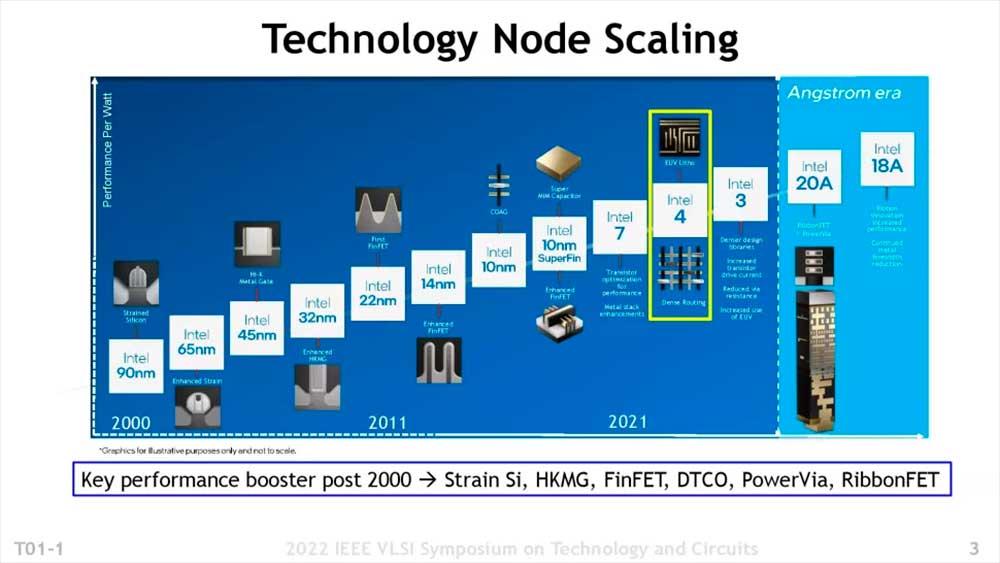
Es war dieses Jahr 2022 auf dem IEEE VLSI-Symposium, wo Intel hat den ersten lithografischen Prozess für Hochleistungschips des eigenen Unternehmens und dank ASML-Scannern mit EUV-Technologie vorgestellt. Obwohl das Unternehmen in diesem Rennen den letzten Platz belegt, ist die Realität, dass es durch die Vordertür eintritt und seine Konkurrenten wirklich erschreckt, insbesondere wenn wir berücksichtigen, dass es Vollgas gibt. So ist Intel 4 .
Die Ergebnisse sind wirklich beeindruckend für einen einzelnen Knotensprung und beweisen, dass Intel aufgrund von Verzögerungen in seinem 10-nm-Knoten, der jetzt Intel 7 heißt, seit vielen Jahren mit echter Unterlegenheit konkurriert. Intel 4 ist seinerseits ein Sprung nach vorne. ziemlich interessant, das ruft die Wette (spät, ja) und bringt das Unternehmen nach und nach wieder an die Spitze.

Fünf Knoten in 4 Jahren, die Wette beginnt mit Intel 4
Intel 7 wurde mehr wegen der Investition des Unternehmens und der Tatsache, dass Investoren ein Auge darauf hatten, auf den Markt gebracht, als wegen der tatsächlichen Leistung. Es ist wahr, dass es ein Sprung nach vorne war, aber in jeder Hinsicht zu einem enormen Preis. Die Lösung ist zumindest in erster Linie Intel 4 und… Es ist sehr vielversprechend.
Die Verbesserungen sind sehr interessant und selten können wir solche Zahlen nennen:
- Erste Generation EUV-Lithographie .
- Frequenzsprung bei gleicher Leistung von 21.5% .
- Bei gleicher Frequenz wird die Leistung um reduziert 40% .
- 2X Verbesserung der Bereichsskalierung.
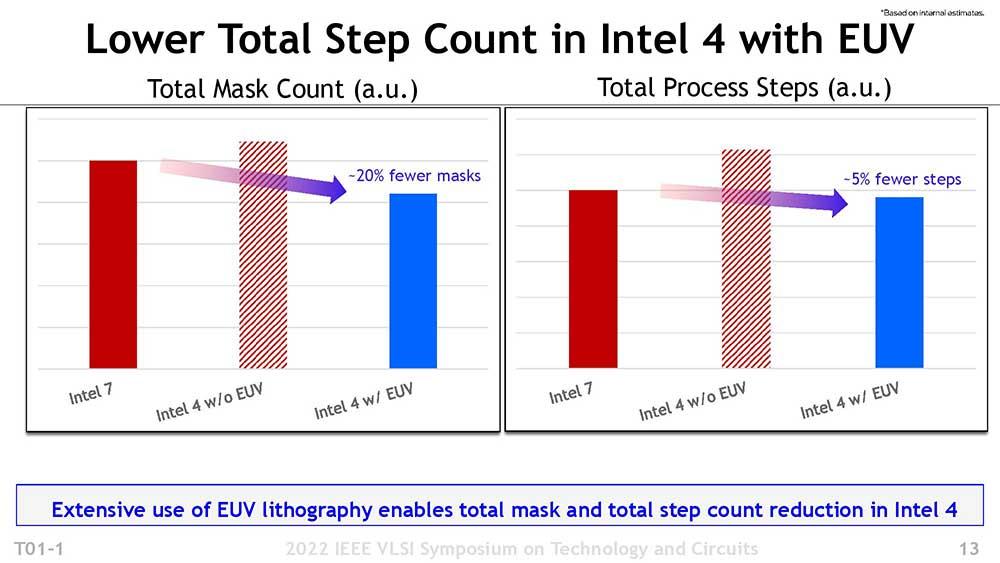
All dies gegen den aktuellen Intel 7-Lithografieprozess, der im Vergleich zu seinem Vorgänger der dichteste war… Bis jetzt. Wenn wir Punkt für Punkt aufschlüsseln, werden wir besser verstehen, was aufgedeckt wurde.
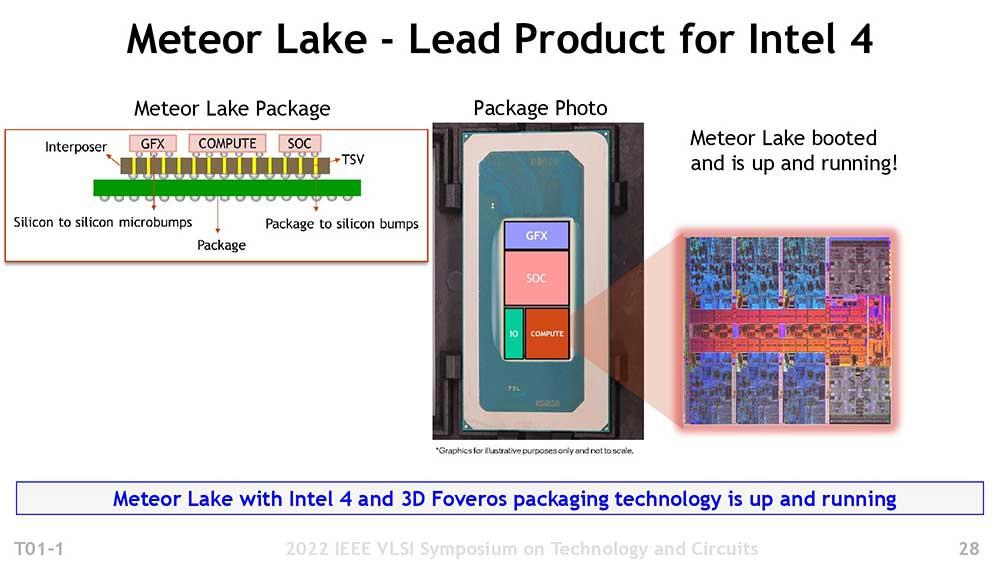
Zunächst einmal wurde die EUV-Lithographie dank ASML-Scannern erreicht, für deren Aufbau Intel fast zwei Jahre gebraucht hat, um genügend Wafer pro Stunde zu erzeugen, um genügend Chips zu sichern. Es besteht aus einer ziemlich hohen Anzahl von Schichten, 18 insgesamt , was schockierend ist, wenn man bedenkt, dass Intel 7 17 davon hat. Dies werden wir auch bei Intel 3 in die gleiche Richtung sehen, aber im Moment gibt es keine Daten.
Der Frequenzsprung ist am interessantesten, da weder TSMC noch Samsung mit EUV haben ähnliche Werte erreicht und wenn wir es auf den aktuellen Core 12 hochrechnen, hätten wir Frequenzen von 6.6 GHz in der Zukunft Core 14, verrückte Zahlen, von denen wir nicht einmal wissen, ob sie in dieser Hinsicht mit der Architektur machbar und kompatibel sind, wo es ohne Zweifel eine Steigerung geben wird.
Wenn sich Intel für Effizienz entscheidet, kann das Ergebnis ein Hit am unteren Ende sein
Und es ist so, dass Intel normalerweise zwei Bibliotheken für jeden Knoten erstellt: eine mit hoher Dichte und eine mit hoher Leistung. Im Fall von Intel 4 wird dies zu einer kleinen Wendung führen, da die Bibliotheken für hohe Dichte auf diesem Knoten anscheinend nicht verfügbar sind, sodass nur hohe Leistung als solche übrig bleibt.
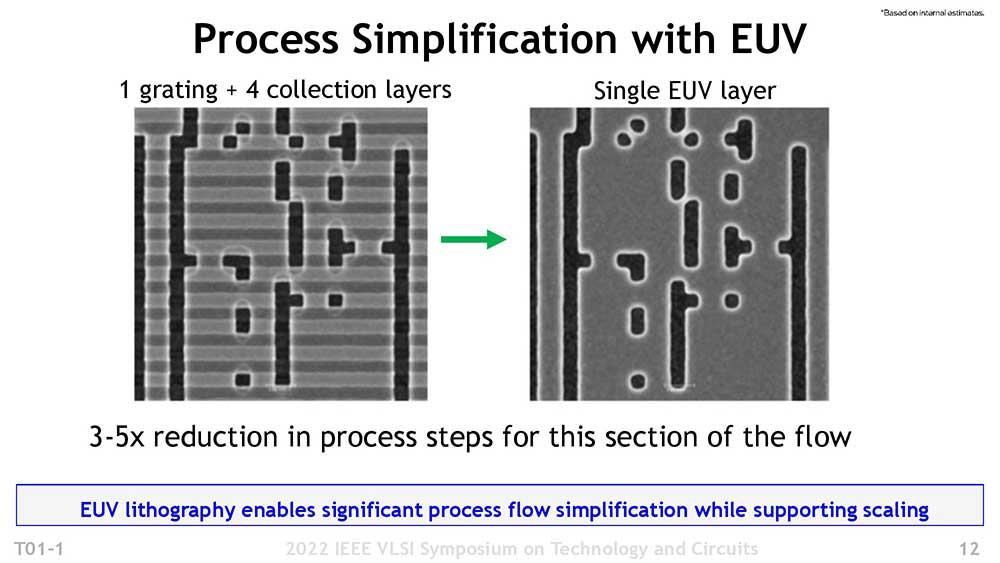


Allerdings finden wir innerhalb der Hochleistung technisch gesehen zwei oben genannte Ansätze: die maximal verfügbare Frequenz aussetzen, den Knoten seiner maximalen Effizienz aussetzen. Entscheidet sich Intel für beide Ansätze durch eine Segmentierung der Bandbreite, könnten wir mit schnellen und vor allem sehr energieeffizienten Prozessoren fündig werden, was für günstige Gaming-Laptops und Arbeitsrechner sehr interessant wäre, denn wenn sie es mit 5.5 GHz schaffen 40 % weniger Verbrauch würden wir von einem Core i9-12900KS mit nur 125 Watt sprechen, Zahlen, die jetzt undenkbar sind.
| Intel 4 | Intel 7 | TSMC-N5 | TSMC N3 | |
| HP-Bibliotheksdichte | 160MTr/mm^2 (geschätzt) | 80MTr/mm^2 | 130MTr/mm^2 (geschätzt) | 208 Mtr/mm^2 (geschätzt) |
| HD-Bibliotheksdichte | Keine geplant | 100MTr/mm^2 | 167 Mtr/mm^2 (geschätzt) | 267 Mtr/mm^2 (geschätzt) |
| Logikdichte | 2x | 2.7x | 1.83x | 1.6x |
| Leistung (ISO-Leistung) | 1.2X | 1.15x | 1.15x | 1.11x |
Die Verbesserung der Bereichsskalierung ist die technische Berechnung von allem, was gesagt wurde. Und es ist so, dass die HP (High Power)-Bibliothek derzeit eine Dichte von aufweist 160 MT/mm2 (es könnte bei ein paar Millionen Transistoren noch verbessert werden, aber nicht viel), wo die Dichte bis zu ansteigt 2X Wenn wir berücksichtigen, dass Intel 7 bei 80 MT/mm2 lag, mit einer ISO-Ausbeute von 1.2X .

Sein direkter Konkurrent ist das TSMC N5 und in geringerem Maße das Samsung N3 bereits mit GAA