Sirujen Multi-GPU:t ovat aivan nurkan takana, ja vaikka näemme ne ensin HPC-korttien muodossa ja siksi pelimarkkinoiden ulkopuolella, olemme jo pitkään tienneet, että kehitys on kohti monigrafiikkasuorittimiin perustuvien näytönohjainkorttien rakentamista. per sirut. Mutta mitä ne tuovat verrattuna perinteiseen monoliittiseen GPU? Lue lisää saadaksesi selville.

Arkkitehtuuri, josta keskustelemme tässä artikkelissa, ei ole vielä saatavilla markkinoilla, sitä ei ole edes esitelty, mutta se on viime vuosien kehitysten sekä monien GPU:n eri patenttien analyysin tulos. siruja että molemmat AMD, NVIDIA ja Intel ovat julkaisseet viimeisen kahden vuoden aikana. Siksi olemme päättäneet ottaa nämä tiedot ja syntetisoida, jotta sinulla on käsitys tämäntyyppisten GPU:iden toiminnasta ja mitä graafisia ongelmia ne tulevat ratkaisemaan.
Perinteinen 3D-renderöinti useilla GPU:illa

Useiden grafiikkakorttien käyttäminen niiden tehojen yhdistämiseen kunkin ruudun renderöimiseksi 3D-videopeleissä ei ole uutta, koska Voodoo 2:ssa 3dfx on mahdollista jakaa renderöintityö kokonaan tai osittain useiden näytönohjainkorttien kesken. Yleisin tapa tehdä se on vaihtoehtoinen kehysrenderöinti, jossa prosessori lähettää kunkin kehyksen näyttöluettelon vuorotellen kullekin GPU:lle. Esimerkiksi GPU 1 käsittelee kehyksiä 1, 3, 5, 7, kun taas GPU 2 käsittelee kehyksiä 2, 4, 6, 8 jne.
On myös toinen tapa renderöidä kohtaus 3D-muodossa, jaettu kehys renderöinti, joka koostuu useista GPU:ista, jotka renderöivät yhden kohtauksen ja jakavat työn, mutta seuraavilla vivahteilla: GPU on pää-GPU, joka lukee luettelon näyttöruudusta ja hoitaa loput. Liukuhihnan ensimmäiset vaiheet ennen rasterointia suoritetaan yksinomaan ensimmäisellä GPU:lla, kuten rasterointi, ja myöhemmät vaiheet suoritetaan tasaisesti jokaiselle GPU:lle.
Split Frame Rendering näyttää oikeudenmukaiselta tavan jakaa työtä, mutta nyt katsotaan, mitä ongelmia tämä menetelmä sisältää ja millä rajoituksilla se on.
Split Frame Renderingin rajoitukset ja mahdollinen ratkaisu

Jokainen GPU sisältää 2 kokoelmaa DMA-asemia, joista ensimmäinen pari voi samanaikaisesti lukea tai kirjoittaa tietoja järjestelmään RAM PCI Express -portin kautta, mutta monissa Crossfire- tai SLI-tuella varustetuissa näytönohjaimissa on toinen kokoelma DMA-asemia, jotka mahdollistavat pääsyn toisen kaavion VRAM:iin. Tietenkin PCI Express -portin nopeudella, mikä on todellinen pullonkaula.
Ihannetapauksessa kaikilla yhdessä toimivilla GPU:illa olisi sama VRAM-muisti, joka on hyvin yhteistä, mutta näin ei ole. Joten tiedot kopioidaan yhtä monta kertaa kuin renderöintiin osallistuvien näytönohjainten määrä, mikä on erittäin tehotonta. Tähän on lisättävä tapa, jolla grafiikkakortit toimivat 3D-grafiikkaa reaaliajassa renderöidessään, mikä on aiheuttanut sen, että useiden näytönohjainkorttien konfiguraatiota ei enää käytetä.
Tile Caching Multi-GPU:ssa sirujen avulla
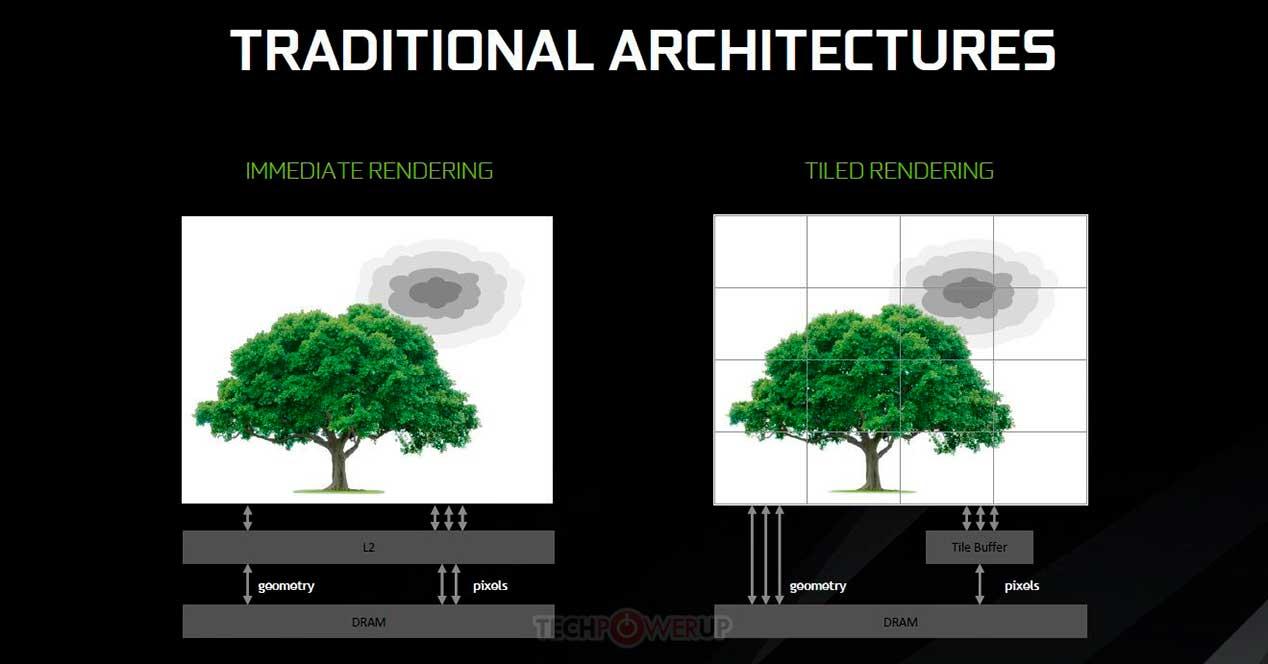
Tile Caching -konseptia alettiin käyttää NVIDIAn Maxwell-arkkitehtuurista ja AMD:n Vega-arkkitehtuurista, ja se tarkoittaa joidenkin käsitteiden ottamista laattojen avulla tapahtuvasta renderöinnistä, mutta sillä erolla, että sen sijaan, että jokainen laatta renderöisi erilliseen muistiin ja kirjoita ne vain VRAM-muistiin, kun se on valmis tehdään toisen tason välimuistissa. Tämän etuna on, että se säästää joidenkin grafiikkatoimintojen energiakustannuksissa, mutta haittana on, että se riippuu GPU:n huipputason välimuistin määrästä.
Ongelmana on, että välimuisti ei toimi kuten perinteinen muisti ja koska tahansa ja ilman ohjelmaohjausta voidaan lähettää välimuistirivi muistihierarkian seuraavalle tasolle. Entä jos päätämme soveltaa samaa toimintoa sirupohjaiseen GPU:hun? No, tässä tulee käyttöön lisävälimuistitaso. Uuden paradigman mukaan kunkin GPU:n viimeisen tason välimuisti jätetään huomiotta Tile Cachingin muistina, ja nyt käytetään Multi-GPU:n viimeisen tason välimuistia, joka löytyy erillinen siru.
Sirujen LCC Multi-GPU:ssa
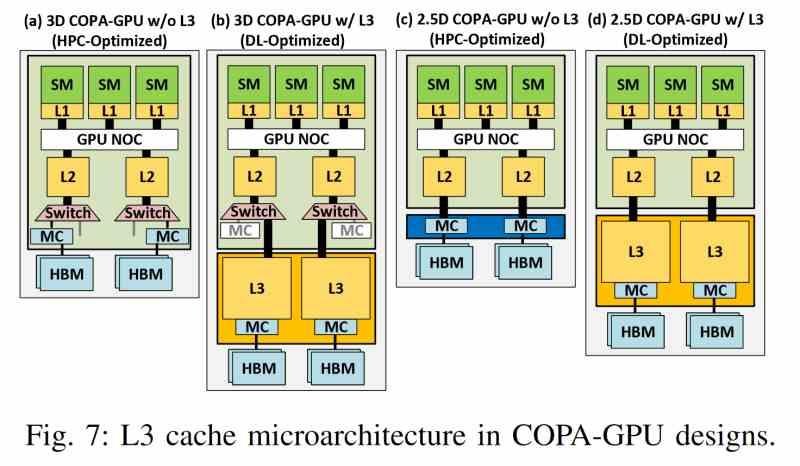
Sirupohjaisten Multi-GPU:iden uusimman tason välimuisti yhdistää useita yhteisiä ominaisuuksia, jotka ovat valmistajasta riippumattomia, joten seuraava ominaisuuksien luettelo koskee kaikkia tämän tyyppisiä GPU:ita valmistajasta riippumatta.
- Sitä ei löydy mistään GPU:sta, mutta se on niiden ulkopuolella ja on siksi erillisellä sirulla.
- Se käyttää interposeria erittäin nopealla rajapinnalla, kuten piisillalla tai TSV-yhteisliitännöillä, kommunikoidakseen kunkin GPU:n L2-välimuistin kanssa.
- Vaadittu suuri kaistanleveys ei salli tavanomaisia yhteyksiä ja on siksi mahdollista vain 2.5DIC-kokoonpanossa.
- Siru, jossa viimeisen tason välimuisti sijaitsee, ei ainoastaan tallenna mainittua muistia, vaan siellä sijaitsee myös koko VRAM-pääsymekanismi, joka on tällä tavoin irrotettu renderöintikoneesta.
- Sen kaistanleveys on paljon suurempi kuin HBM-muistin, minkä vuoksi se hyödyntää edistyneempiä 3D-yhdysliikennetekniikoita, jotka mahdollistavat paljon suuremmat kaistanleveydet.
- Lisäksi, kuten mikä tahansa viimeisen tason välimuisti, sillä on kyky antaa johdonmukaisuutta kaikille sen asiakkaina oleville elementeille.
Tämän välimuistin ansiosta jokaista GPU:ta estetään saamasta omaa VRAM-muistia jaetun VRAM-muistin saamiseksi, mikä vähentää huomattavasti datan moninaisuutta ja eliminoi pullonkaulat, jotka syntyvät tavanomaisessa multi-GPU:ssa tapahtuvasta viestinnästä.
Pää- ja alisteiset GPU:t
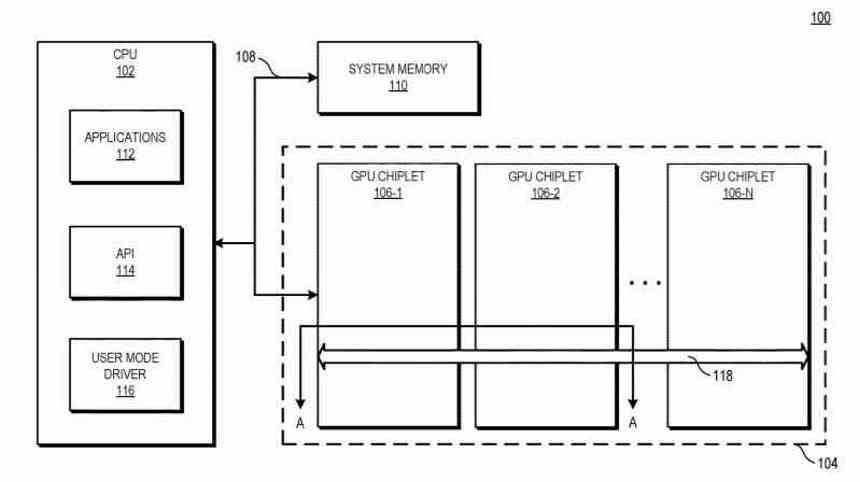
Multi-GPU by siruihin perustuvassa näytönohjaimessa on edelleen sama kokoonpano kuin perinteisessä Multi-GPU:ssa näyttöluetteloa luotaessa. Jos luodaan yksittäinen luettelo, joka vastaanottaa ensimmäisen GPU:n, joka on vastuussa muiden GPU:iden hallinnasta, mutta suuri ero on, että LLC-siru, josta olemme puhuneet edellisessä osiossa, sallii ensimmäisen GPU:n koordinoida ja lähettää tehtäviä loput usean GPU:n prosessointiyksiköt sirua kohti.
Vaihtoehtoinen ratkaisu on, että kaikista Multi-GPU:n siruista puuttuu kokonaan komentoprosessori ja tämä on samassa piirissä kuin missä LCC-siru sijaitsee orkesterinjohtajana ja hyödyntää kaikkea olemassa olevaa viestintäinfrastruktuuria eri ohjeiden lähettämiseen. säikeitä GPU:n eri osiin.
Toisessa tapauksessa meillä ei olisi pää-GPU:ta ja loput alaisina, vaan koko 2.5D-integroitu piiri olisi yksi GPU, mutta monoliittisen sijasta se koostuisi useista siruista.
Sen merkitys Ray Tracingille

Yksi tulevaisuuden tärkeimmistä kohdista on Ray Tracing, jonka toimiminen edellyttää, että järjestelmä luo objektien tiedoille paikkatietorakenteen edustamaan valon kulkeutumista. On osoitettu, että jos mainittu rakenne on lähellä prosessoria, Ray Tracingin kärsimä kiihtyvyys on tärkeä.
Tietenkin tämä rakenne on monimutkainen ja vie paljon muistia. Tästä syystä suuri LLC-välimuisti on erittäin tärkeää tulevaisuudessa. Ja tästä syystä LLC:n välimuisti tulee olemaan erillisessä sirussa. Suurin mahdollinen kapasiteetti ja tietorakenteen tekeminen mahdollisimman lähelle GPU:ta.
Nykyään suuri osa Ray Tracingin hitaudesta johtuu siitä, että suuri osa tiedoista on VRAM-muistissa ja sen pääsyssä on valtava viive. Muista, että Multi-GPU:n LLC-välimuistilla ei ole etuja vain kaistanleveyden, vaan myös välimuistin latenssin suhteen. Lisäksi sen suuri koko ja Intelin, AMD:n ja NVIDIAn laboratorioissa kehitetyt tiedonpakkaustekniikat tekevät kiihdytykseen käytetyt BVH-rakenteet tallennettaviksi GPU:n "sisäiseen" muistiin.