dagli ingegneri AMD, su una scheda della serie Radeon RX 6000 con estensione 128MB AMD Infinity Cache e GDDR256 a 6 bit. Misurazione delle percentuali di successo medie di AMD Infinity Cache nei giochi 4k del 58% nei principali titoli di gioco, moltiplicate per la larghezza di banda massima teorica del 16 canali AMD Infinity Fabric da 64B collegando la cache al motore grafico a una frequenza boost fino a 1.94 GHz.
La GPU utilizzata in RX 6800, RX 6800 XT e RX 6900 è Navi 21 che ha un bus GDDR256 a 6 bit, ergo ha 16 canali e quindi le 16 partizioni di Caché L2 sono ciascuna collegata a una partizione di Infinity Cache.
Quanto alla questione dei “tassi di successo” del 58%, è più complicata ed è ciò che cercheremo di spiegare di seguito.
Caching delle tessere su GPU NVIDIA

Prima di proseguire con l'Infinity Cache dobbiamo capire i motivi della sua esistenza e per questo dobbiamo guardare a come si sono evolute le GPU negli ultimi anni.
A partire dalla NVIDIA Maxwell, GeForce 900 Series, NVIDIA ha apportato un cambiamento importante alle loro GPU che hanno chiamato Tile Caching, il cui cambiamento ha coinvolto il collegamento del ROPS e dell'unità raster alla cache L2.
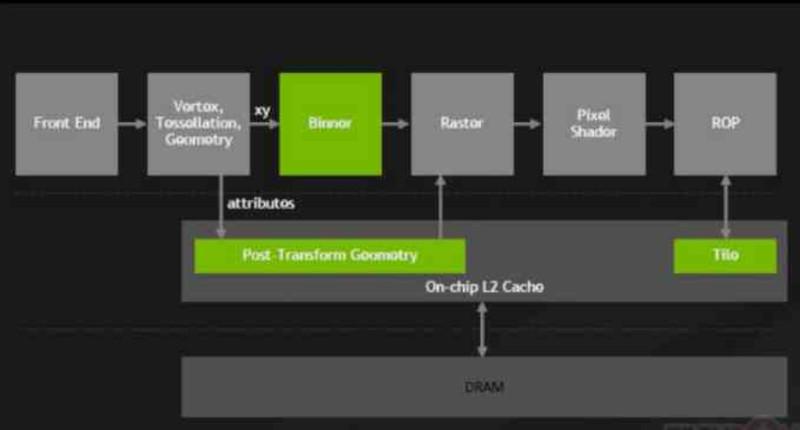
Con questa modifica, il ROPS ha smesso di scrivere direttamente sulla VRAM, i ROPS sono comuni a tutte le GPU e sono responsabili della creazione dei buffer di immagine in memoria.
Grazie a questo cambiamento, NVIDIA è stata in grado di ridurre l'impatto energetico sul bus di memoria riducendo la quantità di trasferimenti che sono stati effettuati da e verso la VRAM e con questo, NVIDIA è riuscita a ottenere l'efficienza energetica da AMD con le architetture Maxwell e Pascal.
DSBR, il Tile Caching su GPU AMD
AMD, d'altra parte, durante tutte le generazioni dell'architettura GCN prima di Vega, ha collegato i Render Backend (RB) direttamente al controller di memoria.

Ma a partire da AMD Vega, ha apportato due modifiche all'architettura per aggiungere Tile Caching alle sue GPU, la prima è stata il rinnovo dell'unità raster, che ha ribattezzato DSBR, Draw Stream Binning Rasterizer.

La seconda modifica è stata che hanno collegato l'unità raster e ROPS alla cache L2, una modifica che esiste ancora in RDNA e RDNA 2.
L'utilità di DSBR o Tile Caching
Il Tile Caching o DSBR è efficiente perché ordina la geometria della scena in base alla sua posizione sullo schermo prima che venga rasterizzata, questo è stato un cambiamento importante poiché le GPU prima dell'implementazione di questa tecnica ordinato i frammenti già strutturati appena prima di inviarli al buffer dell'immagine.
In Tile Caching / DSBR ciò che viene fatto è ordina i poligoni della scena prima che vengano convertiti in frammenti dall'unità di rasterizzazione.
In Tile Caching, i poligoni vengono ordinati in base alla loro posizione sullo schermo in tile, dove ogni tile è un frammento di n * n pixel.
Uno dei vantaggi di questo è che permette di eliminare preventivamente i pixel non visibili dei frammenti che risultano opachi quando si trovano nella stessa situazione. Qualcosa che non può essere fatto se gli elementi che compongono la scena vengono ordinati dopo la texturizzazione.
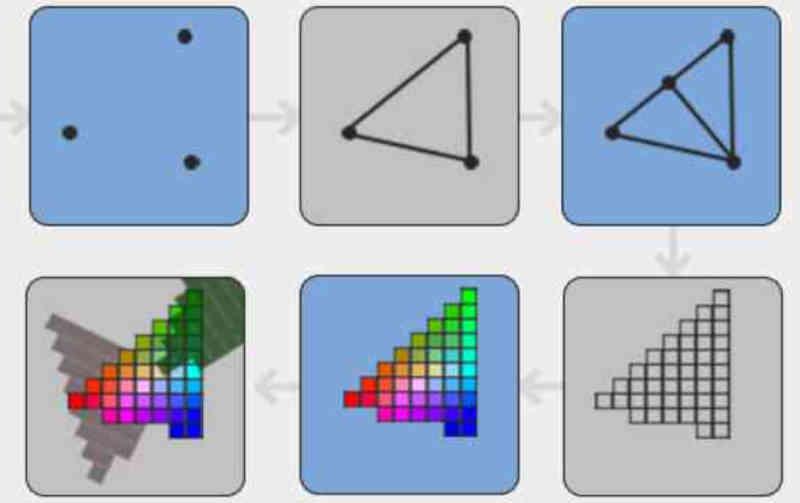
Ciò consente alla GPU di risparmiare tempo su pixel superflui e migliora l'efficienza della GPU. Nel caso in cui trovi questo confuso, è semplice come ricordare che in tutta la pipeline grafica le diverse primitive che compongono la scena assumono forme diverse durante le diverse fasi di essa.
La cache delle tessere o DSBR non è equivalente al rendering delle tessere
Sebbene il nome possa essere fuorviante, il caching delle tessere non è equivalente al rendering delle tessere per i seguenti motivi:
- I renderer di tessere memorizzano la geometria della scena, la ordinano e creano elenchi di schermate per ogni tessera. Questo processo non si verifica nel caso di Tile Caching o DSBR.
- In Tile Rendering, i ROPS sono collegati alle memorie degli appunti al di fuori della gerarchia della cache e non svuotano il loro contenuto nella VRAM fino a quando il riquadro non è stato completato al 100%, quindi le percentuali di successo sono del 100%.
- Nel Tile Caching / DSBR, poiché i ROPS / RB sono collegati alla cache L2, in qualsiasi momento le linee della cache da L2 a RAM possono essere scartate, quindi non vi è alcuna garanzia che il 100% dei dati sia nella cache L2.
Poiché esiste un'alta probabilità che le linee della cache finiscano nella VRAM, ciò che AMD ha fatto con Infinity Cache è aggiungere un ulteriore livello di cache che raccoglie i dati scartati dalla cache L2 della GPU.
Infinity Cache è una Victim Cache
Le Vittima Caché idea è un'eredità di CPU sotto architetture Zen che è stata adattata a RDNA 2.
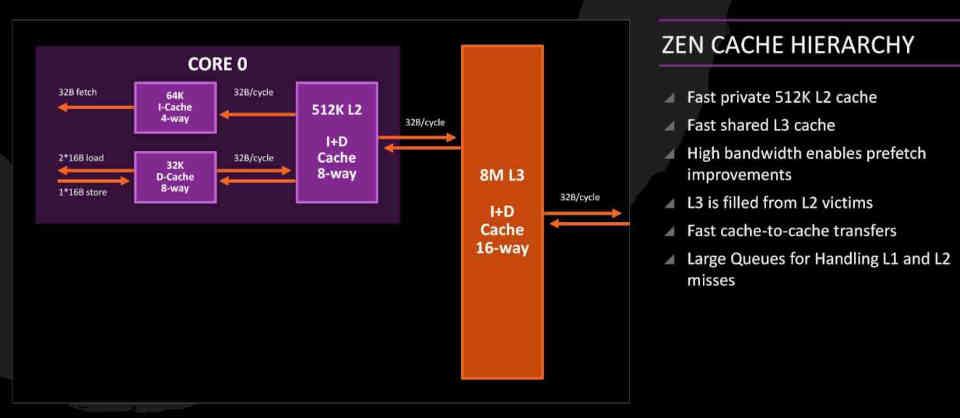

Nei core Zen, la cache L3 è ciò che chiamiamo Victim Caché, di cui sono responsabili raccogliendo le righe della cache scartate dalla L2 invece di far parte del solito nascondiglio gerarchia. Vale a dire, nei core Zen i dati da cui provengono RAM non segue il percorso RAM → L3 → L2 → L1 o viceversa, ma segue invece il percorso RAM → L2 → L1 poiché la cache L3 funge da Victim Caché.
Nel caso dell'Infinity Cache, l'idea è di salvare le linee della cache L2 della GPU senza dover accedere alla VRAM , che consente all'energia consumata per istruzione di essere molto inferiore e quindi è possibile ottenere velocità più elevate. orologio.
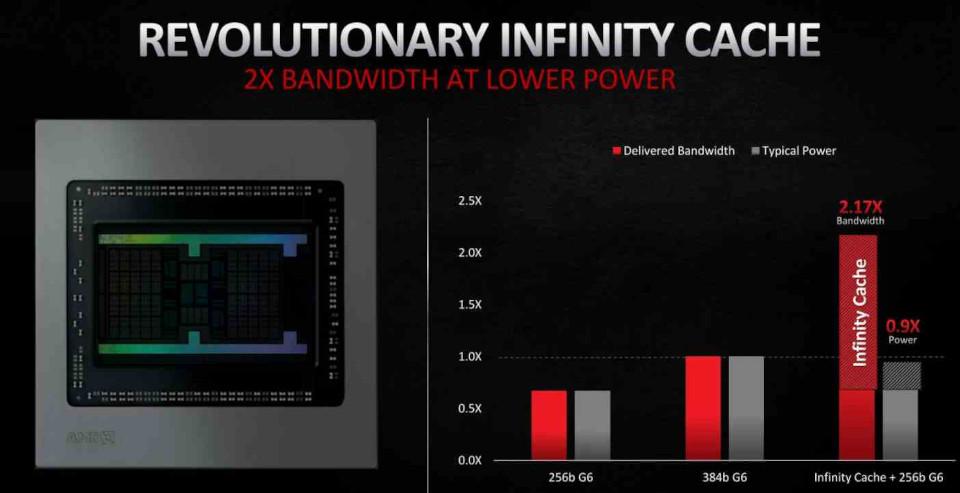
Tuttavia, sebbene la capacità di 128 MB possa sembrare molto elevata, non sembra sufficiente per evitare che tutte le linee scartate finiscano nella VRAM, poiché nel migliore dei casi riesce a salvare solo il 58% . Ciò significa che è molto probabile che nelle future iterazioni della sua architettura RDNA AMD aumenterà la capacità di questa Infinity Cache .