DirectX è un'API che è stata con noi da allora Windows 95, è un'API di alto livello che rappresenta astrattamente diversi componenti del PC per facilitare la comunicazione dei programmi con le diverse periferiche. DirectML è uno dei rami di DirectX 12 pensato per facilitare l'uso di unità specializzate in intelligenza artificiale che sono state implementate nell'hardware negli ultimi anni.
Con l'arrivo delle console di nuova generazione in combinazione con il AMD RX 6000 abbiamo finalmente entrambi i produttori di schede grafiche con GPU in grado di eseguire algoritmi progettati per l'IA, tuttavia, l'approccio di entrambe le società è diverso. Mentre NVIDIA cerca di legare gli sviluppatori a librerie destinate esclusivamente al loro hardware, AMD ha scelto di non sviluppare i propri strumenti e di utilizzare il Microsoft Diretto M L API .

Tenendo conto delle due console di nuova generazione, PlayStation 5 e Xbox Serie X, poi è chiaro che quando si parla di utilizzo di algoritmi di intelligenza artificiale nei giochi allora AMD sta per vincere, ma dobbiamo partire dall'idea che DirectML non è progettato per hardware specifico ed è completamente indipendente dalla piattaforma.
DirectML funziona con qualsiasi tipo di processore
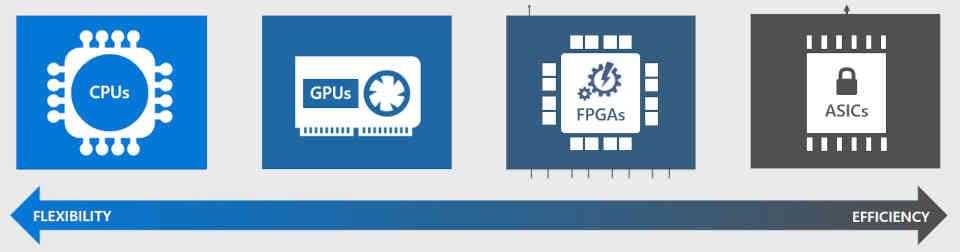
DirectML si basa sull'idea che possiamo eseguire qualsiasi tipo di istruzione su qualsiasi tipo di processore, ma non tutte sono ugualmente efficienti, questo significa che alcune architetture saranno più efficienti di altre durante l'esecuzione di questi algoritmi.
Il tipo di unità più veloce è chiamato ASIC, si tratta di processori neurali (NPU) le cui ALU sono array sistolici e sono ottimizzate per eseguire questi algoritmi più rapidamente, esempi di questo tipo di unità sono i seguenti:
- Il tensore core di NVIDIA RTX
- Le NPU dei diversi SoC per smartphone
Il secondo tipo di unità sono gli FPGA configurati come se fossero ASIC, ma a causa della maggiore area degli FPGA e della minore velocità di clock sono meno efficienti.
Il terzo tipo sono le GPU, queste non hanno unità specializzate, ma si tratta piuttosto di eseguire gli algoritmi di AI come se fossero programmi Compute Shader, non sono efficienti come un FPGA o un ASIC, ma sono molto più efficienti di un CPU a quando si esegue questo tipo di algoritmo.

DirectML è progettato per utilizzare un ASIC se è nel sistema, se non viene trovato cercherà il file GPU per eseguirlo e in definitiva la CPU come una risorsa molto disperata. D'altra parte, librerie come NVIDIA cudNN funzioneranno solo con la GPU NVIDIA e attraverso i Tensor Core, ignorando altri tipi di unità nel sistema.
Super risoluzione

È conosciuto come Super risoluzione tramite AI quando si utilizza un algoritmo di intelligenza artificiale per generare una versione ad alta risoluzione di una data immagine , che ha il vantaggio di poter aumentare la risoluzione di output dei giochi senza doverlo renderizzare in modo nativo e consumare molte meno risorse: Super-Resolution vale solo quando il tempo per renderizzare a una risoluzione nativa è maggiore del tempo per eseguire il rendering a una risoluzione inferiore, ripetere la scansione ed eseguire l'algoritmo di ridimensionamento tramite AI.

Tieni presente che esistono due tipi di algoritmi di super risoluzione:
- Quelli del primo tipo lo sono usato nei film e quindi in frame già predefiniti che vengono aggiornati ogni x ms e in cui la loro decodifica più il ridimensionamento tramite AI viene eseguita con pochissima potenza richiesta. I sistemi di scaling automatico di alcuni televisori si basano su algoritmi di questo tipo.
- Il secondo tipo è quello con cui abbiamo visto DLSS di NVIDIA , nei giochi in tempo reale non esiste una versione predefinita dell'immagine in memoria, deve essere generata e quindi il processore che esegue l'algoritmo ha una pochi millisecondi per applicarlo. Tuttavia, è necessario chiarire che ciò che fa DLSS non è esclusivo di NVIDIA e chiunque può farne una controparte.
Il primo tipo è molto facile da addestrare poiché possiamo usare la versione a risoluzione più alta di un film in modo che l'IA possa fornire feedback durante il processo di addestramento. Ma in un videogioco è diverso, ogni frame non esiste prima quindi la formazione utilizzata è molto più complessa e richiede una supervisione continua, quindi, ad esempio, NVIDIA deve utilizzare i supercomputer Saturn-V per addestrare l'IA.

L'altro problema è durante l'esecuzione dell'algoritmo ottenuto con l'addestramento. Nel caso di DLSS 2.0. Un tipo di algoritmo del secondo tipo, i suoi Tensor Core hanno una media di 1.5 ms per eseguire l'intero processo, il che significa che ha bisogno di una potenza elevata per farlo a quella velocità, da qui l'enorme quantità di TFLOPS nei Tensor Core .
In DirectML è possibile applicare un algoritmo dello stesso stile, ma bisogna capire che meno potente è la parte che applica l'algoritmo, quindi più veloce dovrà essere la GPU rispetto al rendering della scena in anticipo per dare l'unità tempo a disposizione per applicare l'algoritmo di super risoluzione.
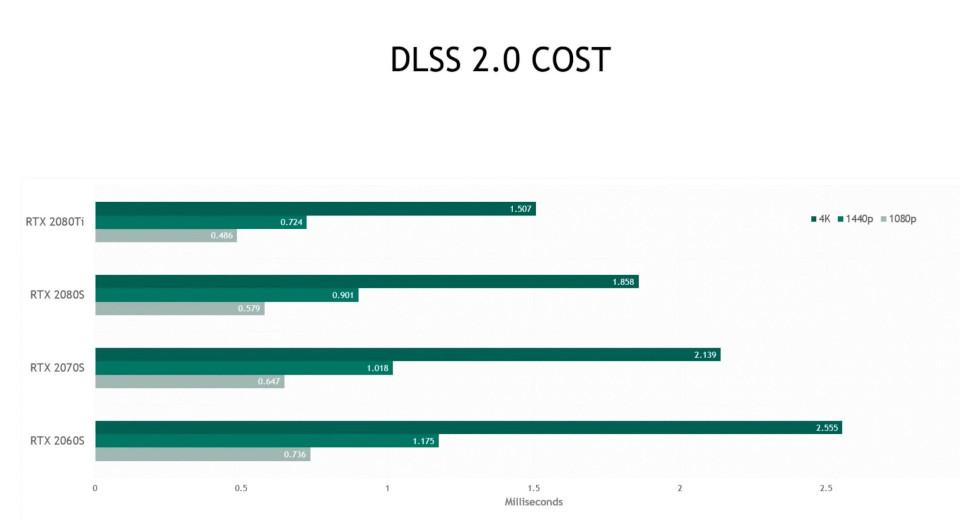
Alla fine potremmo assistere alla fine del DLSS 2.0 a favore dell'algoritmo DirectML, ma resta da vedere se le GPU di AMD sono abbastanza veloci e resistere a NVIDIA . Nucleo tensoriale NVIDIA può eseguire calcoli FP16 e Int8 con un rapporto 4: 1 rispetto a qualsiasi GPU AMD con specifiche simili. Non sorprende che DirectML sia stato introdotto per la prima volta utilizzando i Tensor Core di un file NVIDIA Volta .
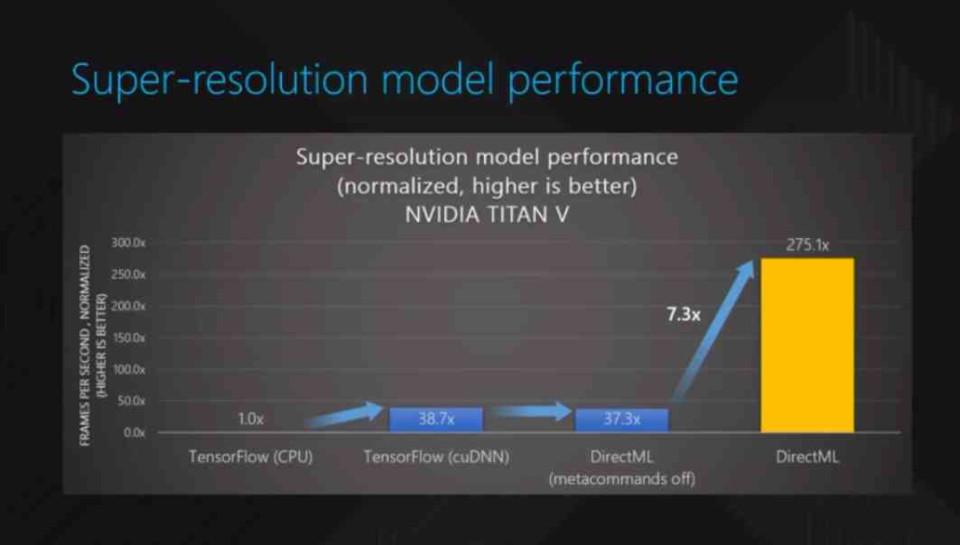
Si deve tener conto che questi algoritmi non generano l'immagine in 4K nativo, ma piuttosto fanno una stima del valore di ogni pixel e si deve tener conto che esiste un range di errore che può portare a rappresentazioni che sono lontano da quello che ci si aspetta. Ecco perché i giochi che supportano questo tipo di tecnica non lo fanno subito e il supporto è limitato per la stragrande maggioranza dei giochi, ma quando l'IA genera immagini molto vicine al 4K nativo, i risparmi sono significativi.