Wir alle kennen und haben mit Dateisystemen wie NTFS in gearbeitet Windowsoder EXT4 in LinuxEs gibt jedoch andere Dateisysteme mit unterschiedlichen Eigenschaften, Betrieb und Leistung. Heute werden wir in diesem Artikel ausführlich über die ZFS-Dateisystem , das beste Dateisystem für NAS-Server Dabei ist die Integrität der Dateien einer der wichtigsten Aspekte, ohne den Schutz der Daten vor Ransomware zu vergessen. oder Fehlfunktion einer der Festplatten. Sind Sie bereit, alles über ZFS zu wissen?
Was ist ZFS und welche Funktionen hat es?
ZFS ist ein Dateisystem, das ursprünglich von Sun Microsystems für sein Solaris-Betriebssystem entwickelt wurde. Der Quellcode wurde 2005 als Teil des OpenSolaris-Betriebssystems veröffentlicht, machte ZFS jedoch in anderen Betriebssystemen und Umgebungen verwendbar. Anfangs gab es Probleme mit ZFS-Rechten, daher wurde beschlossen, verschiedene „Ports“ zu erstellen, um sie ohne Lizenzprobleme an verschiedene Betriebssysteme anzupassen. Im Jahr 2013 Öffnen ZFS wurde unter dem Dach des Umbrella-Projekts so gestartet, dass ZFS problemlos unter Betriebssystemen wie Linux und FreeBSD verwendet werden kann. Ab diesem Moment finden wir das ZFS-Dateisystem in FreeBSD, NetBSD, Linux wie Debian oder Ubuntu .
![]()
Das ZFS-Dateisystem wird nativ auf FreeBSD-basierten Betriebssystemen wie dem beliebten FreeNAS oder XigmaNAS verwendet, zwei Betriebssystemen, die speziell auf NAS-Server ausgerichtet sind. Der Hersteller QNAP mit seinem Linux-basierten QTS-Betriebssystem verwendet EXT4 seit vielen Jahren, hat jedoch kürzlich ein neues Betriebssystem namens QuTS Hero auf den Markt gebracht, mit dem das ZFS-Dateisystem dank dieser Entscheidung für die Massenspeicherung verwendet werden kann Wir werden in der Lage sein, von einer Vielzahl von Verbesserungen der Integrität von Dateien und deren Schutz vor möglichen Schreibfehlern zu profitieren.
Bevor wir beginnen, die Hauptfunktionen von ZFS zu erläutern, lassen Sie uns über seine „Grenzen“ sprechen. ZFS wurde so konzipiert, dass wir im wirklichen Leben niemals Einschränkungen haben. Mit ZFS können 2 erstellt werden 48 Snapshots nativ und ermöglicht auch das Erstellen von bis zu 2 48 Anzahl der Dateien im Dateisystem. Andere Grenzwerte sind 16 Exabyte für die maximale Größe eines Dateisystems und sogar 16 Exabyte für die maximale Größe einer Datei. Die maximale Speicherkapazität eines «Pools» beträgt 3 × 10 23 Petabyte, so dass wir mehr als genug Platz haben, wenn wir es brauchen, zusätzlich können wir bis zu 2 haben 64 Festplatten in einem Zpool und 2 64 zpools in einem System.
Virtuelle Speicherplätze
In ZFS gibt es sogenannte „virtuelle Speicherbereiche“ oder auch als vdevs bezeichnet, bei denen es sich im Grunde um das Speichergerät handelt, dh um die Festplatten oder SSDs für die Speicherung. Mit ZFS haben wir nicht das typische RAID, das wir in Dateisystemen wie EXT4 finden, das typische RAID 0, RAID 1 oder RAID 5, sie existieren auch hier, aber auf andere Weise.
Ein «Pool» kann von verschiedenen Typen sein, je nachdem, was wir in Bezug auf Geschwindigkeit, Speicherplatz und Datenintegrität wünschen, falls eine oder mehrere Festplatten ausfallen:
- Stripe : Alle Festplatten werden in einem «Pool» abgelegt und die Kapazitäten der verschiedenen Festplatten addiert. Bei einem Festplattenfehler gehen alle Informationen verloren. Diese Art von Pool ähnelt RAID 0, ermöglicht jedoch die Einbindung mehrerer Festplatten.
- Spiegel : Alle Festplatten gelangen in einen «Pool» und werden repliziert. Die maximale Kapazität des Pools entspricht der kleinsten Kapazität einer der Festplatten. Alle Festplatten im Spiegel werden repliziert. Daher gehen nur dann Informationen verloren, wenn alle Festplatten im Spiegel beschädigt sind. Diese Art von Pool ähnelt einem RAID 1, ermöglicht jedoch die Einbindung mehrerer Festplatten.
- RAID-Z1 : Alle Festplatten gelangen in den Pool. Unter der Annahme, dass alle Festplatten dieselbe Kapazität haben, wird die Kapazität aller Festplatten bis auf eine hinzugefügt (wenn wir 3 4-TB-Festplatten haben, beträgt der effektive Speicherplatz 8 TB). Dadurch kann eine der Festplatten beschädigt werden, und die Informationen sind intakt. Der Betrieb ist wie ein RAID 5, das wir alle kennen. Ein RAID Z1 muss 3, 5 oder 9 Festplatten in jedem vdev haben, daher können wir in einem vdev insgesamt 9 Festplatten haben, und dass, wenn eine ausfällt, wir keinen Datenverlust haben, im Falle eines zweiten Festplattenausfalls. Wir werden alle Informationen verlieren.
- RAID-Z2 : Alle Festplatten gelangen in den Pool. Unter der Annahme, dass alle Festplatten dieselbe Kapazität haben, addieren Sie die Kapazität aller Festplatten mit Ausnahme der von zwei Festplatten (wenn wir 4 4-TB-Festplatten haben, beträgt der effektive Speicherplatz 8 TB). Dadurch können zwei der Festplatten beschädigt werden, und die Informationen bleiben erhalten. Die Operation ähnelt einem RAID 6, das wir alle kennen. Ein Z2-RAID muss 4, 6 oder 10 Festplatten in jedem vdev haben. Daher können wir insgesamt 10 Festplatten in einem vdev haben. Wenn zwei ausfallen, tritt bei einem Ausfall der dritten Festplatte kein Datenverlust auf Wir werden alle Informationen verlieren.
- RAID-Z3 : Alle Festplatten gelangen in den Pool. Unter der Annahme, dass alle Festplatten dieselbe Kapazität haben, wird die Kapazität aller Festplatten mit Ausnahme der einen von drei hinzugefügt (wenn wir 5 4-TB-Festplatten haben, beträgt der effektive Speicherplatz 8 TB). Dadurch können drei der Festplatten beschädigt werden, und die Informationen bleiben erhalten. Ein Z3-RAID muss 5, 7 oder 11 Festplatten in jedem vdev haben. Daher können wir in einem vdev insgesamt 1 Festplatten haben. Wenn drei ausfallen, haben wir im Falle eines vierten Festplattenausfalls keinen Datenverlust. Wir werden alle Informationen verlieren.
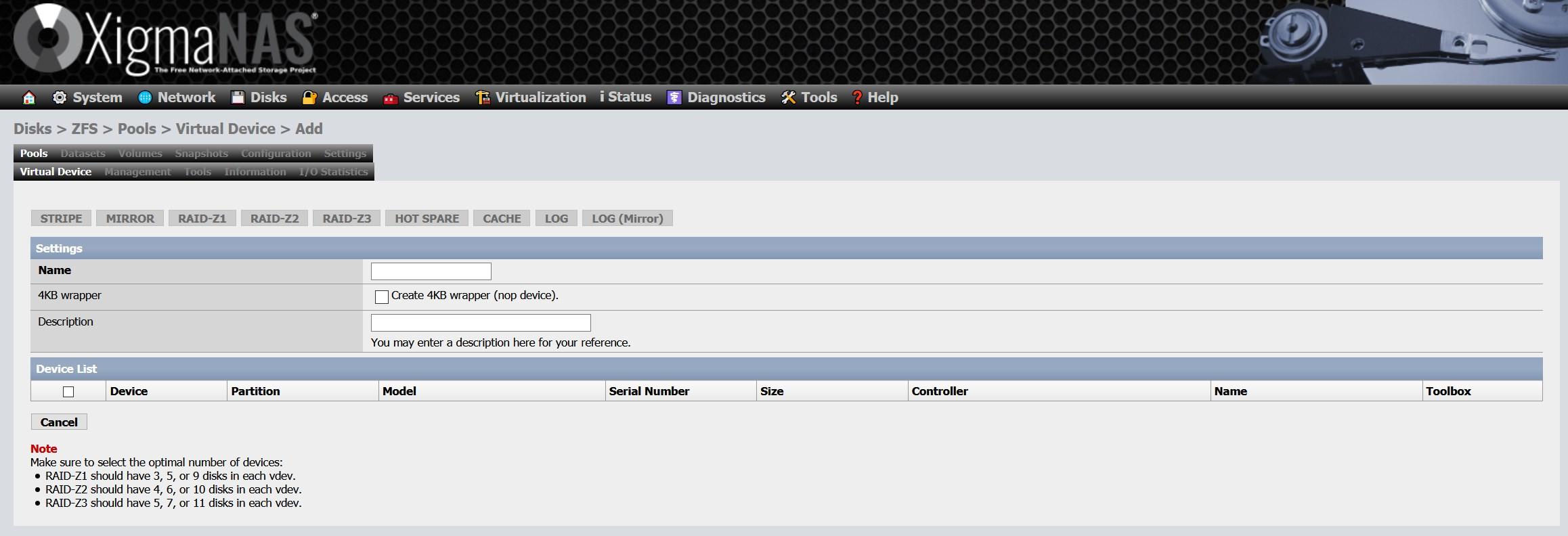
Andere Konfigurationen, die wir mit ZFS durchführen können, sind das Definieren einer Festplatte als « Hot-Spare «Oder auch als" Ersatz "bezeichnet, sodass diese Sicherungsdiskette im Falle eines Festplattenausfalls automatisch in Betrieb genommen wird und mit dem Resilvering (Wiederherstellung von Daten mithilfe dieser neuen Festplatte, die wir gerade zum Pool hinzugefügt haben) beginnt ). Wir haben auch die Möglichkeit, eine Festplatte als «zu definieren Cache-Speicher «, Was im Grunde genommen dazu dient, den L2ARC zu aktivieren und eine höhere Leistung zu erzielen, ist ideal, wenn wir ihn mit einem schnellen verwenden SSDWenn Sie eine normale Festplatte verwenden, werden Sie keine Verbesserung bemerken und möglicherweise sogar die Leistung verschlechtern. Schließlich haben wir auch die Möglichkeit, eine Festplatte als " LOG ”(SLOG ZFS Intent Log) zum Speichern der Schreibprotokolle, die aufgetreten sein sollten. Dies ist hilfreich bei einem Stromausfall.
Leichte Dateisysteme (Datensatz)
Datensätze sind wirklich die ZFS-Dateisysteme. Sie befinden sich in einem ZFS-Speicherbereich. Um ein Dataset zu erstellen, muss zuvor ein «Pool» erstellt worden sein, da es sonst nicht erstellt werden kann. Es gibt zwei verschiedene Arten von Datensätzen:
- Dateisystem : Dies ist standardmäßig der Dataset-Typ, der zum Speichern von Dateien, Ordnern usw. verwendet wird. Der Mount-Punkt kann direkt festgelegt werden, ohne die typische fstab von Linux-Systemen zu bearbeiten.
- ZVOL : es ist ein Datensatz, der ein Gerät durch Blöcke darstellt, wir können es auch in den verschiedenen Betriebssystemen als «Volume» finden. Mit diesem Datensatz können Sie ein Gerät in Blöcken erstellen und später mit Dateisystemen wie EXT4 formatieren.
Einige der wichtigsten Funktionen eines Datasets (Dateisystems) sind, dass Sie Kontingente, reservierte Festplattenkontingente, Berechtigungsverwaltung mit erweiterten Zugriffssteuerungslisten (ACL) konfigurieren und sogar sehr erweiterte Funktionen wie die folgenden zulassen können:
- Deduplizierung (Dedup) : Die Deduplizierung ist eine Technik zum Entfernen doppelter Kopien wiederholter Daten. Es kann nicht als "Komprimieren" bezeichnet werden, aber es ist wahr, dass bei einer Deduplizierung die endgültige Größe eines Datensatzes deutlich kleiner ist. Diese Technik wird verwendet, um die Datenspeicherung auf der Festplatte zu optimieren. ZFS führt die Deduplizierung nativ durch, daher ist es sehr effizient, aber damit es richtig funktioniert, benötigt es viel RAM: Für jedes 1 TB deduplizierte Dataset werden ca. 16 GB RAM benötigt . Angesichts der Tatsache, dass Speicherplatz (Festplatten) heutzutage viel billiger als RAM ist, ist es ratsam, keine Deduplizierung zu verwenden, es sei denn, Sie wissen, was Sie tun.
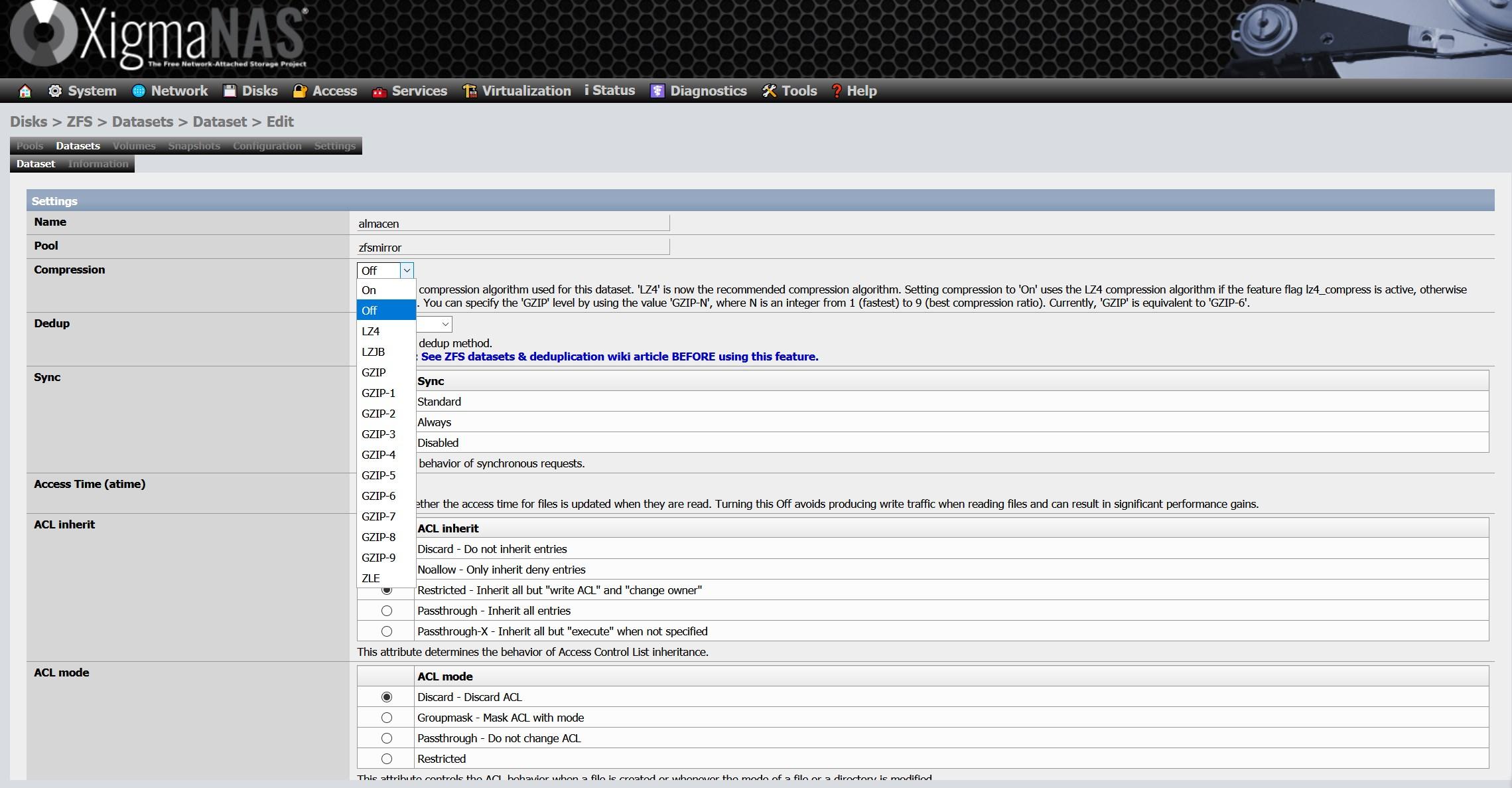
- Kompression : Mit ZFS können nativ verschiedene Komprimierungsalgorithmen verwendet werden, um Speicherplatz im Dataset und damit im Pool zu sparen. Der LZ4-Komprimierungsalgorithmus ist derzeit der Standard und wird in den meisten Situationen am meisten empfohlen. Andere wie LBJB und sogar GZIP mit unterschiedlichen Komprimierungsstufen können ebenfalls verwendet werden. Sehr bald werden wir jedoch ZSTD sehen, einen neuen Komprimierungsalgorithmus für ZFS. ZSTD ist ein moderner, leistungsstarker allgemeiner Komprimierungsalgorithmus, der von derselben Person wie LZ4 entwickelt wurde. Ziel ist es, Komprimierungsstufen ähnlich wie bei GZIP bereitzustellen, jedoch mit besserer Leistung. Ein weiteres interessantes Merkmal von ZSTD ist, dass Sie verschiedene Komprimierungs- / Leistungsstufen auswählen können, um den Anforderungen von Administratoren gerecht zu werden.
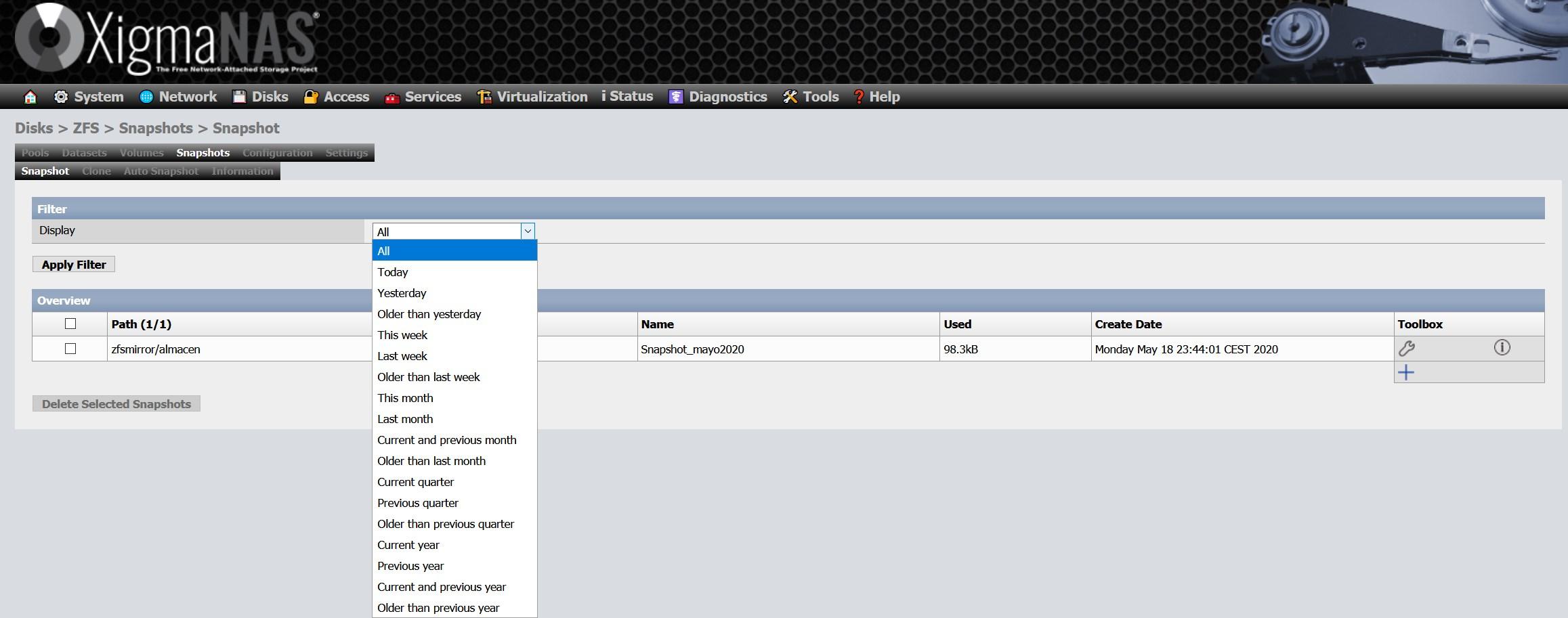
- Snapshots : Mit Snapshots können wir zu einem bestimmten Zeitpunkt ein „Foto“ des Status des Dateisystems speichern, um die Informationen zu schützen, wenn eine Ransomware angegriffen wird, oder um eine Datei direkt zu löschen, wenn dies nicht der Fall ist haben. erledigt. Obwohl Hersteller wie QNAP oder Synology Snapshots haben und EXT4 verwenden, sind ZFS-Snapshots nativ, was ihren Betrieb wesentlich effizienter macht. Mit ZFS können wir die Daten in diesen Snapshots anzeigen, ohne sie rückgängig zu machen, alle Änderungen rückgängig zu machen und sogar die von uns aufgenommenen Snapshots zu „klonen“. Mit diesen „Klonen“ können Sie zwei unabhängige Dateisysteme erstellen, die durch gemeinsame Nutzung eines gemeinsamen Satzes von Blöcken erstellt werden. Die Anzahl der Schnappschüsse, die wir mit ZFS machen können, beträgt 2 48 Das heißt, man könnte sagen, dass wir unbegrenzte Schnappschüsse haben.
ZFS überschreibt keine Daten aufgrund des Copy-on-Write-Modells, über das wir später sprechen werden. Wenn Sie also einen Snapshot erstellen, werden die von alten Versionen verwendeten Blöcke einfach nicht freigegeben. Schnappschüsse werden sehr schnell aufgenommen und sind aus räumlicher Sicht sehr effizient. Sie nehmen nichts auf, es sei denn, Sie ändern Daten, aus denen der Schnappschuss erstellt wurde. Das heißt, es gibt keine Duplizierung von Daten, die Snapshot-Daten und die in der Produktion befindlichen werden gemeinsam genutzt, nur wenn sie geändert werden, wenn die Belegung zuzunehmen beginnt.
Selbstheilung
Eines der wichtigsten Merkmale von ZFS ist die Selbstreparatur. Wir haben bereits erläutert, dass es Pools vom Typ «Spiegel» und auch RAID-Z mit einfacher, doppelter oder dreifacher Parität gibt. Ein sehr wichtiger Aspekt ist, dass ZFS keinen "Schreibloch" -Defekt aufweist. Dies kann auftreten, wenn während des Schreibens ein Stromausfall auftritt. Dies macht es unmöglich zu bestimmen, welche Datenblöcke oder Paritätsblöcke auf die Discs geschrieben wurden und welche sind nicht. In dieser katastrophalen Fehlersituation stimmen die Paritätsdaten nicht mit den übrigen Daten im Speicherplatz überein. Außerdem ist es nicht möglich zu wissen, welche Daten falsch sind: die Paritätsdaten oder die Blockdaten.
Alle Daten in ZFS wurden vor dem Schreiben in den Pool gehasht. Der Hashing-Algorithmus kann beim Erstellen des Datasets konfiguriert werden. Sobald die Daten geschrieben wurden, wird der Hash überprüft, um sicherzustellen, dass sie korrekt geschrieben wurden und keine Probleme beim Schreiben aufgetreten sind. Mit ZFS können Sie die Integrität der Daten mithilfe dieser Hash-Daten auf einfache Weise überprüfen. Wenn die Daten nicht dem Hash entsprechen, müssen Sie in den Spiegel schauen oder die Daten über das Paritätssystem (RAID-Z) berechnen, um mit der Überprüfung auf Hash-Ebene fortzufahren. Wenn die Hash-Daten identisch sind, fahren wir mit der Korrektur der Daten im Block fort. All dies erfolgt vollautomatisch.
Copy-on-Write
ZFS verwendet eine Copy-on-Write-Architektur. Dadurch vermeiden wir die Probleme, die sich aus dem zuvor erläuterten Schreibloch ergeben. CoW ist eines der Hauptmerkmale von ZFS. Die Operation besteht darin, dass alle Zeiger auf Blöcke eines Dateisystems eine Prüfsumme enthalten, die beim Lesen des Blocks überprüft wird. Blöcke, die aktive Daten enthalten, werden niemals überschrieben. Es wird lediglich ein neuer Block reserviert, und die geänderten Daten werden direkt darauf geschrieben. Um es schneller und effizienter zu machen, werden normalerweise mehrere Aktualisierungen hinzugefügt, um die Transaktionen später auszuführen, und sogar ein ZIL (ZFS Intent Log) wird verwendet.
Der Nachteil dabei ist, dass es in Pools zu einer hohen Fragmentierung kommt und derzeit keine Möglichkeit einer Defragmentierung besteht. Wenn Ihr Pool aus SSDs besteht, werden Sie den Leistungsverlust aufgrund der Natur von SSDs nicht allzu sehr bemerken. Wenn Sie jedoch eine Festplatte verwenden, werden Sie ihn möglicherweise bemerken. In unserem Fall haben wir nach mehrjähriger Nutzung eine Fragmentierung von mehr als 25%:
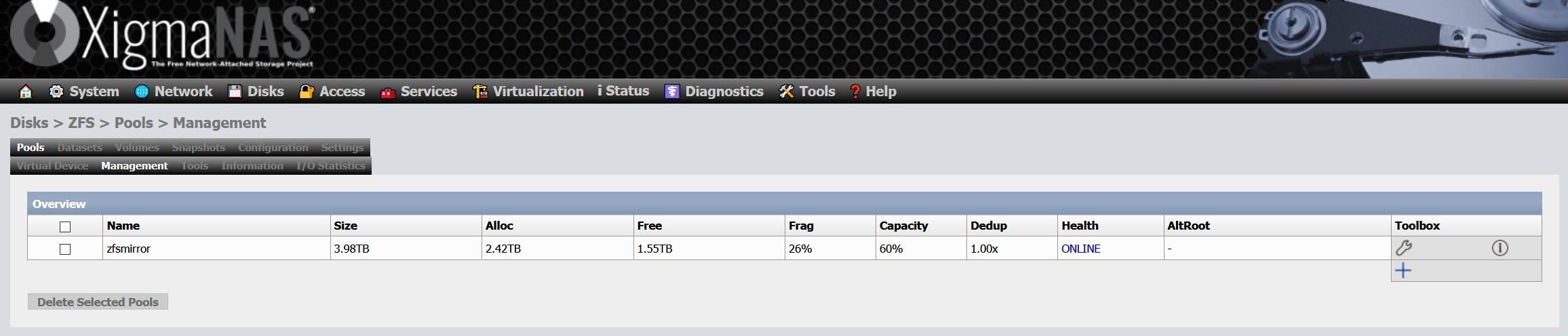
Die einzige Möglichkeit, den Pool zu defragmentieren, besteht darin, die Daten auf ein anderes Medium zu kopieren, den Pool zu entfernen und erneut zu erstellen. Das heißt, es gibt zumindest vorerst keine Möglichkeit, einen Pool in ZFS zu defragmentieren.
Dynamisches Striping
ZFS verteilt die Daten, die wir dynamisch schreiben, an alle virtuellen Geräte (vdev), um die Leistung zu maximieren. Die Entscheidung, wo die Daten abgelegt werden sollen, wird zum Zeitpunkt des Schreibens getroffen. Dies verbessert die Spiegel- und RAID-Z-Pools erheblich und beseitigt auch effektiv das Problem der Schreiblöcher, das wir zuvor gesehen haben. Ein weiteres interessantes Feature ist, dass ZFS Blöcke mit einer variablen Größe von bis zu 128 KB verwendet. Der Administrator kann die maximal verwendete Blockgröße konfigurieren, ideal, um sich an die Anforderungen des Schreibens in den Pool anzupassen, aber es kann sich automatisch anpassen. Bei Verwendung der Komprimierung werden diese variablen Blockgrößen verwendet, um den Platz wesentlich effizienter zu gestalten.
So installieren und starten Sie ZFS
ZFS wird auf FreeBSD-basierten Betriebssystemen wie XigmaNAS oder FreeNAS installiert. Das Standarddateisystem in diesen Betriebssystemen ist UFS, wir haben jedoch die Möglichkeit, ZFS als Systemdateisystem zu verwenden. Am empfehlenswertesten ist es jedoch, ZFS als Dateisystem des Speichersatzes zu verwenden, in dem wir jede einzelne unserer Dateien haben werden. Hier können wir wirklich das Beste daraus machen. In diesen NAS-orientierten Betriebssystemen müssen wir keinen Befehl ausführen, da alles mit der grafischen Benutzeroberfläche erledigt wird, ohne dass etwas anderes berührt werden muss. Bei anderen Betriebssystemen wie Debian, Ubuntu, Linux Mint und anderen müssen wir ZFS manuell installieren.
Als Nächstes lernen Sie, wie Sie ZFS auf einem XigmaNAS-Betriebssystem (basierend auf FreeBSD) konfigurieren und starten. Die Vorgehensweise ähnelt der von FreeNAS, da wir dasselbe Dateisystem verwenden. Wir werden Ihnen auch beibringen, wie man es auf Betriebssystemen wie Debian installiert, obwohl wir hier alles über die Befehlskonsole erledigen müssen.
ZFS-Konfiguration und Start in XigmaNAS
Für die Realisierung dieses Tutorials haben wir VMware zur Virtualisierung von XigmaNAS verwendet und insgesamt 6 virtuelle Festplatten erstellt. Die erste virtuelle Festplattenkapazität von 20 GB dient zur Installation des Betriebssystems selbst und liegt im UFS-Format vor, das für FreeBSD typisch ist. Die anderen 5 Festplatten mit jeweils 100 GB sind auf den Speicherplatz für das ZFS-Dateisystem ausgerichtet und werden als ZFS formatiert.
Schritt 1: Formatieren Sie die Datenträger im ZFS-Format, um sie einem Pool hinzuzufügen
Der erste Schritt besteht darin, die Datenträger im ZFS-Format zu formatieren, um sie einem Pool hinzuzufügen. Dazu gehen wir zu « Festplatten / Administration «.
In diesem Menü gehen wir zur Registerkarte "Festplattenoptionen" und klicken auf "Datenträger importieren - Importieren", um alle auf dem Server konfigurierten Datenträger zu importieren.
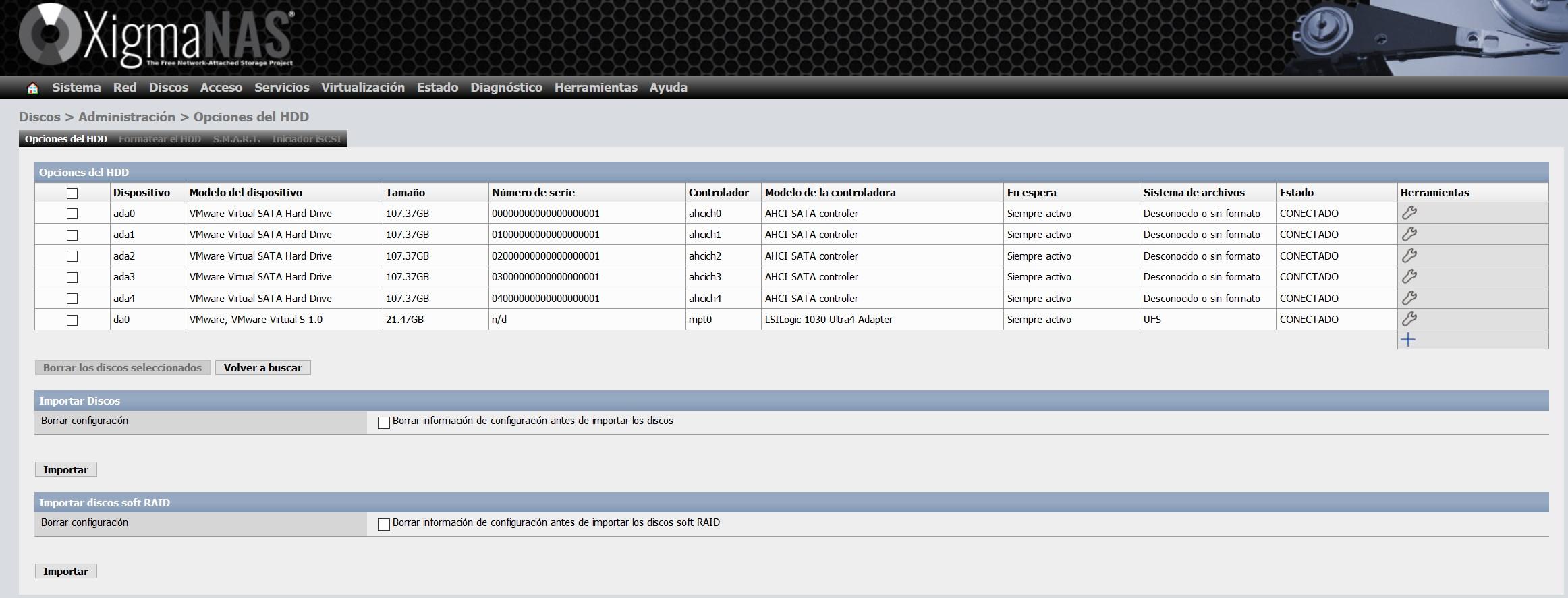
Wir werden alle Festplatten ohne Format sehen, weil wir sie gerade hinzugefügt haben, aber wir werden auch die Festplatte des Betriebssystems im UFS-Format sehen.
In dem " Festplatte formatieren "Registerkarte wählen wir alle Festplatten, und wir wählen" Dateisystem: ZFS-Speicher im Gerätepool (Pool) ".
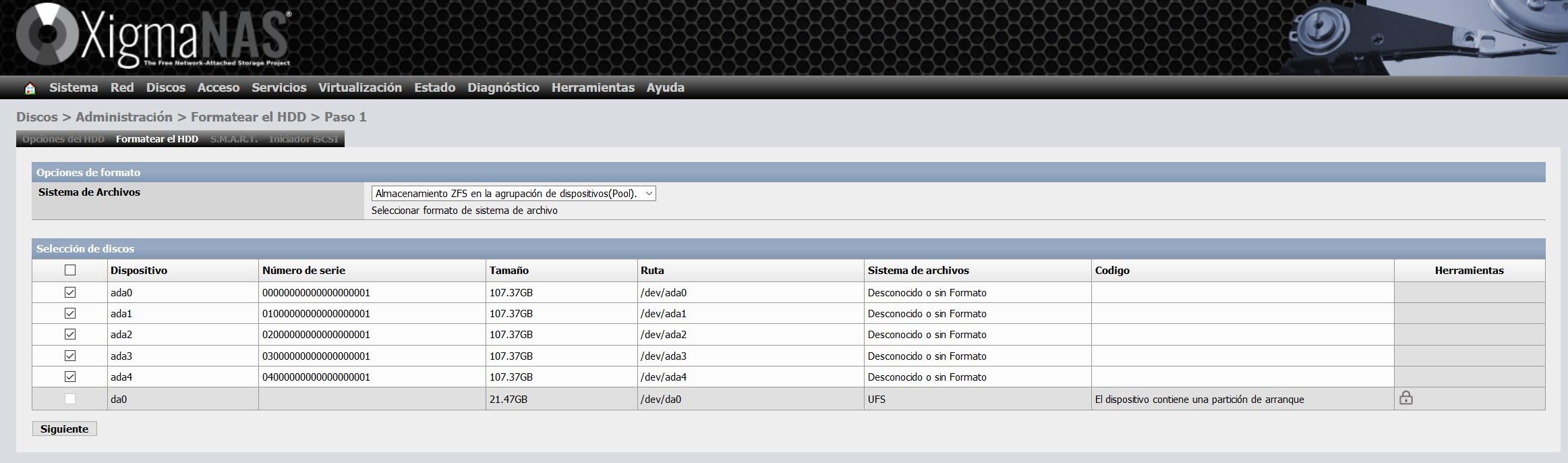
Im Konfigurationsassistenten zum Formatieren können wir Ihnen eine Datenträgerbezeichnung geben, wie Sie unten sehen können:
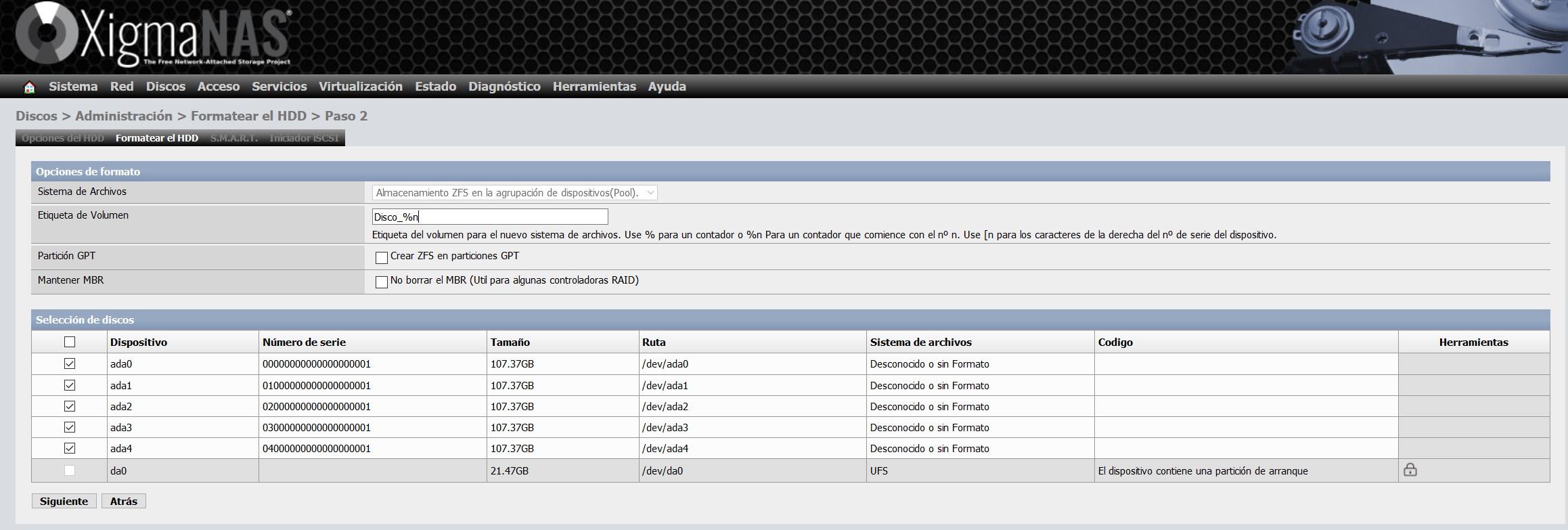
Klicken Sie auf Weiter. Wir haben alle Datenträger im ZFS-Format formatiert und können sie einem ZFS-Pool hinzufügen.
Schritt 2: Erstellen Sie die virtuelle vdev ZFS-Appliance
Jetzt müssen wir zu «Festplatten / ZFS» gehen und greifen auf den Abschnitt «Gerätegruppen (Pools)» im Teil «Virtuelles Gerät» zu. In diesem Abschnitt klicken wir auf das "+" auf der rechten Seite.

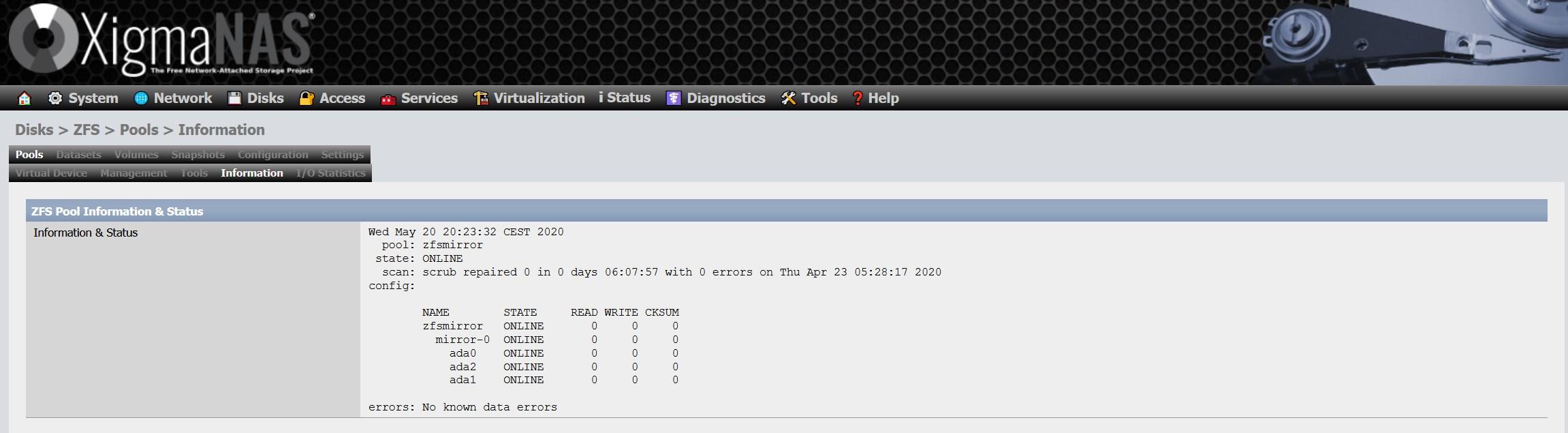
Hier müssen wir alle Festplatten auswählen, die wir in das vdev integrieren möchten. Abhängig von der Anzahl der hinzugefügten Festplatten haben wir die Möglichkeit, einen «Stripe», einen «Mirror» und die verschiedenen RAIDZ zu konfigurieren. Wir haben die fünf Discs ausgewählt, daher können wir die fünf Typen erstellen.
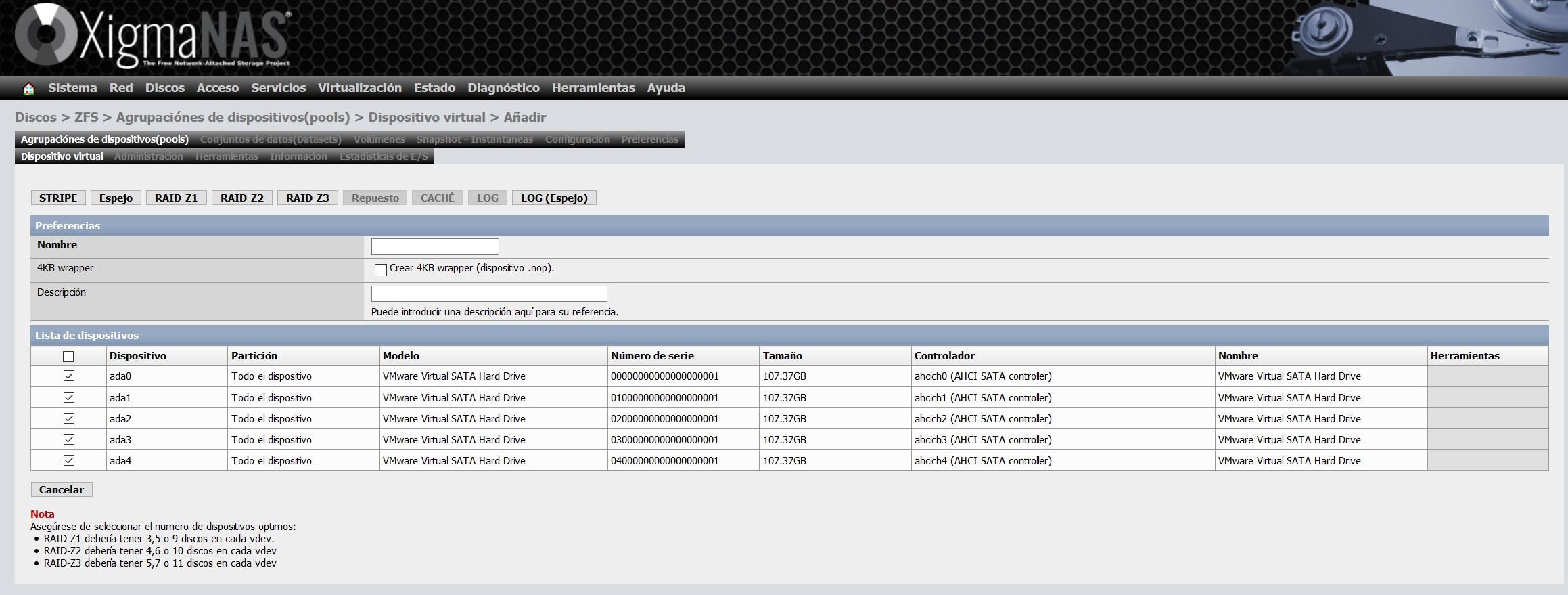
Wir haben die Option "Spiegeln" oder auch "Spiegeln" gewählt. Mit dieser Option haben wir auf den fünf Discs genau die gleichen Informationen.
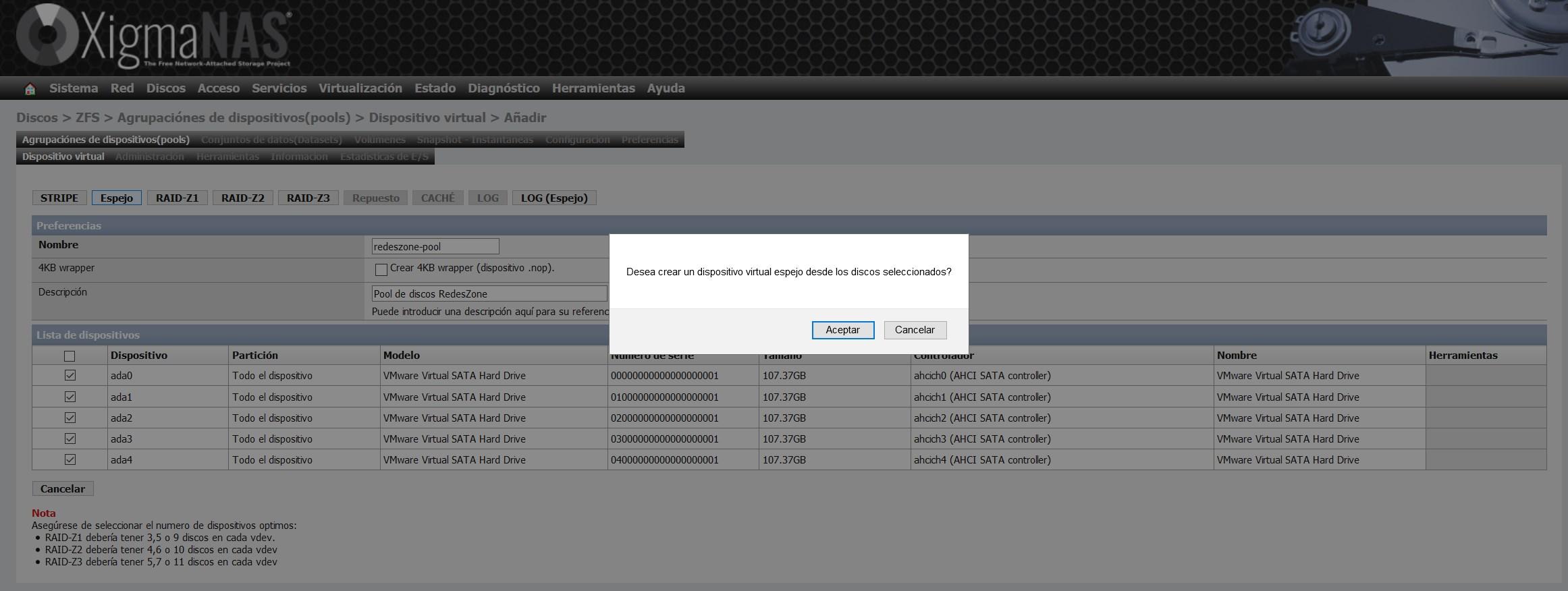
Sobald wir das virtuelle Gerät erstellt haben, wird es in der Liste der virtuellen Geräte angezeigt, wie Sie hier sehen können:
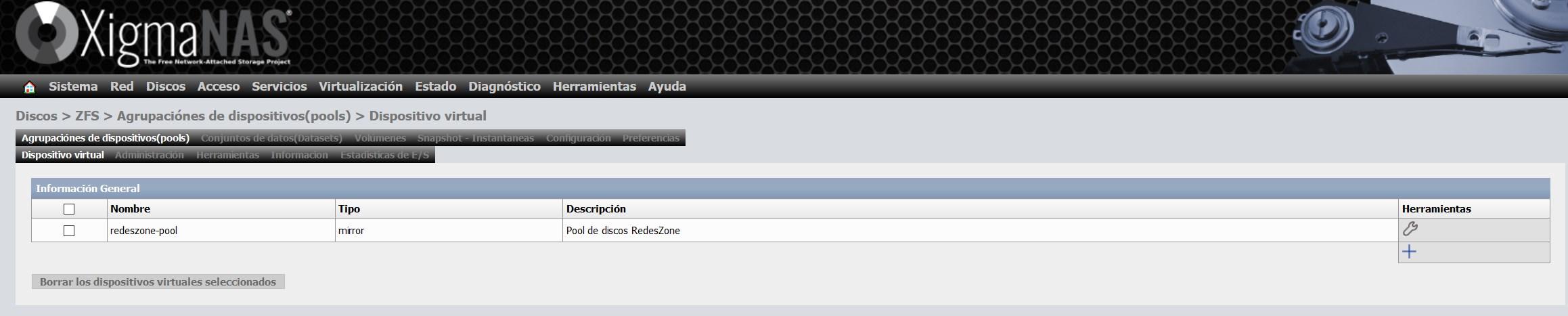
Schritt 3: Richten Sie den Pool ein und geben Sie ihm einen Namen
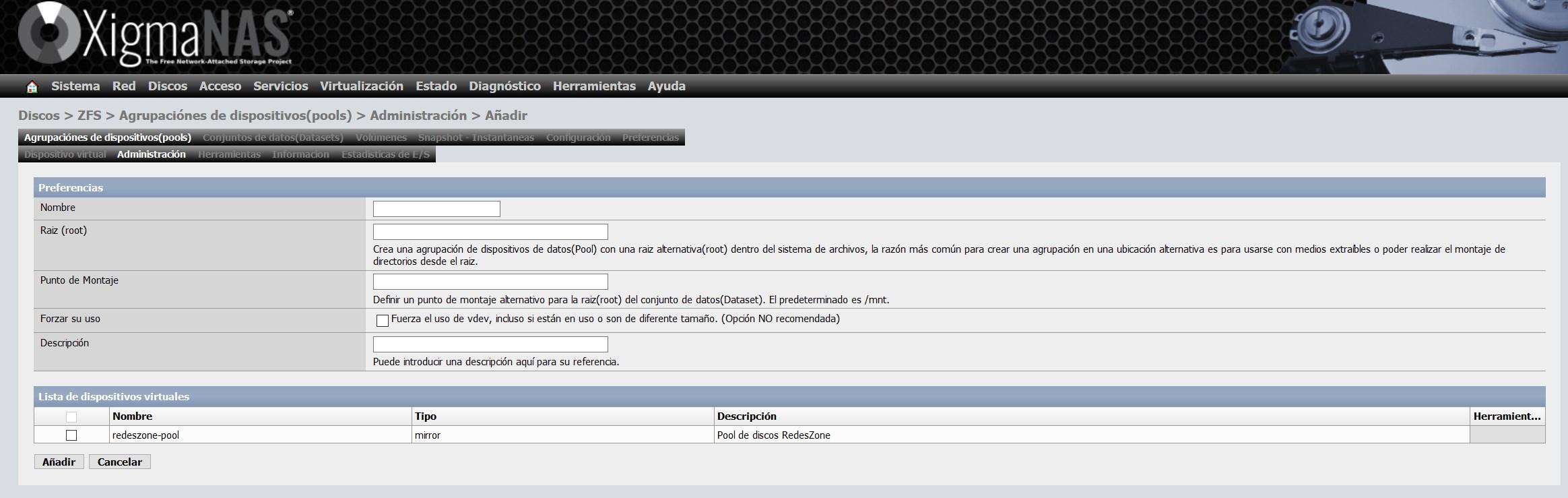
Nachdem wir das vdev erstellt haben, müssen wir zu «Administration» gehen und auf «+» klicken, um dieses vdev zu formatieren und es später mit einem Datensatz oder Volume verwenden zu können.

Wir müssen ihm einen Namen geben, und wir können auch den gewünschten Einhängepunkt definieren. Der Standard-Einhängepunkt ist / mnt.
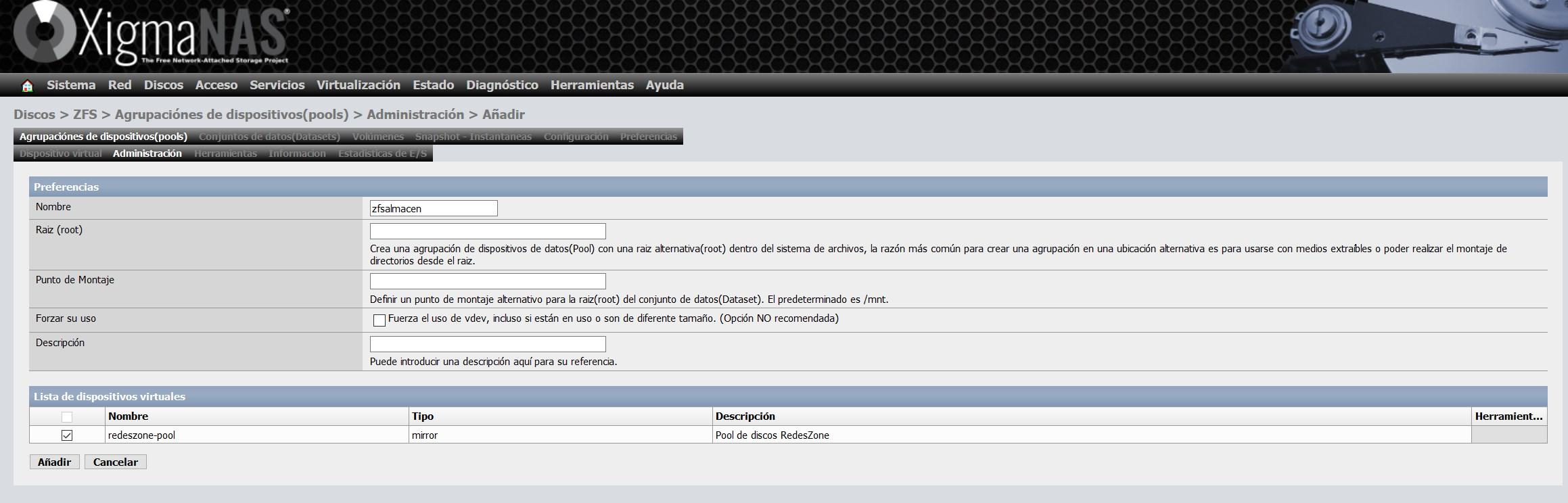
Wir werden ihm den Namen zfsalmacen geben und wir wählen das vdev, das wir zuvor erstellt haben, wie Sie hier sehen können:
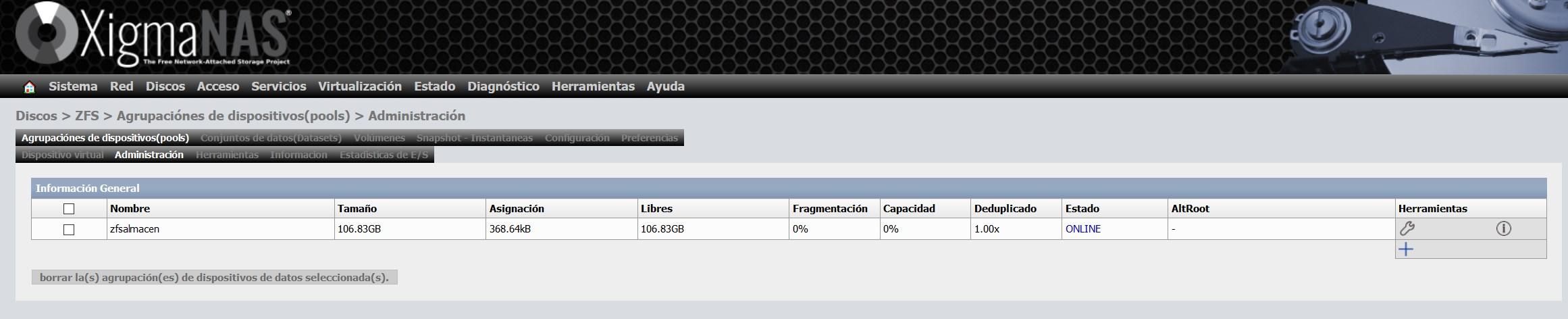
Sobald wir es erstellt haben, werden die Gesamtgröße, die freie Größe, die Fragmentierung usw. angezeigt.
Ein sehr wichtiger Abschnitt von XigmaNAS ist der Abschnitt „Tools“. Hier haben wir verschiedene Konfigurationsassistenten, um verschiedene Aktionen auszuführen. All dies können wir manuell mit Befehlen tun, aber mit dieser grafischen Benutzeroberfläche können wir dies mit wenigen Klicks tun . Was uns ermöglicht, XigmaNAS durchzuführen, ist Folgendes:
- Aktualisieren Sie den ZFS-Kernel und fügen Sie dem Gerätepool (Pool) Unterstützung für neue Funktionen hinzu.
- Hinzufügen eines Sicherungsgeräts zum Datengerätepool (Pool)
- Fügen Sie dem Pool der Datengeräte ein Gerät für CACHÉ hinzu
- Fügen Sie dem Datengerätepool (Pool) ein Gerät für LOG hinzu.
- Schließen Sie ein Gerät für Daten an
- Trennen Sie ein Datengerät von einem Spiegel
- Stellen Sie den ZFS-Befehlsverlauf bereit
- Beseitigen Sie Gerätefehler
- Entfernen Sie das ZFS-Tag vom Gerät
- Löscht einen Pool von Datengeräten (Pool).
- Exportieren Sie einen ZFS-Gerätepool aus dem System
- Generieren Sie eine eindeutige Kennung für den Gerätepool
- Auflisten oder Importieren von Gerätegruppen (Pools)
- Schaltet die Disc offline
- Stellen Sie ein Gerät online
- Ersetzen Sie ein Gerät
- Scrubben Sie den Gerätepool
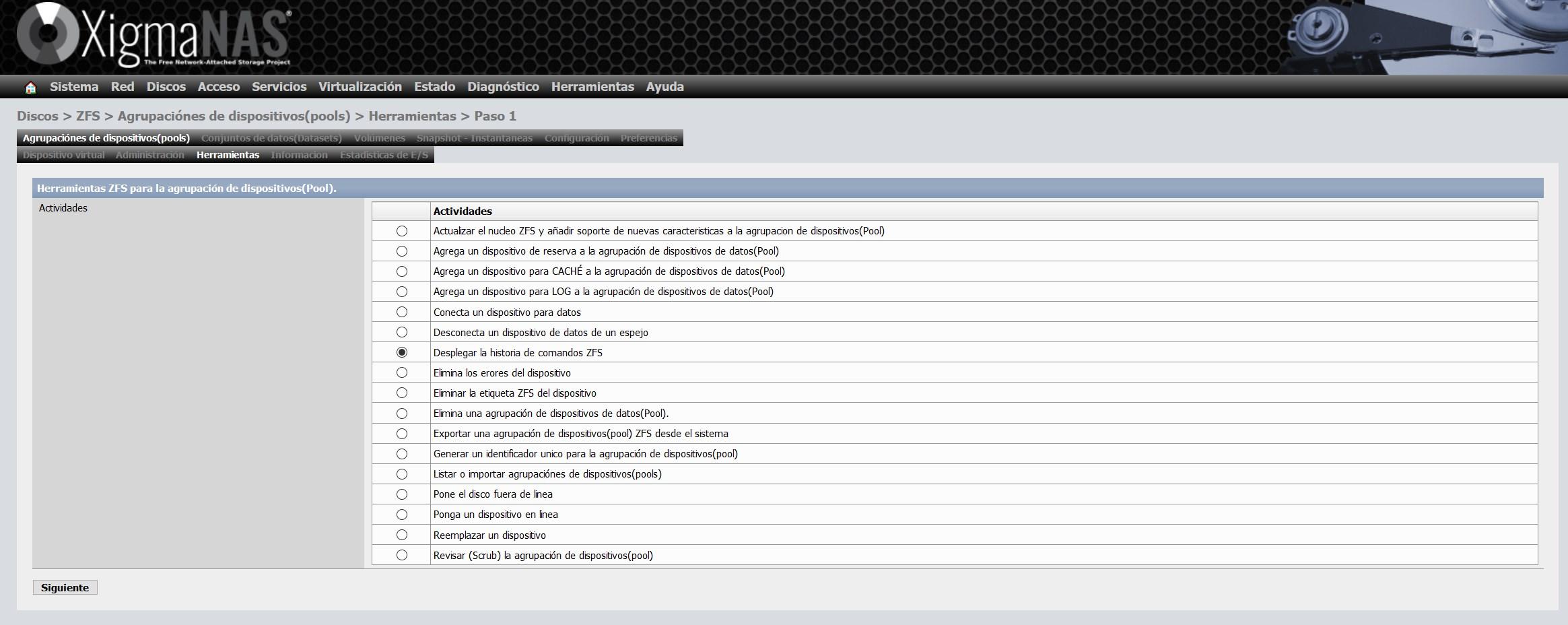
Im Abschnitt "Informationen" sehen wir den allgemeinen Status des ZFS, den ausgewählten vdev-Typ und alle Festplatten, die wir im Pool haben. Ein wichtiges Detail ist, dass das ZFS möglicherweise nicht auf den Datenträgern selbst auf die neueste Version aktualisiert wurde. Wenn wir diese Warnung erhalten, müssen wir ein sehr einfaches Update durchführen.
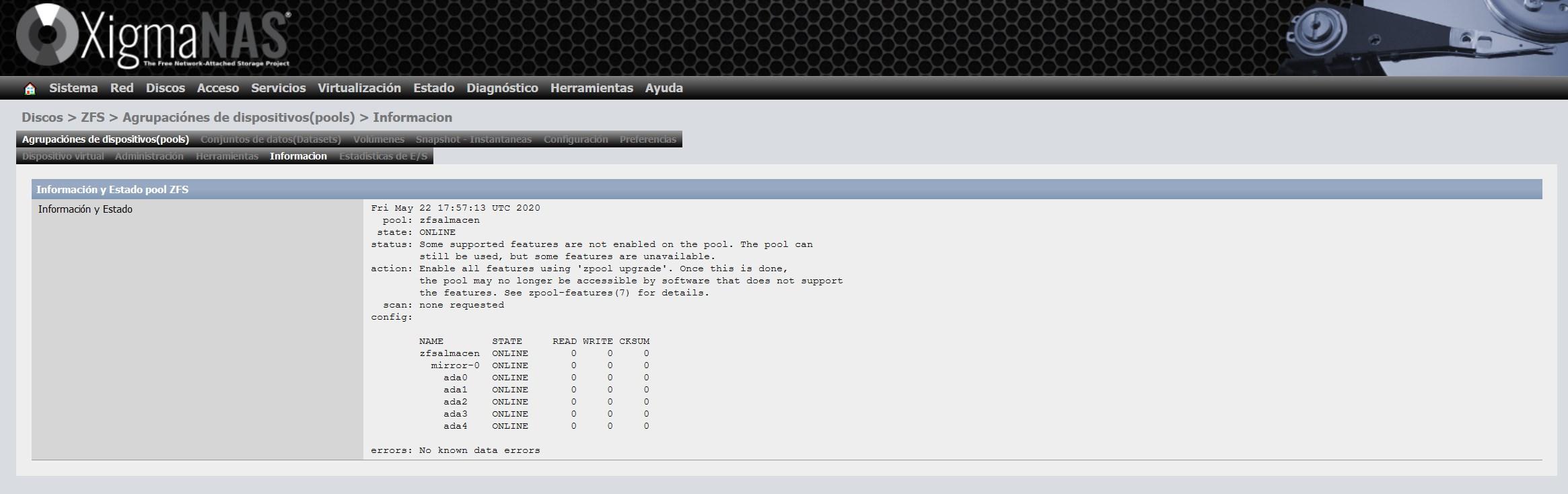
Um es zu aktualisieren, gehen wir zum Abschnitt "Tools" und wählen die Option "Aktualisieren des ZFS-Kernels und Hinzufügen von Unterstützung für neue Funktionen zum Gerätepool (Pool)" und fahren mit dem Assistenten fort, um es zu aktualisieren
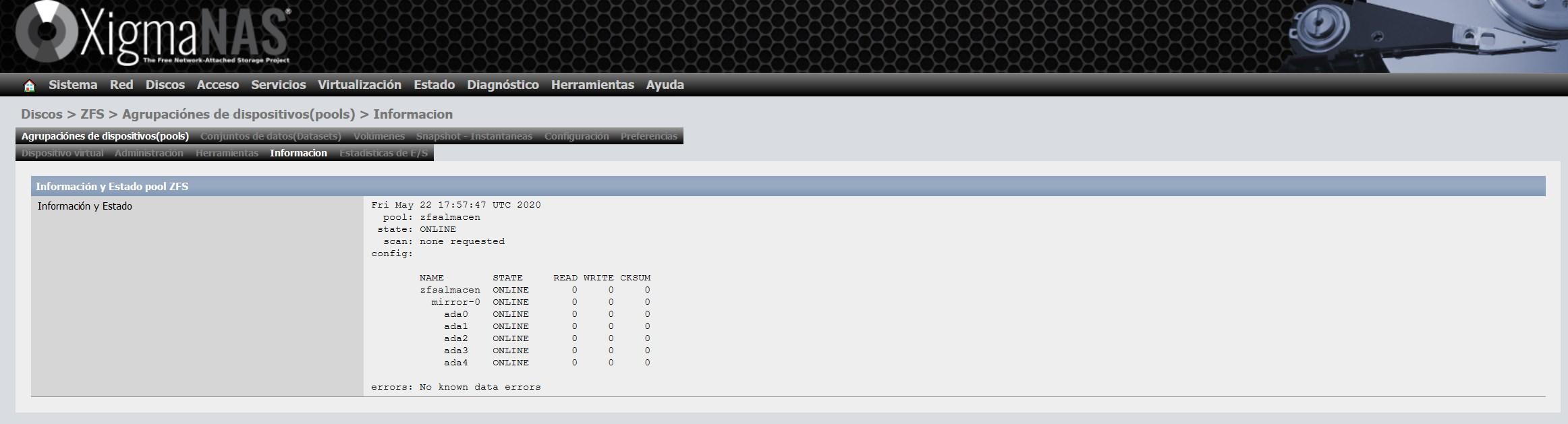
Sobald wir es aktualisiert haben, werden wir keine Benachrichtigung erhalten, wie Sie hier sehen können:
Schritt 4: Erstellen Sie den Datensatz oder das Volume
Das Erstellen eines Datensatzes ist wirklich einfach. Gehen Sie zu «Datensatz (Datensatz)» und klicken Sie auf die Taste «+»:

Innerhalb der Dataset-Konfiguration müssen wir einen Namen und auch den Pool auswählen, in dem wir das Dataset erstellen möchten. Wir haben nur einen Pool erstellt, so dass es keinen Verlust gibt. Hier können wir Echtzeitkomprimierung, Deduplizierung, Synchronisation, ACLs und viele weitere erweiterte Parameter konfigurieren.
Wir müssen uns daran erinnern, dass bei Auswahl der Deduplizierungsoption eine große Menge davon verbraucht wird RAMXigmaNAS selbst warnt uns in seinem Wiki davor.
Die restlichen verfügbaren Konfigurationsoptionen sind folgende:
Sobald das Dataset erstellt wurde, wird es auf diese Weise im zuvor erstellten Pool «zfsalmacen» angezeigt.

Wir dürfen nicht vergessen, dass wir auch Blockgeräte erstellen können, die sogenannten Volumes in ZFS:

Andere ZFS-Optionen
Andere verfügbare Optionen sind Schnappschüsse oder Schnappschüsse. Wir können Millionen von Schnappschüssen erstellen, entweder geplant oder manuell. Um einen Schnappschuss zu konfigurieren, klicken Sie einfach auf das "+", um einen neuen hinzuzufügen:
Wir wählen aus, wovon wir einen Snapshot erstellen möchten. Wir können dies für den gesamten Pool oder nur für einen oder mehrere Datensätze tun, die wir im Pool haben:
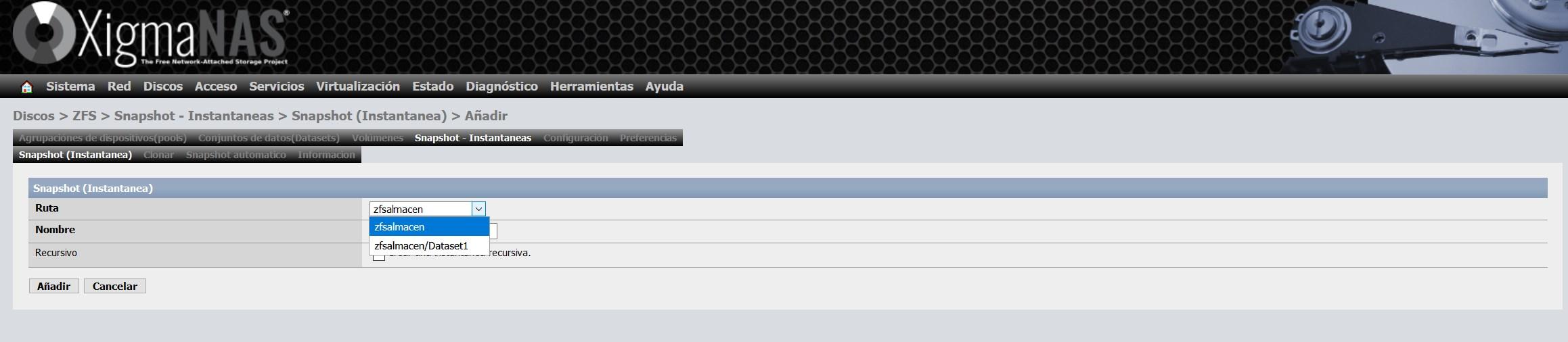
Sobald der Schnappschuss erstellt wurde, sehen wir ungefähr Folgendes:
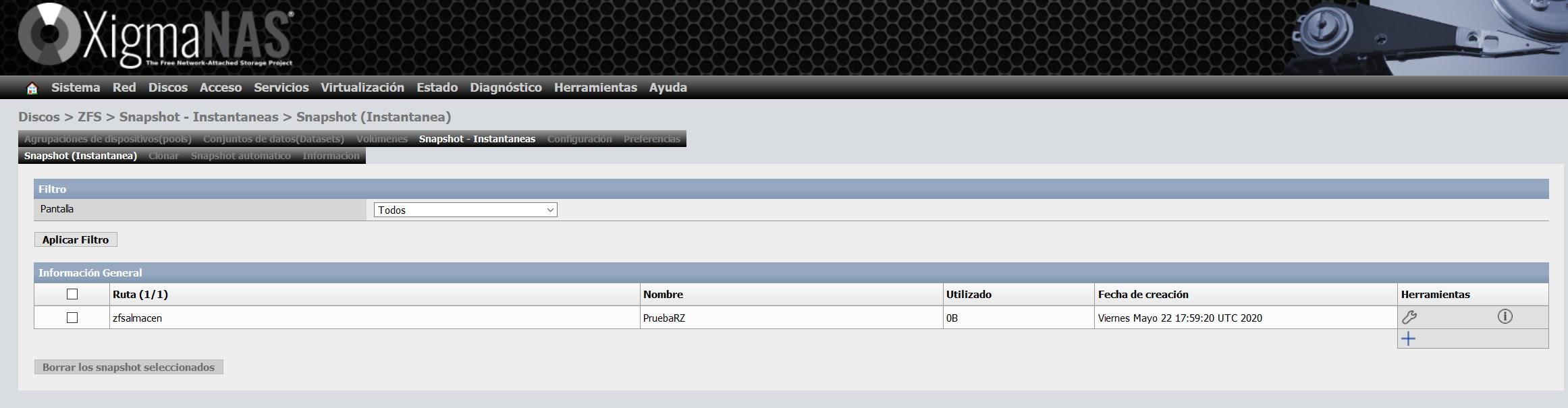
Das Wichtigste ist die Spalte "verwendet", da dieser Snapshot den Platz einnimmt und Änderungen vorgenommen oder Daten gelöscht wurden. Da Snapshots in ZFS enthalten sind, ist die Effizienz wirklich beeindruckend.
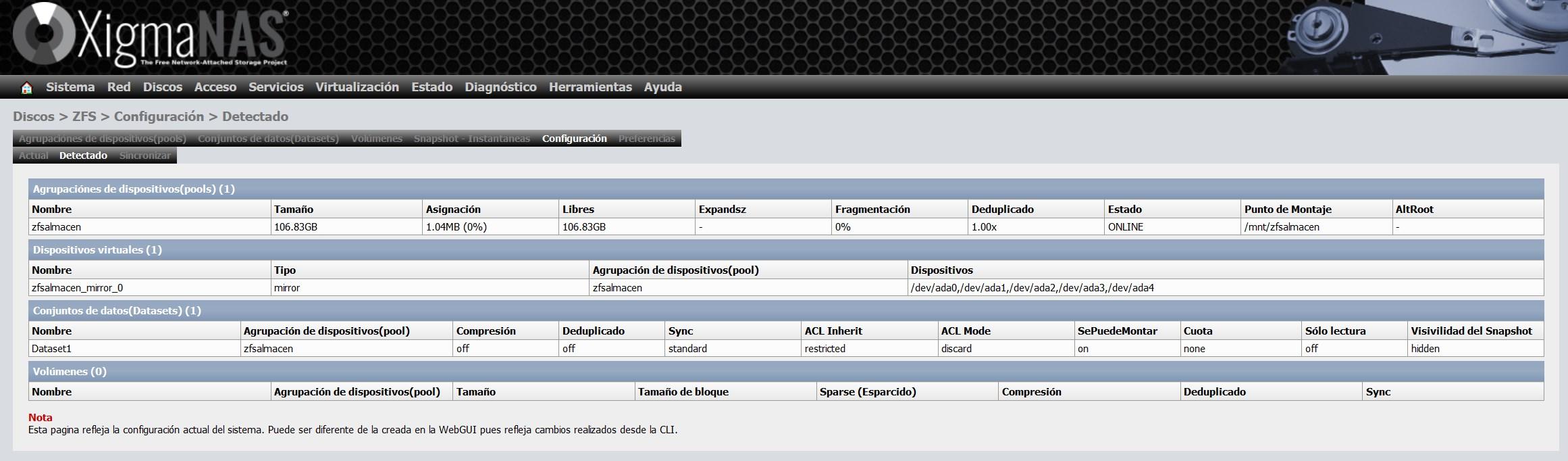
Im Abschnitt "Konfiguration" finden Sie eine Zusammenfassung aller bisher konfigurierten Elemente. Außerdem können wir die virtuellen Geräte, die Pools sowie die erstellten Datasets und Volumes anzeigen.
Im Hauptmenü des Betriebssystems sehen wir, dass wir den Pool «zfsalmacen» haben, und er zeigt den gesamten, belegten und verfügbaren Speicherplatz an.
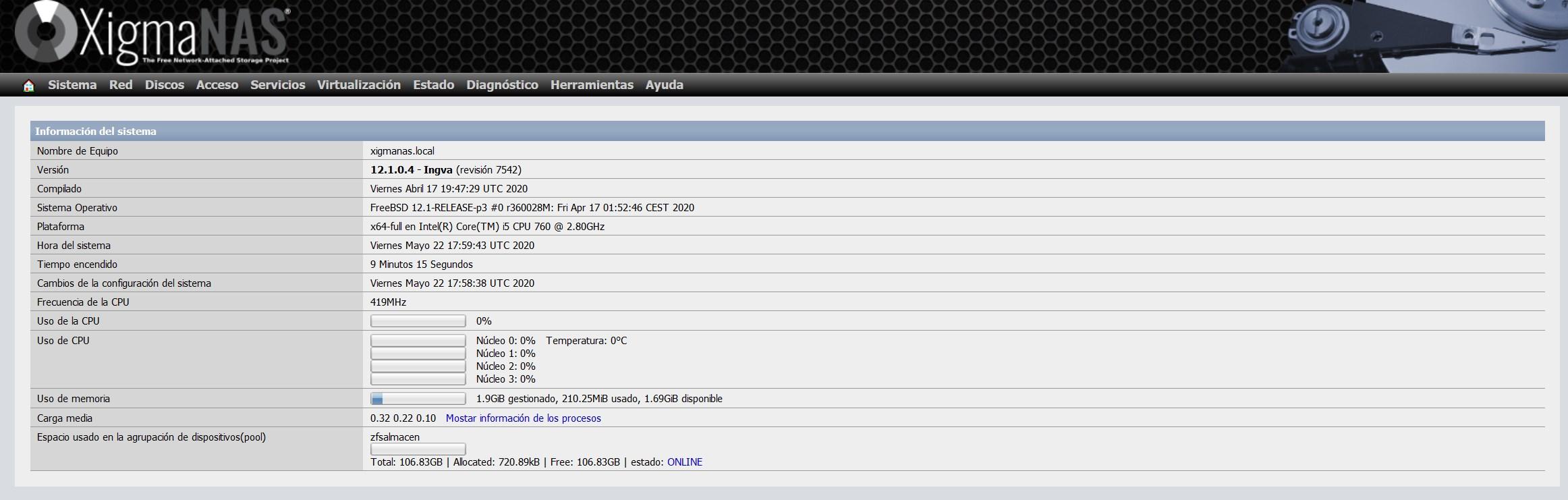
Wie Sie gesehen haben, ist ZFS ein sehr fortschrittliches Dateisystem und ermöglicht uns eine hervorragende Konfigurierbarkeit. Im Falle eines Festplattenfehlers reicht es aus, ihn offline zu schalten, einen neuen hinzuzufügen, ihn dem Pool hinzuzufügen und ein Scrub durchzuführen, um den gesamten Pool zu überprüfen und die Daten neu zu generieren.
Einrichten und Starten von ZFS unter Debian und anderen
Obwohl ZFS aufgrund einiger Probleme mit der Nutzungslizenz ein erweitertes Dateisystem ist, Viele Linux-Distributionen unterstützen dies standardmäßig nicht Daher kann der Start auf vielen Systemen, die die Systemdateien manuell installieren und konfigurieren müssen, etwas mühsam sein.
Wenn wir dieses Dateisystem in unserem Betriebssystem verwenden möchten, können wir es völlig kostenlos herunterladen von seiner Hauptwebsite . Darüber hinaus verfügen die Haupt-Repositorys über vorkompilierte Pakete. Wenn wir sie beispielsweise in Ubuntu installieren möchten, müssen wir sie nur mit apt aus den offiziellen Repositorys herunterladen, zusammen mit den restlichen erforderlichen Paketen wird vollautomatisch installiert.
sudo apt install zfs
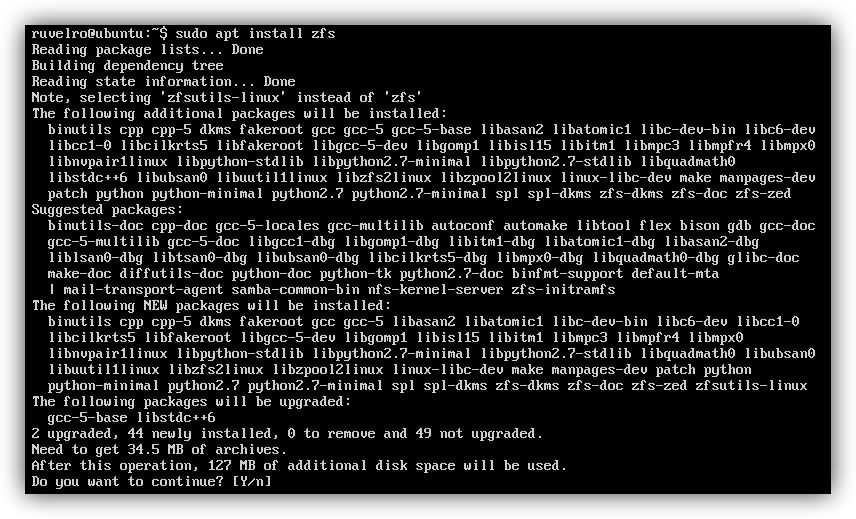
Bei der Verwaltung von Datenträgern verwendet dieses Dateisystem das Konzept « Pool «. Ein ZFS-Pool kann aus einer oder mehreren physischen Festplatten bestehen. Zum Beispiel, wenn wir 3 Festplatten haben und deren Kapazität als einzelne nutzen möchten ( Streifen ) Mit diesem Dateisystem müssen wir einen Pool konfigurieren, der die 3 Festplatten mit dem folgenden Befehl enthält:
sudo zpool create pool-redeszone /dev/sdb /dev/sdc /dev/sdd
Wenn wir nur eine Festplatte haben, legen wir einfach eine Festplatte an und haben einen einzelnen Festplattenstreifen.
Wir können es ändern " Pool-Redeszone Mit dem Namen wollen wir den Pool geben. Wir müssen auch die "sdb", "sdc" und "sdd", die wir in unserem System haben, durch den entsprechenden Buchstaben jeder Festplatte ändern, die wir hinzufügen möchten. Wir können alle angeschlossenen Festplatten mit dem Befehl sehen:
sudo fdisk -l
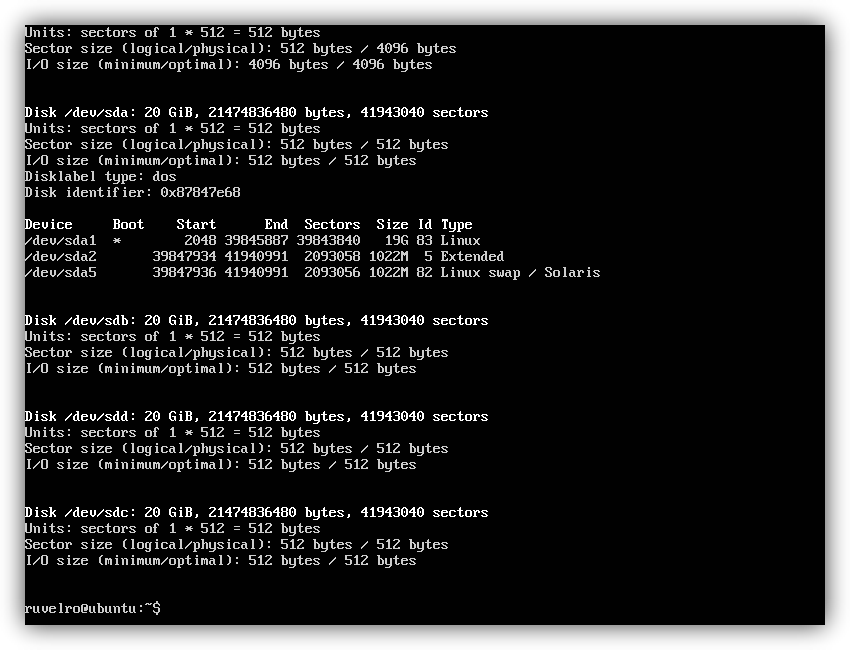 Falls Sie a konfigurieren möchten Spiegel Bei denselben Festplatten müssen wir den Parameter «Spiegel» hinzufügen, der wie folgt bleibt:
Falls Sie a konfigurieren möchten Spiegel Bei denselben Festplatten müssen wir den Parameter «Spiegel» hinzufügen, der wie folgt bleibt:
sudo zpool create pool-redeszone mirror /dev/sdb /dev/sdc /dev/sdd
Wenn wir ein RAIDZ konfigurieren möchten, wäre dies wie folgt (mindestens 3 Festplatten werden benötigt):
sudo zpool create pool-redeszone raidz /dev/sdb /dev/sdc /dev/sdd
Wenn wir ein RAIDZ2 konfigurieren möchten, wäre dies folgendermaßen (mindestens 4 Festplatten werden benötigt):
sudo zpool create pool-redeszone raidz2 /dev/sdb /dev/sdc /dev/sdd /dev/sde
Wenn wir ein RAIDZ3 konfigurieren möchten, wäre dies folgendermaßen (mindestens 5 Festplatten werden benötigt):
sudo zpool create pool-redeszone raidz3 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf
Standardmäßig stellt Linux den Festplattenpool im Stammverzeichnis des Betriebssystems / bereit. Wenn wir also auf ihn und seine Daten zugreifen möchten, müssen wir in das Verzeichnis / pool-redeszone / wechseln.
Wenn wir wollen kennen den Status unserer Scheibe Pool können wir dies tun, indem wir das Terminal eingeben:
sudo zpool status
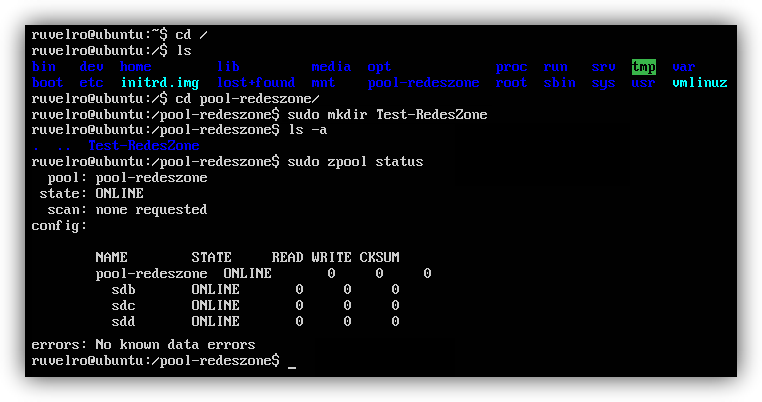 Falls du willst Festplatten zum Pool hinzufügen, Sie tun es mit dem Befehl:
Falls du willst Festplatten zum Pool hinzufügen, Sie tun es mit dem Befehl:
sudo zpool add pool-redeszone /dev/sdx
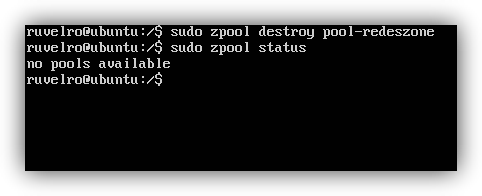
Und zerstören Sie sogar den Pool (mit dem entsprechenden Verlust aller Daten) mit dem Befehl:
sudo zpool destroy pool-redeszone
Andere interessante Optionen sind ZFS-Snapshots. Wir können einen Snapshot wie folgt erstellen:
zfs snapshot pool-redeszone/datos@2020-05-22
Und wir könnten den erstellten Schnappschuss auch folgendermaßen löschen:
zfs destroy pool-redeszone/datos@2020-05-22
Wie wir sehen können, handelt es sich um ein erweitertes Dateisystem für fortgeschrittene Benutzer. Sobald Sie jedoch die grundlegenden Befehle und deren Funktionsweise kennen, ist die Verwaltung und Wartung sehr einfach. Wenn Sie eine Festplatte für den Cache oder für das LOG hinzufügen möchten, wie zuvor erläutert, können Sie auch "Cache" und "Protokoll" hinzufügen, gefolgt von den zur Auswahl stehenden Festplatten. Wir empfehlen Ihnen den Zugriff auf die offizielle Website von OpenZFS Hier finden Sie eine Vielzahl von Ressourcen zur Installation und Verwendung dieses erweiterten Dateisystems.