When we talk about processors for PCs , it is very common to talk about the number of cores and the processing or execution threads, which are generally double the number of cores because HyperThreading technologies in the case of Intel and SMT in the case of AMD what they do is that each core can execute two simultaneous tasks. However, that is a somewhat simple way to explain how multithreading works on a processor, and in this article what we are going to do is explain it to you in greater detail so that you can understand all its ins and outs.
That said, we all know that a processor that has more threads than cores is capable of running more tasks simultaneously, and in fact, the operating system detects the processor as if it actually had as many cores as there were threads. For example, an Intel Core i7-8700K has 6 cores and 12 threads thanks to HyperThreading technology, and Windows 10 recognizes it as a 12-core processor as is (although it is true that it calls them “logical processors”) because for the operating system, its operation is completely transparent.

What is multi-threaded processing?
In computer architecture, multi-threaded processing is the ability of the central processing unit (CPU) to provide multiple threads of execution at the same time, supported by the operating system. This approach differs from multiprocessing and should not be confused; In a multithreaded application, threads share the resources of one or more processor cores, including compute units, cache, and the translation search buffer (TLBL).
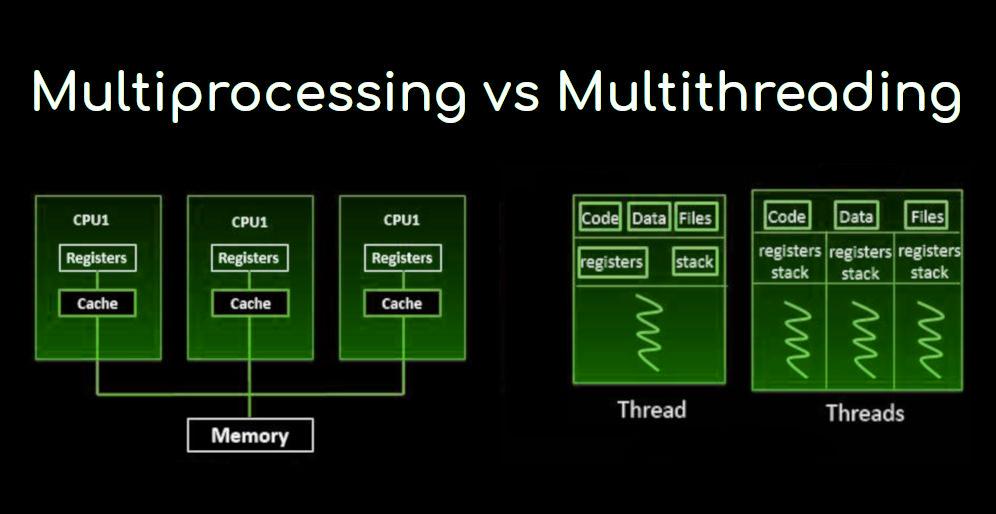
When multiprocessing systems include multiple complete processing units on one or more cores, multiprocessing aims to increase the utilization of a single core by using thread-level parallelism as well as instruction-level parallelism. Since the two techniques are complementary, they are combined in almost all modern system architectures with multiple multi-threaded CPUs and with multi-core CPUs capable of operating with multiple threads.
The multi-threaded paradigm has become more popular as efforts to exploit instruction-level parallelism (that is, being able to execute multiple instructions in parallel) stalled in the late 1990s. This allowed the concept of performance computing emerged from the more specialized field of transaction processing.
Although it is very difficult to further accelerate a single thread or program, most computer systems are actually multitasking between multiple threads or programs and therefore techniques that improve the performance of all tasks result in performance gains. general. In other words, the more instructions a CPU can process at the same time, the better the overall performance of the entire system.
Even multi-threaded processing has disadvantages
In addition to performance gains, one of the benefits of multi-threaded processing is that if one thread has a lot of cache errors, the other threads can continue to take advantage of unused CPU resources, which can lead to faster overall execution. as these resources would have been idle if only a single thread had been running. Also, if one thread cannot use all the CPU resources (for example, because the statements depend on the result of the previous one), running another thread can prevent these resources from going idle.

However, everything also has its negative side. Multiple threads can interfere with each other by sharing hardware resources, such as cache or translation search buffers. As a result, single-threaded execution times are not improved and may degrade, even when only one thread is running, due to lower frequencies or additional pipeline stages that are required to accommodate process switching hardware.
Overall efficiency varies; Intel says its HyperThreading technology improves it by 30%, whereas a synthetic program that only performs one cycle of non-optimized, dependent floating-point operations actually receives a 100% improvement when run in parallel. On the other hand, hand-tuned assembly language programs that use MMX or AltiVec extensions and pre-search for data (such as a video encoder) do not suffer from cache leaks or idle resources, so they do not benefit from a run at all. multi-threaded and may actually see their performance degraded due to share contention.
From a software point of view, the multi-threaded hardware support is fully visible, requiring further changes to both the application programs and the operating system itself. The hardware techniques used to support multithreaded processing are often parallel to the software techniques used for multitasking; Threading scheduling is also a major problem in multithreading.
Types of multi-thread processing
As we said at the beginning, we all have the conception that multi-threaded processing is simply process parallelization (that is, executing several tasks at the same time), but in reality things are a bit more complicated than that and there are different types multi-thread processing.
Multiple “coarse-grained” threads

The simplest type of multithreading occurs when a thread runs until it is blocked by an event that would normally create a long latency lock. Such a crash could be a lack of cache that has to access memory off-chip, which can take hundreds of CPU cycles for the data to come back. Instead of waiting for the crash to resolve, the processor will switch execution to another thread that was already ready to run, and only when the data from the previous thread has arrived will it be put back into the ready-to-run threads list.
Conceptually, this is similar to cooperative multitasking used in real-time operating systems, in which tasks voluntarily give up processor runtime when they need to wait for some kind of event to happen. This type of multithreading is known as “block” or “coarse-grained.”
Interleaved multithread
The purpose of this type of multi-threaded processing is to remove all data dependency locks from the execution pipeline. Since one thread is relatively independent of others, there is less chance that an instruction in a pipeline stage needs an output from a previous instruction in the same channel; Conceptually, this is similar to the preventative multitasking used in the operating system, and an analogy would be that the time interval given to each active thread is one CPU cycle.
Of course, this type of multi-threaded processing has a main disadvantage and that is that each pipeline stage must track the thread ID of the instruction it is processing, which slows down its performance. Also, since there are more threads running at the same time in the pipeline, the shares such as the cache must be larger to avoid errors.
Parallel multithreading
The most advanced type of multithreading applies to processors known as superscalars. Whereas a typical superscalar CPU issues multiple instructions from a single thread on each CPU cycle, in simultaneous multi-threaded processing (SMT) a superscalar processor can issue instructions from multiple threads on each cycle. Recognizing that any thread has a limited amount of instruction-level parallelism, these multithreading attempts to exploit the parallelism available across multiple threads to reduce waste associated with unused spaces.
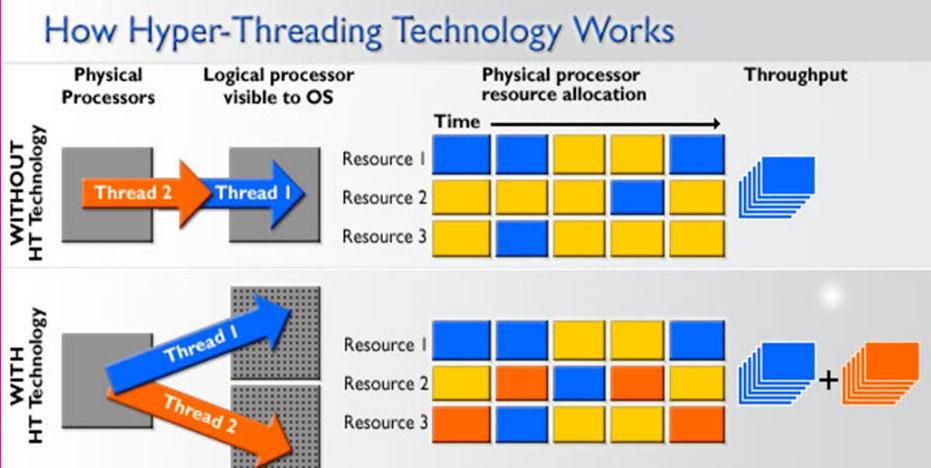
To distinguish the other types of SMT multithreaded processing, the term “temporary multithreaded” is often used to indicate when single-threaded instructions can be issued at the same time. Implementations of this type include DEC, EV8, Intel’s HyperThreading Technology, IBM Power5, Sun Mycrosystems UltraSPARC T2, Cray XMT, and AMD’s Bulldozer and Zen microarchitectures.