
Super-resolution algorithms executed from Gaming GPUs have become the spearhead of different Gaming GPU manufacturers. With the entry of Intel to this market they have not wanted to be left behind and have developed their own counterpart to the NVIDIA DLSS and the AMD FSR under the name of Intel Xe Super Sampling. How does the Intel XeSS work and how does it differ from its rivals?
Along with the definitive presentation of what was previously known as Xe-HPG and which has been renamed ARC Alchemist. Intel not only told us about its new generation of graphics architectures, but about the commitment to artificial intelligence for the future, both in CPU and GPU. In the specific case of their GPUs, they have developed an algorithm called Intel XeSS, which comes to compete against AMD’s FSR and NVIDIA’s DLSS. Where they coincide in objectives, but not the way to work between the three algorithms.
Why do we need super resolution algorithms?

When processing graphics, each vertex, fragment or pixel is assigned at least one execution thread on the GPU and it must be taken into account that the number of pixels is much greater than the number of vertices in the scene. This means that when the resolution is increased, what happens is that we end up increasing in the same way the amount of instructions to be executed within the GPU, as well as its data, and therefore the bandwidth also increases.
The problem is that this implies having a much larger GPU in size, not only due to the increase in the different units, but also due to the fact that by requiring a higher bandwidth it also requires more complex memory controllers. Let’s not forget that these are placed on the outer perimeter of any processor and therefore have to do with its size. And especially we cannot forget the high consumption of the memories used in gaming graphics cards.
Super-resolution algorithms such as AMD FSR, Intel Xess, and NVIDIA DLSS seek to solve this problem. They rely on increasing hardware by a minuscule percentage, less than 10%, in order to achieve performance that would otherwise traditionally require doubling the size of a GPU. To all this we cannot forget Ray Tracing, whose algorithm even making use of acceleration structures such as BVH works at the pixel level, hence super-resolution algorithms have been adopted as an essential part of real-time graphics.
What is the Intel XeSS?

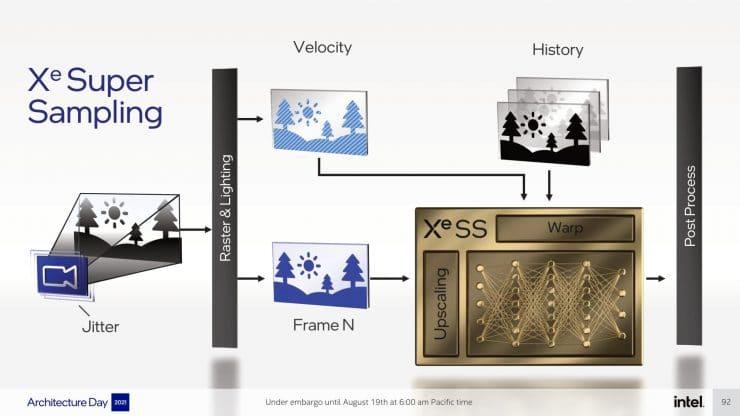
Intel is going to offer two versions of the Intel XeSS and therefore two different algorithms. In both cases we are talking about an algorithm that is based on Deep Learning and computer vision and therefore an inference neural network is used that predicts the image at a higher resolution, with more pixels, from a lower resolution. and therefore fewer pixels.
The first variant makes use of the SIMD over register or SWAR that some GPUs have, this mechanism consists in that the 32-bit ALU can be subdivided into two 16-bit ALUs performing the same instruction or 4 of 8 bits. Well, the DP4A format consists of grouping 4 8-bit operands in a 32-bit register. So one of the XeSS variants will be able to run on Intel’s integrated GPUs, as well as any GPU that supports this format, since Intel will make it open source.
The second variant of the Intel XeSS on the other hand is more complex, since it works using the Tensor units of the Intel Arc called XMX, but it does not work in NVIDIA GPUs with Tensor Cores. Intel’s explanation is none other than that NVIDIA keeps under lock and key the way its GPU’s Tensor Cores work, the use of XMX units and the ability to perform extremely fast matrix calculations required by convolutional networks. Since it does not work on AMD GPUs and AMD’s GPUs currently lack such units, the second variant would be exclusively for Intel GPUs.
How is Intel XeSS different from solutions from AMD and NVIDIA?
In fact, it would be between the two worlds, since despite the fact that it is a solution based on Deep Learning like NVIDIA’s, from Intel they have affirmed that they are going to publish the code of its implementation as AMD has done with its FidelityFX Super Resolution. So developers can apply it more easily in their games and applications. It is a strategy that in the case of the AMD algorithm has allowed its implementation beyond what is expected, such as emulators of old consoles, Linux applications and even games that would not have received a patch of this type.
Like the NVIDIA DLSS, it also takes into account the temporality data, which is obtained from the information of the previous frames, this is something that the AMD FSR does not do, since the red solution only takes the information of the current frame. Let’s not forget either that the AMD algorithm is not based on artificial intelligence and therefore does not require training while NVIDIA’s does. Well, Intel has claimed that XeSS doesn’t either, and this is where things get interesting.
Why doesn’t the XeSS need training?

One of the things that differentiates the XeSS from the NVIDIA DLSS is that the former requires no training . In the training process we have two elements working at the same time, the first one is in charge of predicting and the second of supervising. When a prediction by the convolutional neural network is incorrect then the supervisory hardware returns the negative answer and the neural network is refined more and more until it learns to make the correct predictions.
In a video game where not a single frame is repeated, that is much more difficult to do than in a movie where there are always the same frames. That is why what is usually done is to train the neural network with supervision. Which consists of executing the game at high resolution in a system, scaling the image down in a process that adds noise and from this data create a neural network in the system that will have to make the inference so that it can generate the image to higher resolution.
Intel states that with XeSS no training is necessary and therefore no supervision by an external system is necessary. The reality of this statement is none other than the training process is performed within the GPU’s own hardware instead of being performed on remote hardware. For this, what the GPU does is run the game in two simultaneous instances at the same time, one acting as a supervisor and in the other the neural network is tuned. This allows those who implement the Intel Xess in their games and applications to fine-tune the algorithm and not depend on external servers.
The secret ingredients that Intel has integrated into its GPUs for the XeSS
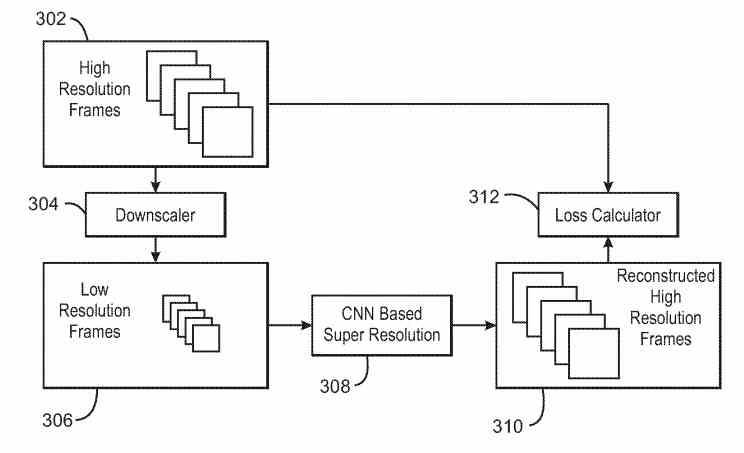
To speed up the training, Intel will include a series of additional units in the GPU , such as the Downsampler , the unit to obtain the same image at a lower resolution and the one that calculates the loss of signal quality. Not to forget the Backpropagator , which is key during the training process from the GPU itself. At the moment we do not know where these units are for training the convolutional neural network, but we assume that they are a support unit apart from what is the rendering engine, but within the GPU itself.
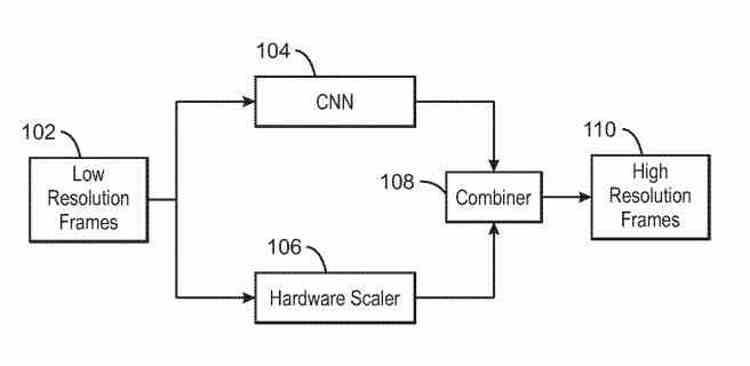
Super-resolution algorithms often use supersampling algorithms in the process to get the image at higher resolution. Some make use of bicubic interpolation, while others like the FSR use a Lanczos variant, although all of them run on the Shader units of the GPU and therefore end up derating them. Intel would have included scaling units , which would be capable of executing one or more supersampling algorithms automatically and would free the Xe Core SIMD units from this task, allowing them to be used elsewhere where they are also needed.
So in conclusion, the Intel XeSS adds a series of additional hardware that until now was unprecedented in GPUs. Not only to speed up these algorithms, but also to increase compatibility and facilitate their implementation in the different games on the market. Be it the latest news or games with a few years behind them. So it can be said that Intel with the XeSS has taken good note of the shortcomings and limitations of its rivals.