RTX 3000 kom ud for et par måneder siden og erstattede RTX 2000, men hvordan sammenligner begge arkitekturer sig, og hvad er ændringerne fra generation til generation, er det et så spektakulært spring som NVIDIA sælger eller er de ret små ændringer? Vi forklarer forskellene mellem Turing- og Ampere-arkitekturen.
Er det værd at bytte en RTX 2000 mod en tilsvarende i RTX 3000? Fra vores synspunkt, hvis du vil have maksimal ydelse, ja, men samtidig mener vi, at det er vigtigt at afmystificere begge generationer af GPU'er, så vi vil sammenligne dem.

Hvordan er Turing og Ampere det samme i arkitektur?

Der er en række elementer, hvor der ikke har været ændringer fra en generation til den næste, så der har ikke været nogen interne ændringer, og de fungerer stadig det samme i Ampere sammenlignet med Turing.
Listen over emner, der ikke er blevet ændret, åbnes af kommandoprocessorerne midt i begge GPU'er. Hvilken er den del, der har ansvaret for at læse kommandolisterne fra hovedmenuen RAM og organisere resten af GPU elementer. Efterfulgt af de faste funktionsenheder til gengivelse via rasterisering: rasterenheder, tessellation, teksturer og ROPS.
Den interne hukommelsesstruktur har heller ikke ændret sig, det vil sige cachehierarkiet, der forbliver det samme i Ampere og ikke har ændret sig med hensyn til Turing, da det forbliver det samme i begge arkitekturer, hvor det eneste element i hukommelseshierarkiet er GDDR6X-hukommelsen interface brugt af GPU'er baseret på NVIDIA GA102-chip, såsom RTX 3080.
I hvilke elementer der er forskellige fra Turing og Ampere

Vi er nødt til at gå ind i SM-enhederne for at se ændringer i den Ampere-baserede RTX 3000 sammenlignet med den Turing-baserede RTX 2000, og de er ændringer, der er foretaget på tre forskellige fronter:
- Flydende punkt enheder i FP32
- Tensorkernerne.
- RT-kernerne.
Uden for disse elementer og uden for antallet af SM-enheder, der er højere i GeForce Ampere end i GeForce Turing, er der ingen ændring, så NVIDIA har genbrugt en god del af hardware fra den forrige generation for at skabe den nye. . Og før du drager den konklusion, at dette er noget negativt, lad mig fortælle dig, hvor almindeligt inden for hardware design.
Ændringer i flydende punkt på GeForce Ampere SM'er

På alle GeForces op til Pascal blev alle floating point-enheder kaldet CUDA-kerner af NVIDIA. Så uden videre, uden at præcisere, hvad det betød ud over flydende beregninger. De antydede, at de var 32-bit-præcise flydende punktenheder.
Faktisk var CUDA-kernerne faktisk logikoaritmetiske enheder til 32-bit floating point-beregning, men også enheder af samme type til 32-bit heltal. Særhed? De fungerede skiftet på en sådan måde, at begge typer ikke kunne fungere på samme tid.

Med Turing ændrede ting sig, og hvad der kaldes samtidig udførelse dukkede op, årsagen er, at GPU-tråden viser kombinerede tråde med heltal og flydende punkt og ikke nåede den maksimale pladsbesættelse af SIMT-enheden med hver underol, så NVIDIA besluttede at Turing at anvende samtidig udførelse. I hvilken en bølge af 32 udførelsestråde kan udføres på en kombineret måde mellem heltal og flydende ALU'er på samme tid, så længe disse er tilgængelige.
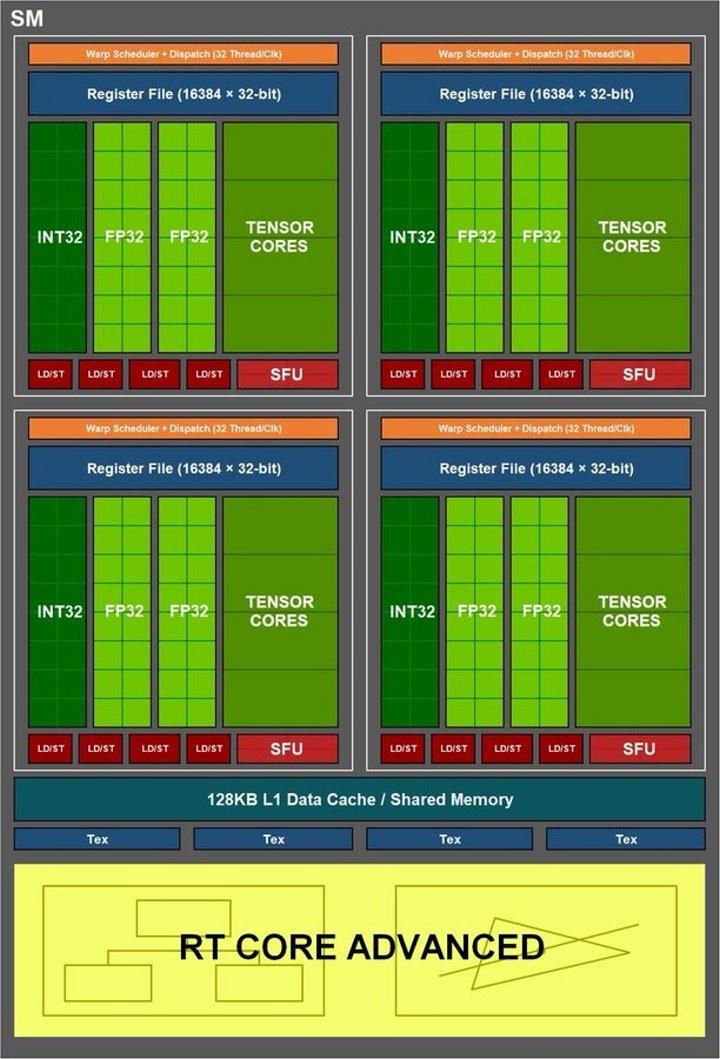
Dette betyder, at 32-bølgefordeling, som er standardstørrelsen for NVIDIA GPU'er, kan fordeles på op til 16 heltalstråde og 16 tråde med flydende punkt. Men nogen hos NVIDIA kom med at foreslå en ændring for Ampere, som er, at sæt af heltal ALU'er skiftes med et andet sæt flydende ALU'er, som ikke kræver ændring af resten af SM.
Derfor fordobles beregningshastigheden, målt i TFLOPS, på bestemte tidspunkter, og når betingelsen om, at en 32-leder flydende punktbølge kommer ind. Selvom kun når de er opfyldt under disse betingelser, og hvis vi havde en enhed til at måle TFLOPS-hastigheden, ville vi se, at det ikke er den, NVIDIA siger, hvilket giver den maksimale top i sine specifikationer, men at den ville have svingninger.
Tensorkerner på GeForce Ampere

Tensorkerner er systoliske arrays, der først blev frigivet på NVIDIA Volta GPU'er, og de er systoliske arrays, der er den type eksekveringsenhed, der bruges til at fremskynde AI-baserede algoritmer. Disse enheder bruger i modsætning til RT-kerne SM-styreenheden og kan ikke bruges på samme tid som flydende punkt og heltalsenheder, så selvom de kan arbejde samtidigt, gør de det ved at fjerne strøm fra resten. enheder undtagen RT-kerner.
Hvis vi tilføjer den ALU-mængde, som RT-kernerne danner mellem den ene generation og den anden, vil vi se, at der er den samme mængde, men med en anden konfiguration. I Turing har vi 8 enheder, 2 pr. Underkerne, på 64 ALU'er hver i en Tensor 4 x 4 x 4-konfiguration. Mens de er i Ampere har Tensor Cores en konfiguration på 4 enheder, 1 pr. Underkerne, med 128 ALU'er. for hver af dem.
RT-kerner på GeForce Ampere
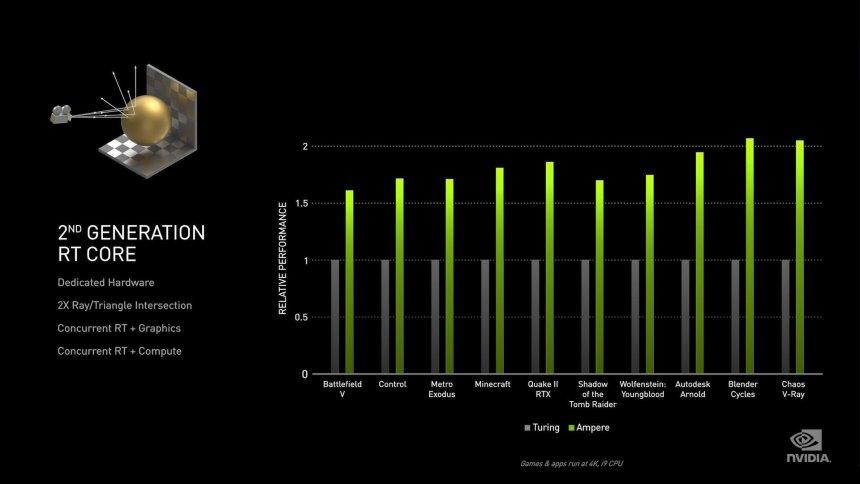
RT-kernerne er den mindst kendte del af alle, da NVIDIA ikke har givet nogen oplysninger om, hvad deres interne arbejde er. Vi ved, hvad det gør, hvordan det fungerer, men vi ved ikke, hvad elementerne er indeni, og hvilke ændringer der er sket fra generation til generation.
Den første ting, der skiller sig ud, er omtale af NVIDIA, at RT Cores nu kan gøre dobbelt så mange kryds pr. Trekant, hvilket ikke betyder dobbelt så mange kryds pr. Sekund. Årsagen til dette er, at når man krydser BVH-træet, hvad det gør, er at gøre krydset mellem boksene, der er de forskellige knudepunkter i træet, og kun træets sidste skæringspunkt er den, der er lavet med trekanten, den det mest komplekse at udføre. Enhederne til beregning af krydset mellem boksene er meget enklere, i Turing har vi i teorien fire enheder, der arbejder parallelt for at gå gennem de forskellige niveauer i et træ og en enkelt enhed, der udfører skæringspunktet mellem strålen og trekanten.
Den anden ændring på hardwareniveau er evnen til at interpolere trekanten i henhold til dens position i tiden, hvilket er nøglen til implementeringen af Ray Tracing med Motion Blur, en teknik, der stadig er uden fortilfælde i spil, der er kompatible med Ray Tracing. I tilfælde af at der er andre ændringer, har NVIDIA ikke offentliggjort dette, og derfor kan vi ikke drage yderligere konklusioner.