AMDLe architetture grafiche di Radeon hanno visto pochi cambiamenti negli ultimi anni rispetto alla concorrenza, in quanto da GCN lanciato nel 2012 siamo passati a RDNA nel 2019, che ha avuto un recente rinnovamento con RDNA. Ma qual è stata davvero l'evoluzione delle GPU AMD? Continua a leggere per conoscere le modifiche all'architettura da GCN a RDNA 2.
Mentre NVIDIA ne ha avute molte diverse GPU architetture negli ultimi anni, AMD è tradizionalmente più conservatrice, mantenendo la stessa architettura GPU con piccoli ritocchi per anni. L'abbiamo visto con GCN, che è stata l'architettura della GPU AMD per diverse generazioni e lo stiamo vedendo con RDNA, dove le roadmap indicano già l'esistenza di un futuro RDNA 3 con meno modifiche rispetto a quelle che vedremo in NVIDIA Lovelace. e Hopper.


Ma non guarderemo al futuro come Prometeo, ma per essere più di Epimeteo e guardare sia al passato che al presente e lo faremo nel caso di AMD per sapere davvero come le diverse architetture di AMD si sono evoluti. Il confronto non è quindi a livello di generazioni, né tra schede grafiche tra di loro, ma per capire come sia andata l'evoluzione da GCN a RDNA 2.
L'evoluzione da GCN a RDNA
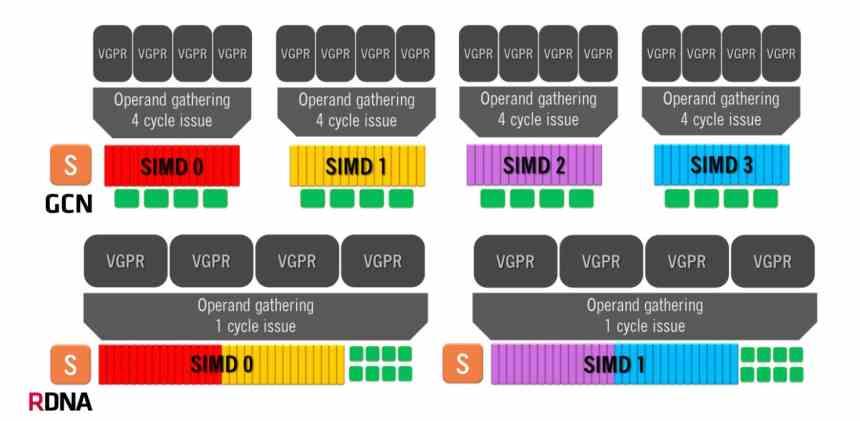
L'architettura Graphics Compute Next fa uso di una Compute Unit composta da 4 gruppi SIMD di 16 ALU ciascuno, che gestisce onde di 64 elementi. Ciò significa che nello scenario migliore, in cui un'istruzione viene risolta per ciclo, l'architettura GCN richiederà 4 cicli di clock per onda a 64 elementi.
D'altra parte, le architetture RDNA hanno un funzionamento diverso, poiché abbiamo due gruppi di 32 ALU e la dimensione delle onde è passata da 64 elementi a 32 elementi. La stessa dimensione che NVIDIA utilizza nelle sue GPU, quindi ora il tempo minimo per onda è di 1 singolo ciclo perché abbiamo tutte e 32 le unità di esecuzione in esecuzione in parallelo. Sebbene il numero medio di istruzioni risolte sia ancora 64, si tratta di un'organizzazione molto più efficiente.
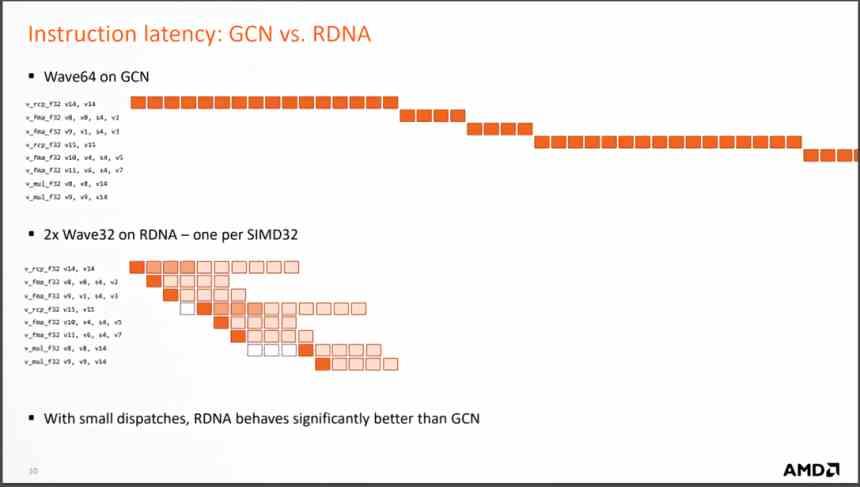
Ma il cambiamento più importante è il cambiamento nell'esecuzione delle istruzioni che arrivano da ogni onda, poiché RDNA le risolve in molti meno cicli, il che significa che il numero medio di istruzioni per ciclo che vengono risolte è molto più grande. e con esso il CPI medio aumenta.
In cosa si traduce? Ebbene, poiché sono necessarie molte meno unità di calcolo per ottenere le stesse prestazioni, meno unità di calcolo significano una GPU più piccola per ottenere le stesse prestazioni. In realtà AMD ha iniziato a progettare RDNA non appena ha visto una GTX 1080 con "solo" 40 SM che spazzava il pavimento con le unità di elaborazione AMD Vega 64. Quello è stato il punto in cui hanno visto come l'architettura GCN non dava più di se stessa.
Evoluzione del sistema di cache

Per comprendere l'evoluzione da un'architettura grafica all'altra, è importante conoscere il sistema di cache e come si è evoluto da una generazione all'altra.
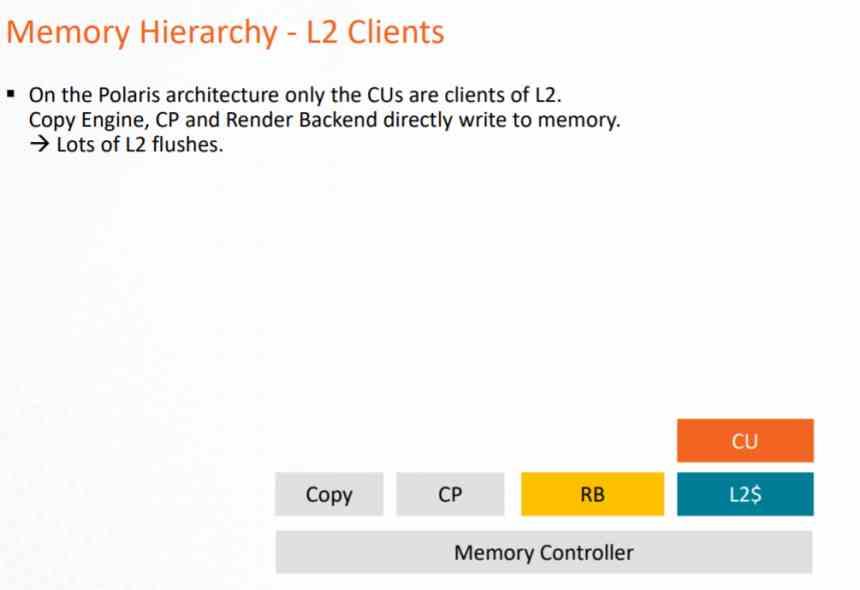
Nell'architettura GCN, il sistema di cache poteva essere utilizzato solo dalla pipeline di elaborazione, poiché i Pixel Shader quando eseguiti esportano sul ROPS e questi direttamente sulla VRAM, il che presuppone un carico molto grande sulla VRAM e un consumo di energia molto elevato .

Questo problema è stato risolto alla fine della vita di questa architettura con AMD Vega, dove sia il ROPS che l'unità raster comunicavano alla cache L2 in modo da ridurre il carico sul bus dati verso la VRAM. Ma soprattutto per applicare il DSBR o Tiled Caching, che consiste nell'adottare il Tile Rendering, ma in parte e che NVIDIA aveva già adottato in Maxwell.

In RDNA il cambiamento principale è stato quello di far diventare tutto client L2, ma aggiungendo una cache intermedia che è L1, in questo modo è cambiata la nomenclatura.
- La cache L1 inclusa in Compute Units diventa la cache L0, con la stessa funzionalità.
- Viene aggiunta una cache L1, che è intermedia tra la cache L0 e la cache L2.
- Tutti gli elementi della GPU ora passano attraverso la cache L2.
Tutte le operazioni di scrittura vengono eseguite direttamente sulla cache L2, mentre la cache L1 è di sola lettura. Questo viene fatto per evitare di implementare un sistema di coerenza più complesso sulla GPU che occuperebbe un gran numero di transistor. Poiché grazie alla cache L1 di sola lettura è possibile concedere i dati a più client all'interno della GPU contemporaneamente.
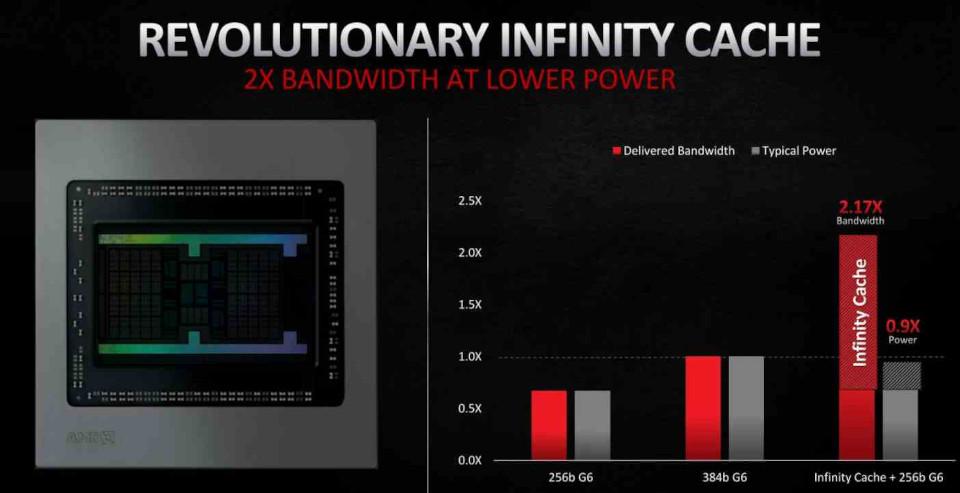
In RDNA 2 l'inclusione più importante è stata sotto forma di Infinito Cache, che agisce non come una cache L3 convenzionale ma come una Victim Cache, adottando le linee di cache scartate dalla cache L2, in questo modo si evita che questi dati cadano nella VRAM, cosa che ne facilita il recupero e, come vedremo in seguito , riduce il costo energetico di alcune operazioni, il che lo rende un elemento chiave per i miglioramenti in RDNA 2.
L'ubicazione dei dati è importante per quanto riguarda il consumo di energia. Poiché maggiore è la distanza che un dato deve percorrere, maggiore è il consumo di energia. È qui che entra in gioco Infinity Cache, che consente di operare con i dati con un consumo molto inferiore.
RDNA 2, un'evoluzione minore

RDNA 2, d'altra parte, è una versione leggermente migliorata di RDNA e non un cambiamento meno radicale, quindi AMD sarebbe tornata alla strategia di lanciare continui miglioramenti sulla stessa architettura. Si dice che AMD abbia rilasciato RDNA durante la seconda metà del 2019 come soluzione temporanea mentre finivano di lucidare RDNA 2 che è la versione già finita dell'architettura e completamente compatibile con DirectX 12 Ultimate.
Se parliamo in termini di calcolo, RDNA 2 non ha alcun vantaggio rispetto a RDNA e i miglioramenti sono stati apportati piuttosto in elementi diversi dalla parte incaricata di eseguire gli shader.
- L'unità texture è stata migliorata ed è stata aggiunta un'unità di intersezione dei raggi per Ray Tracing.
- Le unità ROPS e raster sono state migliorate per supportare l'ombreggiatura a velocità variabile.
- La GPU ora supporta velocità di clock più elevate.
- Inclusione dell'Infinity Cache per ridurre il consumo energetico di alcune istruzioni.
Una delle chiavi per poter ottenere una maggiore velocità di clock in un processore è la super-segmentazione della pipeline, ma questo è qualcosa che non può essere fatto nell'unità shader di una GPU allo stesso modo di un CPU. Ciò che AMD ha fatto internamente è misurare il consumo di energia di ogni istruzione che l'unità di calcolo può eseguire. Poiché ci sono istruzioni che consumano meno energia, possono essere eseguite a una velocità di clock più elevata, ciò consente di raggiungere velocità di picco più elevate nel momento in cui eseguirle.