Eines der Details, das nach den Präsentationen des NVIDIA RTX 3000 war die Tatsache seiner Leistung in FP32. Bisher ist der Fortschritt bei NVIDIA so genannt TFLOPS-Shader war mehr oder weniger skalierbar, aber mit Ampere haben sich diese Zahlen verdoppelt und die Alarme vieler Benutzer ausgelöst, die mit der Idee fortfahren, dass die FP32-Leistung gleichbedeutend mit der Richtigkeit des Vergleichs von Architekturen ist. Warum passiert dies?
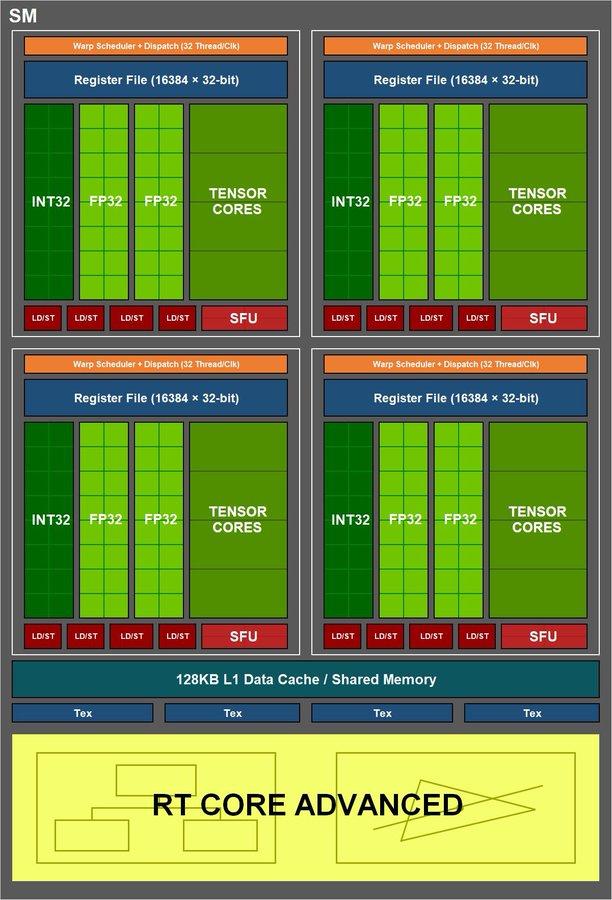
Die Erklärung hat viel mit einer der grundlegenden Änderungen in der Architektur und der von NVIDIA als 1/2 FP32 bezeichneten Rate zu tun. Dieser Name stammt nicht von jetzt an, sondern von der Turing-Architektur und ihren SMs, bei denen, wie wir wissen, Ganzzahlen von Floats getrennt wurden, was dazu führte, dass drei verschiedene Engines eingeschlossen werden konnten, jedoch mit einigen Nachteilen.

Die TFLOPS-Rate der FP32-Shader steht in direktem Zusammenhang mit der CUDA-Anzahl
"Magisch" (beachten Sie die Ironie) NVIDIA hat einseitig beschlossen, die Anzahl der Shader auf seinen Ampere-Grafikkarten zu verdoppeln. Eine Marketingaktion, die immer noch eine kleine Grundlage hat, die unaufhaltsam mit den Leistungsdaten in Shaders TFLOPS verknüpft ist.
Um alles zu verstehen, müssen wir von der Basis von Volta als Architektur ausgehen, da es der Pionier im 1/2 FP32 war, über den NVIDIA spricht und der Turing zur gleichen Aufgabe zog. In beiden Architekturen war jeder SM in der Lage, 1 Paket mit 32 Befehlen pro Takt auszuführen, in das unterteilt werden musste 16 Operationen für FP32 und 16 Operationen für INT32 , oder was ist das gleiche, 16 Anweisungen für Gleitkomma und 16 für Zahlen. Ganzzahlen für jeden Taktzyklus.
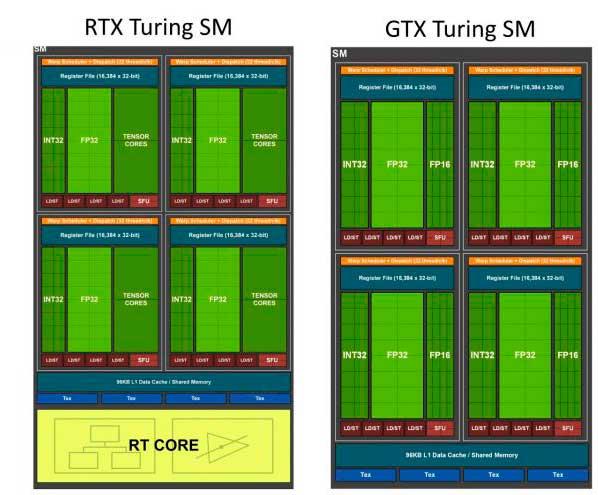
Warum so? Nun, weil NVIDIA in erster Linie als allgemeine Architektur die Tatsache gemietet hat, dass es weniger FP32-Operationen gab, wenn es im Gegenzug das Rendering jedes Frames in die drei oben genannten Engines aufteilte, um mit Ray Tracing oder DLSS arbeiten zu können.
Mit anderen Worten, es opferte die FP32-Kapazität für INT32 im Austausch für den größten Sprung in der Architektur seit 10 Jahren, da es wusste, dass diese Änderung einen leichten Leistungsvorteil für jeden SM hatte und ihm teilweise die Möglichkeit gab, mit BVH- und AI-Algorithmen zu arbeiten Spiele.
Ampere bringt die Dinge wieder an ihren Platz zurück
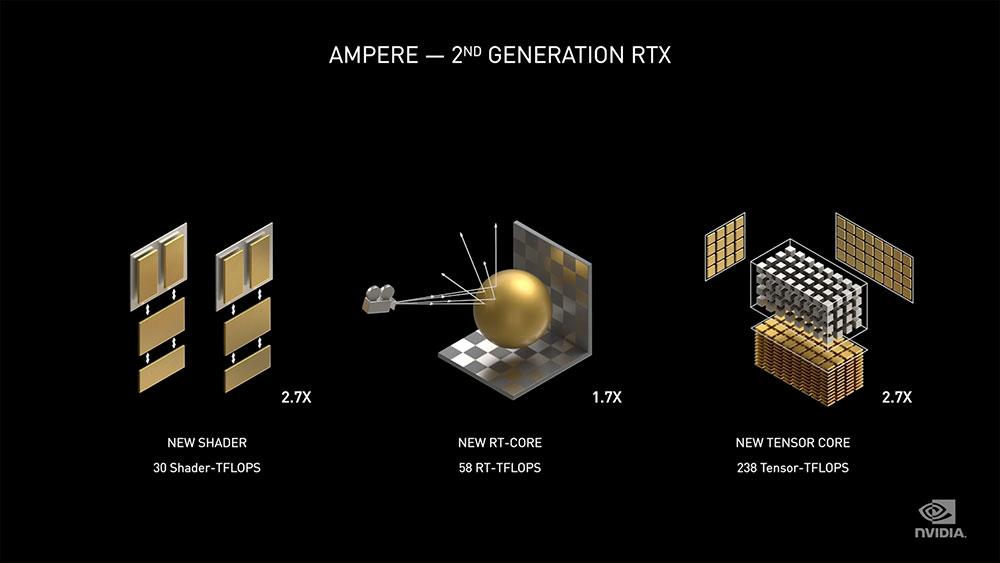
Mit dem RTX 3000 und der Ampere-Architektur bricht NVIDIA mit diesem 1/2 FP32 und führt 32 FP32-Operationen für jeden Takt innerhalb des SM erneut aus (wir könnten zumindest theoretisch von 4 Motoren anstelle von drei sprechen), wofür unter dem Lupe und Optik des Unternehmens verdoppeln auf magische Weise die Anzahl der gesamten Shader in den Spezifikationen, aber die Realität ist, dass dies nicht wirklich so funktioniert, weit davon entfernt, da NVIDIA nur einen Teil der Motoren verdoppelt hat. Wenn der Rest intakt bleibt, entspricht die Leistung nicht der Verdoppelung der Anzahl der Shader.
- RTX 3090 -> 10496/2 = 5248
- RTX 3080 -> 8704/2 = 4352
- RTX 3070 -> 5888/2 = 2944
Die tatsächliche Anzahl der Shader der drei NVIDIA-Referenzkarten beträgt heute nur noch die Hälfte, und dies beeinflusst die logische Berechnung ihrer theoretischen Leistung im FP32. Wir konzentrieren uns auf die Theorie, da wir bereits die Farce gesehen haben, die dieser Wert beim Vergleich der Leistung in Spezifikationen mit der tatsächlichen Leistung darstellt.
Lassen Sie uns daher erklären, wie NVIDIA seine Leistung auf magische Weise hätte verdoppeln können.
Von der Verdoppelung der Leistung im FP32 bis hin zur Markierung einer „kleinen“ Marge

Wenn wir uns die offiziellen NVIDIA-Spezifikationen ansehen, erhält der RTX 3090 eine FP32-Leistung von 35.58 TFLOPS oder wie sie es nennen: Shader TFLOPS. Diese Zahl ist sehr einfach zu berechnen und zeigt den schrecklichen Fehler beim Vergleich von TFLOPS als Standardmaß zwischen Hardwarekomponenten:
Shader x Frequenz x 2 Operationen pro Zyklus x 1 GPU
Im Falle des RTX 3090 werden wir bekommen 10,496 x 1,700 x 2 x 1 -> 35,686,400 FLOPS oder 35,686 TFLOPS (unter der Annahme einer 100% igen Effizienz in der Architektur, was auf keinem Chip unmöglich ist). Logischerweise ist dieser Wert für das, was oben kommentiert wurde, völlig unrealistisch und spiegelt keine Überlegenheit gegenüber einem RTX 2080 Ti wider, der fast das Dreifache seiner Leistung beträgt.
Die richtige Nummer in TFLOPS wäre 17,843 TFLOPS oder 32.66% mehr Gleitkomma-Leistung als ein RTX 2080 Ti. Dieser Unterschied bezieht sich jedoch nur auf FP32 und lässt beispielsweise die Leistung in INT32 aus.
Was wir bisher gesehen haben, ist, dass der Unterschied in der Leistung ist zwischen 24% und 29% ungefähr und abhängig von der gewählten Auflösung, aber wie wir sehen, ist es sehr weit von dem Marketing entfernt, das das Unternehmen zu etablieren versucht hat und das sich leider selbst durchsetzen wird. mit seinen TFLOPS Shadern.