Computere kan ikke længere lide deres begyndelse med at køre en proces, og tak, de har nu mulighed for at køre et stort antal programmer parallelt. Nogle af dem ser vi i vores spil, andre er usynlige, men der er de ved at blive henrettet af CPU. Er der en sammenhæng mellem processerne i softwaren og udførelsestråde med hardwareens?
Vi hører eller læser ofte koncepttråden, når vi hører om nye CPU'er, men også i softwareverdenen. Derfor har vi besluttet at forklare forskellene mellem processer eller tråde til udførelse i softwaren og deres væsentlige ækvivalenter i hardwaren.
Processer i softwaren

I sin enkleste definition er et program intet mere end en række instruktioner ordnet sekventielt i hukommelsen, som behandles af CPU'en, men virkeligheden er mere kompleks. Enhver med lidt kendskab til programmering ved, at denne definition svarer til de forskellige processer, der udføres i et program, hvor hver proces kommunikerer med de andre og findes i en del af hukommelsen.
I dag har vi et stort antal programmer, der kører på vores computer og derfor et meget større antal processer, der kæmper for at få adgang til CPU -ressourcerne, der skal udføres. Med så mange processer på samme tid er det nødvendigt med en leder for at styre dem. Dette arbejde er i hænderne på operativsystemet, som, som om det var et trafikstyringssystem i en storby, har ansvaret for at styre og planlægge de forskellige processer, der skal udføres.
Imidlertid omtales softwareprocesser ofte som udførelsestråde, og det er ikke en dårlig definition, hvis vi tager hensyn til deres natur, men definitionen falder ikke sammen i begge verdener, så de er ofte forvirrede, og det fører til flere misforståelser omkring hvordan multitråds hardware og software fungerer. Derfor har vi i denne artikel besluttet at kalde trådene i softwareprocesserne for at adskille dem fra hardwarens.
Konceptet med en boble eller stop i en CPU
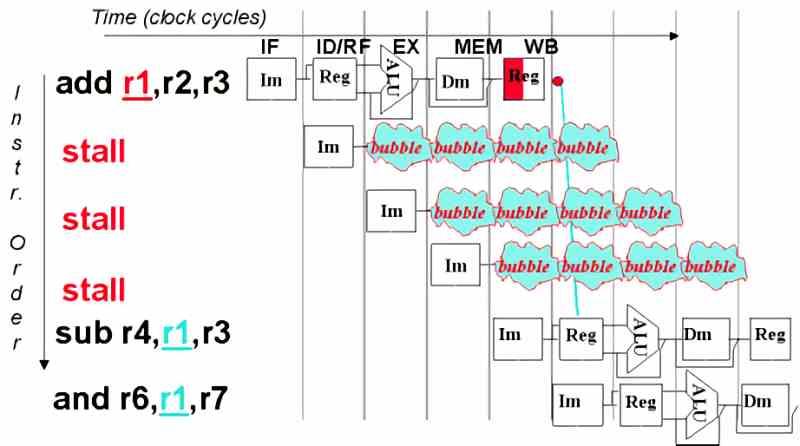
En boble eller et stop i udførelsen sker, når en proces, der af en eller anden grund udfører CPU'en, ikke kan fortsætte, men heller ikke er blevet afsluttet i operativsystemet. Af denne grund har operativsystemer mulighed for at suspendere en udførelsestråd, når CPU'en ikke kan fortsætte og tildele arbejdet til en anden tilgængelig kerne.
I hardware -verdenen dukkede op i begyndelsen af 2000'erne, det vi kalder multithreading med Hyperthreading af Pentium IV'erne. Tricket var at kopiere CPU'ens styreenhed, der er ansvarlig for indfangning og afkodning. Med dette blev det opnået, at operativsystemet ender med at se CPU'en som om de var to forskellige CPU'er og tildelte opgaven til den anden styreenhed. Dette fordobler ikke strømmen, men da selve CPU'en sad fast i den ene udførelsestråd, gik den straks over på den anden for at drage fordel af den nedetid, der opstod og få mere ydeevne fra processorerne.
Multithreading på hardwareniveau ved at kopiere styreenheden, som er den mest komplekse del af en moderne CPU, øger strømforbruget fuldstændigt. Derfor har CPU'erne til smartphones og tablets ikke hardware multithreading i deres CPU'er.
Ydeevnen afhænger af operativsystemet
Selvom CPU'er kan eksekvere to udførelsestråde pr. Kerne, er det operativsystemet, der er ansvarligt for at styre de forskellige processer. Og i dag er antallet af processer, der kører på et operativsystem, større end antallet af kerner, en CPU kan køre samtidigt.
Da operativsystemet har ansvaret for at styre de forskellige processer, er det derfor også den, der har ansvaret for at tildele dem. Dette er en meget let opgave, hvis vi taler om et homogent system, hvor hver kerne har den samme kraft. Men i et totalt heterogent system med kerner af forskellige kræfter er dette en komplikation for operativsystemet. Grunden til dette er, at den har brug for en måde at måle, hvad beregningens vægt er for hver proces, og dette måles ikke kun ved, hvad den optager i hukommelsen, men ved kompleksiteten af instruktionerne og algoritmerne.
Springet til hybridkerner er allerede sket i verden af ARM processorer, hvor operativsystemer som f.eks iOS , Android har været nødt til at tilpasse sig brugen af kerner af forskellige forestillinger, der arbejder samtidigt. På samme tid har styreenheden for fremtidige designs været nødt til at blive yderligere kompliceret i x86. Målet? At hver proces i softwaren udføres i den relevante tråd på hardwaren, og at CPU'en selv har mere uafhængighed i udførelsen af processerne.
Hvordan er udførelsen af processer på GPU'erne?

GPU'erne i deres shader -enheder udfører også programmer, men deres programmer er ikke sekventielle, hver udførelsestråd består snarere af en instruktion og dens data, som har tre forskellige betingelser:
- Dataene findes ved siden af instruktionen og kan udføres direkte.
- Instruktionen finder dataets hukommelsesadresse og skal vente på, at dataene kommer fra hukommelsen til skyderenhedens registre.
- Dataene afhænger af udførelsen af en tidligere udførelsestråd.
Men a GPU kører ikke et operativsystem, der kan håndtere de forskellige tråde. Løsningen? Alle GPU'er bruger en algoritme i planlæggeren for hver skyggeenhed, svarende til styreenheden. Denne algoritme kaldes Round-Robin og består i at give en eksekveringstid i urcyklusser til hver udførelse / instruktionstråd. Hvis dette ikke er løst på det tidspunkt, går det til køen, og den næste instruktion på listen udføres.
Shader -programmerne er ikke kompileret i koden, da der er væsentlige forskelle i den interne ISA for hver GPU, er controlleren ansvarlig for at kompilere og pakke de forskellige eksekveringstråde, men programkoden er ansvarlig for administrationen dem. . Så det er et andet paradigme end hvordan CPU'en udfører de forskellige processer.