DLSS on yksi NVIDIA vastaan AMD, sitä tukevat pelit voivat saavuttaa suuremmat kuvataajuudet lähtöresoluutioilla, jos ilman tätä tekniikkaa ei olisi mahdollista. Tämä tosiasia on tehnyt NVIDIA RTX: n grafiikkasuorittimista nykyiset johtajat GPU markkinoilla, mutta NVIDIA DLSS: llä on ansa, ja aiomme kertoa sinulle, mikä se on.
Jos joudumme puhumaan NVIDIAn kahdesta keihäänkäristä sen GeForce RTX: lle, on selvää, että ne ovat Ray Tracing ja DLSS, ensimmäinen ei ole enää etu johtuen AMD: n RDNA 2: n toteutuksesta, mutta toinen on silti differentiaalielementti se antaa sille suuren edun, mutta kaikki ei ole sitä, mitä näyttää ensi silmäyksellä.

RTX: n DLSS riippuu tensorisydämistä
Ensimmäinen asia, joka meidän on otettava huomioon, on se, kuinka erilaiset algoritmit, joita kutsutaan yleisesti DLSS: ksi, hyödyntävät konsolilaitteistoa eivätkä mitään parempaa kuin analysoida GPU: n toimintaa, kun se renderöi kehystä DLSS: n ollessa aktiivinen ja ilman sitä.
Kaksi kuvakaappausta, jotka sinulla on näiden kuvien yläpuolella, vastaavat NVIDIA NSight -työkalun käyttöä, joka mittaa näytönohjaimen kunkin osan käyttöä ajan mittaan. Kaavioiden tulkinnassa on otettava huomioon, että pystyakseli vastaa GPU: n kyseisen osan käyttöastetta ja vaaka-akseli aikaa, jolloin kehys renderöidään.
Kuten näette, ero NSightin molempien kuvakaappausten välillä on se, että yhdessä niistä näkyy GPU: n kunkin osan käyttöaste DLSS: ää käytettäessä ja toisessa ei. Mikä on ero? Jos emme katso tarkasti, näemme, että DLSS: n käyttöä vastaavassa kuvassa Tensor-ytimiä vastaava kaavio on tasainen paitsi kaavion lopussa, jolloin nämä yksiköt aktivoidaan.
DLSS ei ole muuta kuin superresoluutioalgoritmi, joka ottaa kuvan tietyllä tulotarkkuudella ja tuottaa prosessista korkeamman resoluution version samasta kuvasta. Siksi Tensor-ytimet aktivoidaan viimeisenä, koska ne vaativat GPU: n renderöimään kuvan ensin.
DLSS-käyttö NVIDIA RTX: llä

DLSS vie enintään 3 millisekuntia aikaa kehyksen renderoimiseksi, riippumatta siitä, millä kuvanopeudella peli on käynnissä. Jos esimerkiksi haluamme käyttää DLSS: ää peleissä 60 Hz: n taajuudella, GPU: n on ratkaistava kukin kehys:
(1000ms/60Hz) -3ms.
Toisin sanoen 13.6 ms: n aikana vastineeksi tulemme saamaan suuremman kehysnopeuden lähtöresoluutiolla kuin saisimme, jos tuottaisimme lähtöresoluution natiivisti GPU: lle.

Oletetaan, että meillä on kohtaus, jonka haluamme tehdä 4K: lla. Tätä varten meillä on määrittelemätön GeForce RTX, joka saavuttaa mainitulla resoluutiolla 25 kuvaa sekunnissa, joten se renderöi kaikki näistä 40 ms: lla, tiedämme, että sama GPU voi saavuttaa 5o, 20 ms: n kuvataajuuden 1080p: ssä. Hypoteettisen GeForce RTX: n skaalaus 2.5p: stä 1080K: iin kestää noin 4 ms, joten jos aktivoimme DLSS: n saadaksemme 4K-kuvan yhdestä 1080p: stä, kukin DLSS-kehys kestää 22.5 ms. Tämän avulla olemme pystyneet renderöimään kohtauksen nopeudella 44 kuvaa sekunnissa, mikä on suurempi kuin 25 kuvaa, jotka saataisiin renderoinnilla natiiviresoluutiolla.
Toisaalta, jos grafiikkasuoritin vie yli 3 millisekuntia tarkkuushyppyyn, DLSS ei aktivoidu, koska se on NVIDIA: n RTX-näytönohjaimissa asettama aikaraja, jotta he voivat käyttää DLSS-algoritmeja. Tämä tekee alemman tason GPU: ista rajoitetun resoluution, jolla ne voivat käyttää DLSS: ää.
DLSS hyötyy nopeista tensorisydämistä

- Tensorisydämet ovat välttämättömiä DLSS: n toteuttamiseksi , ilman niitä ei olisi mahdollista suorittaa nopeudella, joka käy NVIDIA RTX: ssä, koska algoritmi, jota käytetään resoluution lisäämiseen, on se, mitä me kutsumme konvoluutiohermoverkoksi, jossa Composition, emme aio mennä Tässä artikkelissa sanotaan vain, että he käyttävät suurta määrää matriisikertoja ja tensoriyksiköt ovat ihanteellisia laskettaessa numeerisilla matriiseilla, koska ne ovat yksikön tyyppiä, joka suorittaa ne nopeammin.
Elokuvan tapauksessa dekooderit lopulta tuottavat alkuperäisen kuvan kuvapuskurissa useita kertoja nopeammin kuin se näytetään näytöllä, joten skaalaamiseen on enemmän aikaa ja siksi tarvitset paljon vähemmän tietojenkäsittelyä teho. Toisaalta videopelissä sitä ei ole tallennettu tukeen, kuten seuraava kuva on, mutta GPU: n on luotava se, mikä lyhentää aikaa, jonka skaalaimen on toimittava.
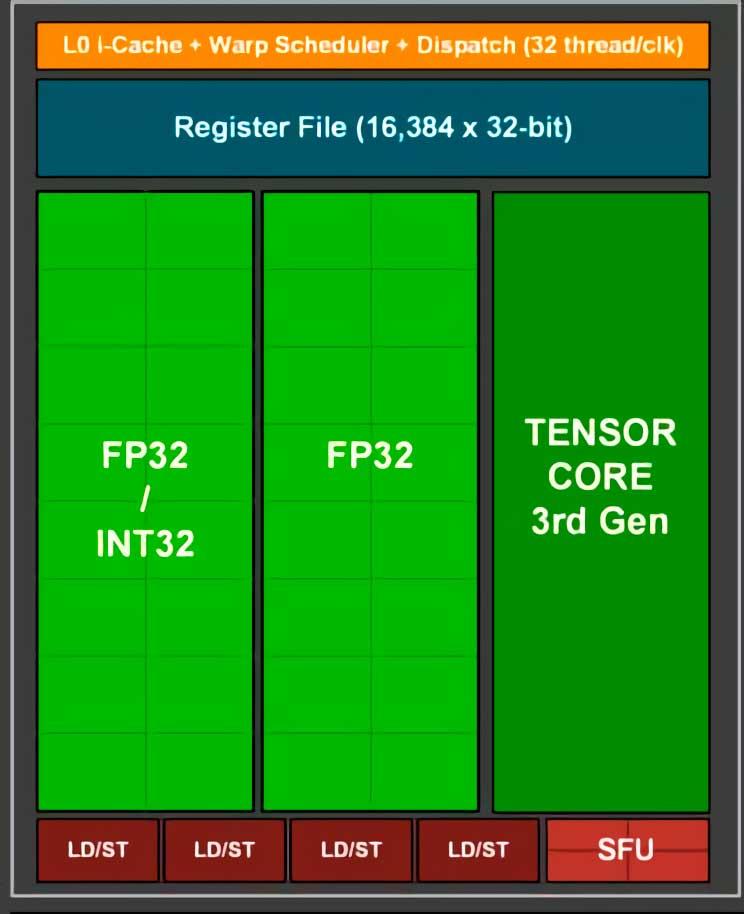
Jokainen näistä Tensorisydämet löytyvät jokaisen SM-yksikön sisällä ja riippuen käytettävästä näytönohjaimesta, sen laskentakapasiteetti vaihtelee vaihtelemalla SM: ien määrää GPU: ta kohti, ja näin ollen se tuottaa skaalatun kuvan lyhyemmässä ajassa. Koska DLSS käynnistyy renderoinnin lopussa , DLSS: n käyttöön tarvitaan nopea nopeus , minkä vuoksi se eroaa muista superresoluutioalgoritmeista, kuten elokuvien ja kuvien mittakaavassa käytetyistä algoritmeista.
Kaikki NVIDIA RTX -laitteet eivät toimi samalla tavalla DLSS: ssä
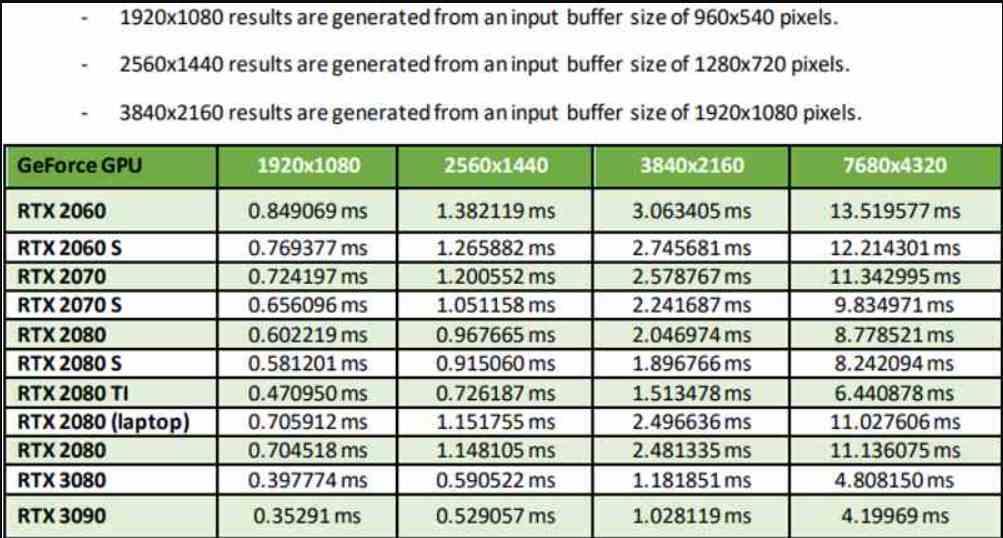
Tämä näkemäsi taulukko on otettu NVIDIA: n omasta dokumentaatiosta, jossa tulotarkkuus on kaikissa tapauksissa neljä kertaa pienempi kuin lähtöresoluutio, joten olemme suorituskykytilassa. On selvennettävä, että on olemassa kaksi muuta tilaa, laatutila antaa paremman kuvanlaadun, mutta vaatii puolet pikseleistä, kun taas Ultra Performance -tila skaalaa yhdeksän kertaa, mutta sillä on huonoin kuvanlaatu. kaikista.
Kuten taulukosta näet, suorituskyky vaihtelee paitsi GPU: n mukaan myös, jos otamme huomioon käyttämämme GPU: n. Tämän ei pitäisi olla mikään yllätys sen jälkeen, mitä olemme aiemmin selittäneet. Vähiten vaikuttava on kuitenkin se, että suorituskykytilassa RTX 3090 pystyy skaalautumaan 1080p: stä 4K: iin alle 1 ms: ssa. tällä on vastaava, joka johtuu loogisesta johtopäätöksestä ja että vaatimattomamman näytönohjaimen DLSS toimii aina huonommin.
Syynä tähän on selvä, vähemmän virtaa tarvitseva GPU ei vain tarvitse enemmän aikaa kehyksen renderoimiseksi, vaan jopa DLSS: n käyttämiseen. Onko ratkaisu Ultra Performance -tila, joka lisää pikselien määrää 9 kertaa? Ei, koska DLSS edellyttää, että lähtökuvalla on riittävä resoluutio, koska mitä enemmän pikseleitä näytöllä on, niin tietoa on enemmän ja skaalaus on tarkempaa.
Geometria, kuvanlaatu ja DLSS
![]()
GPU: t on suunniteltu siten, että Pixel / Fragment Shader -vaiheessa, jossa kunkin fragmentin pikselit ovat värillisiä ja tekstuureja käytetään, ne tehdään niin 2 × 2 pikselin fragmentilla. Useimmat GPU: t, kun he ovat rasteroineet kolmion, muuntavat sen pikselilohkoksi, joka jaetaan sitten 2 × 2 pikselilohkoksi, jossa kukin lohko lähetetään laskentayksikköön.
Seuraukset DLSS: lle? Rasteriyksikkö pyrkii hävittämään kaikki 2 × 2 palat laatikosta liian pieniksi, joskus vastaamaan kaukana olevia yksityiskohtia. Tämä tarkoittaa, että yksityiskohtia, jotka natiiviresoluutiolla nähdään ilman ongelmia, ei näy DLSS: n kautta saadussa tarkkuudessa, koska niitä ei ole skaalattavassa kuvassa.
Koska DLSS vaatii kuvan, jossa on mahdollisimman paljon tietoa syöttöviitteenä, se ei ole algoritmi, joka on suunniteltu tuottamaan kuvia erittäin korkealla resoluutiolla hyvin matalista, koska yksityiskohdat menetetään prosessissa.
Entä AMD, voiko se jäljitellä DLSS: ää?

Huhut FidelityFX: n superresoluutiosta ovat olleet verkossa jo kuukausia, mutta AMD: stä lähtien ne eivät ole vielä antaneet meille todellista esimerkkiä DLSS: n vastaavansa toiminnasta. Mikä tekee AMD: n elämästä niin vaikeaa? No, tosiasia, että tensorisydämet ovat ratkaisevia DLSS: lle ja AMD RX 600: ssa ei ole vastaavia yksiköitä, vaan pikemminkin, että laskentayksiköiden ALU: issa käytetään SIMD over register- tai SWAR-tiedostoja korkeamman suorituskyvyn saamiseksi FP16-muodoissa vähemmän tarkkoja. , mutta SIMD-asema ei ole systolinen matriisi tai kiristin.
Alusta alkaen puhumme nelinkertaisesta erosta NVIDIA: n hyväksi, mikä tarkoittaa, että samanlaisen ratkaisun luomisessa se alkaa huomattavasta nopeushaitasta, optimoinnista matriisien laskemiseksi toisistaan. Emme keskustele siitä, onko NVIDIA parempi kuin AMD tässä, mutta tosiasia, että AMD RDNA 4: ta suunniteltaessa ei antanut merkitystä tensoriyksiköille.
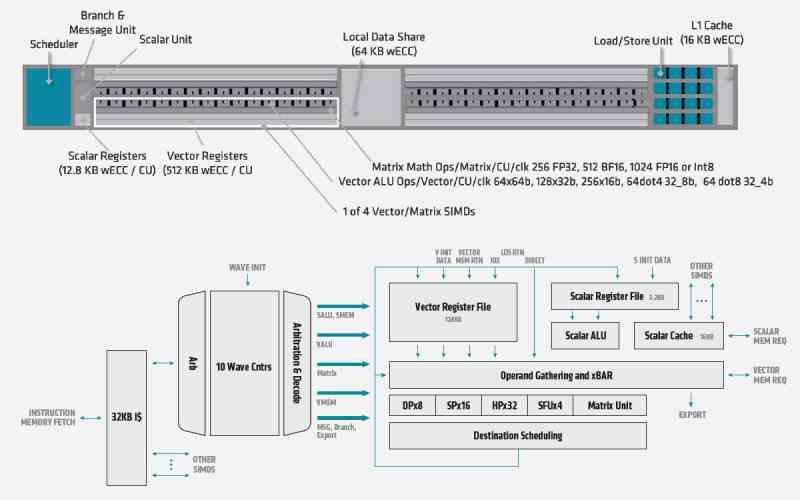
Johtuuko se vammaisuudesta? Ei, koska paradoksaalisesti AMD on lisännyt ne CDNA: han nimellä Matrix Core. Tällä hetkellä on varhaista puhua RDNA 3: sta, mutta toivotaan, että AMD ei tee enää samaa virhettä jättämättä yhtä näistä yksiköistä. Ei ole mitään järkeä tehdä ilman niitä, kun kustannukset laskentayksikköä tai SM: tä kohti ovat vain 1 mm 2 .
Joten toivomme, että kun AMD lisää algoritminsa Tensor-yksiköiden puuttumisen vuoksi, se ei saavuta NVIDIA: n tarkkuutta eikä nopeutta, mutta että AMD esittelee yksinkertaisemman ratkaisun, kuten suorituskykytilan, joka kaksinkertaistaa näytön pikselit.