La chute de Facebook dans le monde qui s'est produit lundi a été un avant et un après dans l'entreprise, et c'est qu'ils ont été complètement déconnectés d'Internet pendant plus de 5 heures, quelque chose de sans précédent pour l'une des plus grandes entreprises du monde. Maintenant que la plateforme Facebook, Whatsapp et Instagram ont récupéré à 100% du crash qui s'est produit lundi, l'équipe Facebook a publié des détails sur la façon dont le crash s'est produit, pourquoi il s'est produit et aussi comment ils ont réussi à le réparer. Vous voulez connaître tous les détails sur le plus gros crash de l'histoire de Facebook jusqu'à présent ?

Comment fonctionne Facebook et pourquoi sa chute totale s'est-elle produite ?
Facebook a indiqué que l'interruption totale de service dans le monde était due à une défaillance du système qui gère la capacité du backbone de l'entreprise, ce backbone est le "backbone" du réseau Facebook, pour connecter tous les centres de données que Facebook a répartis tous à travers le monde, qui se composent de milliers de serveurs et de centaines de kilomètres de fibre optique, puisqu'ils relient également ses centres de données avec des câbles sous-marins. Certains centres de données Facebook ont des millions de serveurs qui stockent les données et ont une charge de calcul élevée, mais dans d'autres cas, les installations sont plus petites et sont chargées de connecter l'épine dorsale à Internet en général pour que les gens puissent utiliser leurs plateformes.
Lorsqu'un utilisateur comme nous se connecte à Facebook ou Instagram, la demande de données voyage de notre appareil vers l'installation la plus proche géographiquement, pour ensuite communiquer directement avec le backbone pour accéder aux plus grands centres de données, c'est là qu'il récupère les informations demandées et est traité, pour que nous le voyions sur le smartphone.

Tout le trafic de données entre les différents centres de données est géré par des routeurs, qui déterminent où les données entrantes et sortantes doivent être envoyées. Dans le cadre de leur travail quotidien, l'équipe d'ingénierie de Facebook doit maintenir cette infrastructure et effectuer des tâches telles que la mise à niveau des routeurs, la réparation des lignes de fibre ou l'ajout de capacité sur certains réseaux. C'était le problème avec le crash mondial de Facebook lundi.
Pendant les travaux de maintenance, une commande a été envoyée avec l'intention d'évaluer la disponibilité de la capacité globale du backbone, mais elle a accidentellement coupé toutes les connexions du backbone, déconnectant tous les centres de données Facebook dans le monde. Généralement, Facebook utilise des systèmes pour auditer ces types de commandes et atténuer ou éviter de telles erreurs, mais une erreur (bug) dans cet outil d'audit et de contrôle des modifications a empêché l'exécution de la commande d'être arrêtée, puis tout s'est effondré.
Que s'est-il passé sur Facebook lorsque j'ai exécuté la commande ?
Dès que la commande a été exécutée, cela a provoqué une déconnexion totale des connexions Internet et du centre de données, c'est-à-dire que nous ne pouvions accéder à aucun des services Facebook car ils n'étaient plus visibles sur Internet. De plus, cette déconnexion totale a provoqué une deuxième panne catastrophique du système, plus précisément dans le DNS. L'une des tâches effectuées par les petites installations de centres de données est de répondre aux requêtes DNS, ces requêtes sont répondues par des serveurs de noms faisant autorité qui ont des adresses IP bien connues et qui sont annoncés au reste d'Internet à l'aide du protocole BGP.
Pour garantir un fonctionnement plus fiable, Facebook demande aux serveurs DNS de désactiver ces publicités BGP s'ils ne peuvent pas communiquer eux-mêmes avec les centres de données de Facebook, car cela indique que la connexion réseau ne fonctionne pas correctement. Avec la perturbation totale de la dorsale, ces serveurs DNS ont supprimé les publicités BGP. Le résultat est que les serveurs DNS de Facebook sont devenus inaccessibles même s'ils fonctionnaient parfaitement, pour cette raison, le reste du monde ne pouvait pas accéder aux services Facebook.
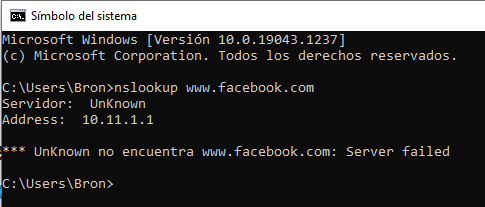
Logiquement, tout ce processus s'est déroulé en quelques secondes, tandis que les ingénieurs de Facebook ont essayé de comprendre ce qui se passait et pourquoi, ils ont été confrontés à deux problèmes critiques :
- Il n'était pas possible d'accéder aux centres de données normalement, car les réseaux étaient totalement en panne dès le premier problème.
- Le crash du DNS a cassé de nombreux outils internes qui sont couramment utilisés pour enquêter et résoudre des problèmes de ce type.
L'accès au réseau principal et au réseau hors bande était en panne, rien ne fonctionnait, ils ont donc dû envoyer physiquement une équipe de personnes au centre de données pour résoudre le problème et redémarrer le système. Cela a pris beaucoup de temps car la sécurité physique dans ces centres est maximale, en effet, comme le confirme Facebook, il leur est même difficile d'y accéder physiquement pour y apporter des modifications, afin d'éviter ou d'atténuer d'éventuelles attaques physiques sur leur réseau. Cela a pris beaucoup de temps jusqu'à ce qu'ils puissent s'authentifier auprès du système et voir ce qui se passait.
Revenir à la vie… mais petit à petit pour ne pas jeter tout le système
Une fois la connectivité backbone restaurée dans les différentes régions des datacenters de Facebook, tout fonctionnait à nouveau correctement, mais pas pour les utilisateurs. Afin d'éviter un effondrement de leurs systèmes dû au grand nombre d'utilisateurs qui voulaient entrer, ils ont dû activer les services très petit à petit, pour éviter de causer de nouveaux problèmes dus à l'augmentation exponentielle du trafic.
L'un des problèmes est que les centres de données individuels utilisaient très peu d'énergie électrique, l'inversion soudaine de tout le trafic pourrait rendre le réseau électrique incapable d'absorber autant d'énergie supplémentaire et pourrait également mettre les systèmes électriques en danger. Je les ai mis en cache. Facebook s'est entraîné pour ce type d'événements, ils savaient donc parfaitement ce qu'ils devaient faire pour éviter plus de problèmes en cas de crash mondial comme celui qui s'est produit. Bien que Facebook ait simulé de nombreux problèmes et plantages de leurs serveurs et réseaux, ils n'avaient jamais envisagé une baisse totale de la dorsale, ils ont donc déjà déclaré qu'ils chercheraient un moyen de simuler cela dans un avenir très proche pour l'empêcher de venir. arrière. passer et cela prend tellement de temps à réparer.
Facebook a également indiqué qu'il était très intéressant de voir comment les mesures de sécurité physique pour empêcher les accès non autorisés ralentissaient énormément l'accès aux serveurs alors qu'ils tentaient de se remettre de cet échec à l'échelle mondiale. Dans tous les cas, il vaut mieux se protéger au quotidien de ces types de problèmes et avoir une récupération un peu plus lente, que d'assouplir les mesures de sécurité des centres de données.