Multi-GPU'er med chiplets er lige rundt om hjørnet, og selvom vi først vil se dem i form af HPC-kort og derfor uden for spilmarkedet, har vi længe vidst, at udviklingen går i retning af konstruktion af grafikkort baseret på Multi- GPU'er pr chiplet. Men hvad bringer de i forhold til en konventionel monolitisk GPU? Læs videre for at finde ud af det.

Den arkitektur, vi diskuterer i denne artikel, er endnu ikke tilgængelig på markedet, den er ikke engang blevet præsenteret, men den er et produkt af en analyse af de fremskridt, der er produceret i de seneste år, samt af de forskellige patenter på Multi-GPU chiplets at begge AMD, NVIDIA , Intel har udgivet de sidste to år. Derfor har vi besluttet at tage disse oplysninger og syntetisere, så du har en idé om, hvordan disse typer GPU'er fungerer, og hvilke grafiske problemer de kommer til at løse.
Traditionel 3D-gengivelse med flere GPU'er

At bruge flere grafikkort til at kombinere deres kraft til at gengive hver enkelt frame i 3D-videospil er ikke nyt, da Voodoo 2 by 3dfx er det muligt at opdele renderingsarbejdet, helt eller delvist, mellem flere grafikkort. Den mest almindelige måde at gøre det på er Alternativ Frame Rendering, hvor CPU sender skærmlisten for hver frame skiftevis til hver GPU. For eksempel håndterer GPU 1 rammer 1, 3, 5, 7, mens GPU 2 håndterer rammer 2, 4, 6, 8 osv.
Der er en anden måde at gengive en scene i 3D, som er Split Frame Rendering, som består af flere GPU'er, der gengiver en enkelt scene og deler værket, men med følgende nuancer: en GPU er master -GPU'en, der læser listen over skærme og klarer resten. De første faser af rørledningen, før rasterisering, udføres udelukkende på den første GPU, som for rasterisering og de senere faser udføres ens på hver GPU.
Split Frame Rendering virker som en retfærdig måde at fordele arbejdet på, men nu vil vi se, hvilke problemer denne metode medfører, og med hvilke begrænsninger den er.
Begrænsningerne ved Split Frame Rendering og den potentielle løsning

Hver GPU indeholder 2 samlinger af DMA -drev, det første par kan samtidigt læse eller skrive data i systemet RAM via PCI Express -porten, men i mange grafikkort med Crossfire- eller SLI -understøttelse er der en anden samling DMA -drev, som giver adgang til VRAM i den anden graf. Selvfølgelig med hastigheden på PCI Express -porten, hvilket er en rigtig flaskehals.
Ideelt set ville alle GPU'er, der arbejder sammen, have den samme VRAM-hukommelse til fælles, men dette er ikke tilfældet. Så data duplikeres lige så mange gange som antallet af grafikkort involveret i gengivelsen, hvilket er groft ineffektivt. Hertil skal vi tilføje den måde, som grafikkort fungerer på, når der gengives 3D-grafik i realtid, hvilket har medført, at konfigurationen med flere grafikkort ikke længere bruges.
Tile Caching på en Multi-GPU af chiplets
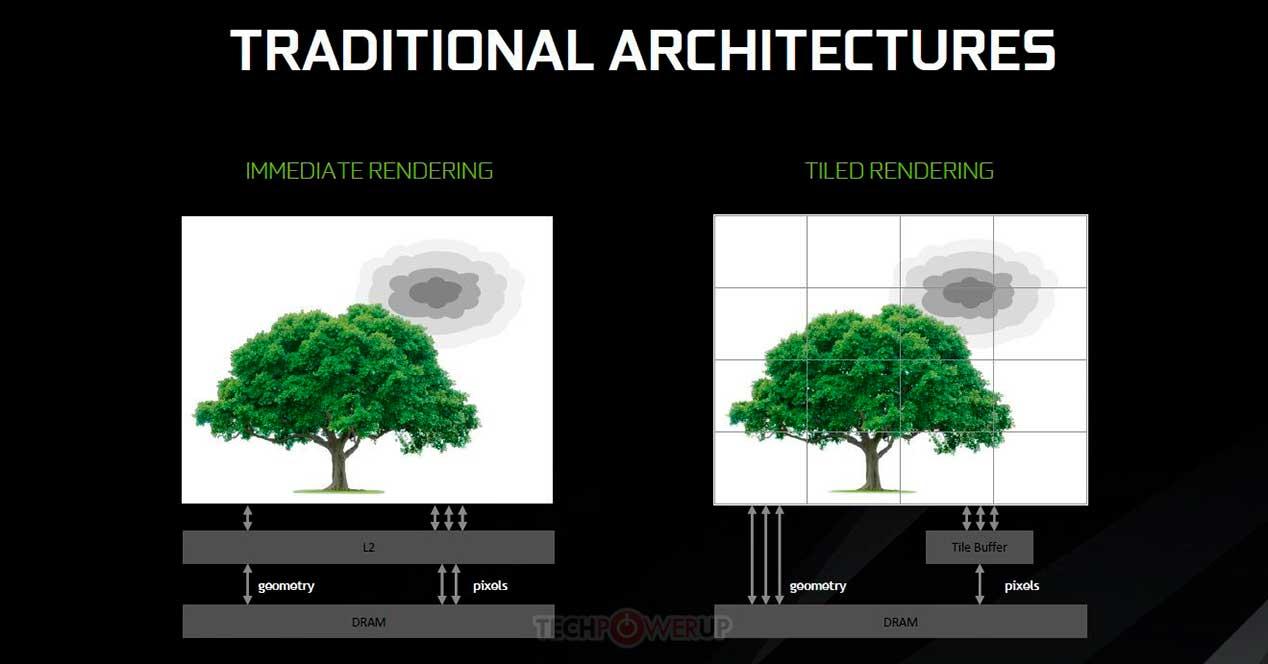
Tile Caching -konceptet begyndte at blive brugt fra NVIDIAs Maxwell -arkitektur og AMDs Vega -arkitektur, det handler om at tage nogle begreber fra gengivelse af fliser, men med den forskel, at i stedet for at gengive hver flise i en separat hukommelse og kun skrive den til VRAM, når det er færdigt er gjort på andet niveaus cache. Fordelen ved dette er, at det sparer på energiomkostningerne ved nogle grafikoperationer, men ulempen er, at det afhænger af mængden af cache på topniveau, der er på GPU'en.
Problemet er, at en cache ikke fungerer som en konventionel hukommelse, og til enhver tid og uden programstyring kan en cache-linje sendes til det næste niveau i hukommelseshierarkiet. Hvad hvis vi beslutter at anvende den samme funktionalitet på en chiplet-baseret GPU? Nå, det er her, det ekstra cacheniveau kommer ind. Under det nye paradigme ignoreres den sidste niveau-cache for hver GPU som hukommelse til Tile Caching, og den sidste cache i Multi-GPU'en bruges nu, som ville blive fundet på en separat chip.
LCC på en Multi-GPU af chiplets
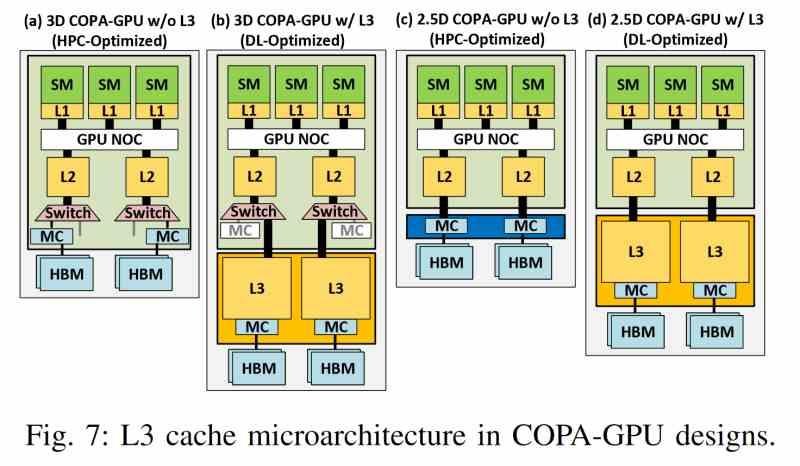
Den nyeste cache for chipletbaserede Multi-GPU'er samler en række fælles egenskaber, der er uafhængige af, hvem producenten er, så følgende liste over egenskaber gælder for enhver GPU af denne type, uanset producent.
- Den findes ikke i nogen af GPU'erne, men er ekstern i forhold til dem og er derfor på en separat chip.
- Den bruger en interposer med en meget højhastighedsgrænseflade såsom en siliciumbro eller TSV-forbindelser til at kommunikere med L2-cachen på hver GPU.
- Den krævede høje båndbredde tillader ikke konventionelle sammenkoblinger og er derfor kun mulig i en 2.5DIC -konfiguration.
- Den chiplet, hvor den sidste niveau-cache er placeret, lagrer ikke kun nævnte hukommelse, men er også der, hvor hele VRAM-adgangsmekanismen er placeret, som på denne måde er afkoblet fra renderingsmotoren.
- Dens båndbredde er meget højere end HBM -hukommelsen, hvorfor den gør brug af mere avancerede 3D -sammenkoblingsteknologier, som tillader meget højere båndbredder.
- Derudover har den, som enhver cache på sidste niveau, evnen til at give konsistens til alle de elementer, der er klienter til den.
Takket være denne cache er hver GPU forhindret i at have sin egen VRAM-brønd for at have en delt, hvilket i høj grad reducerer mangfoldigheden af data og eliminerer flaskehalse, der er et produkt af kommunikation i en konventionel multi-GPU.
Master og underordnede GPU'er
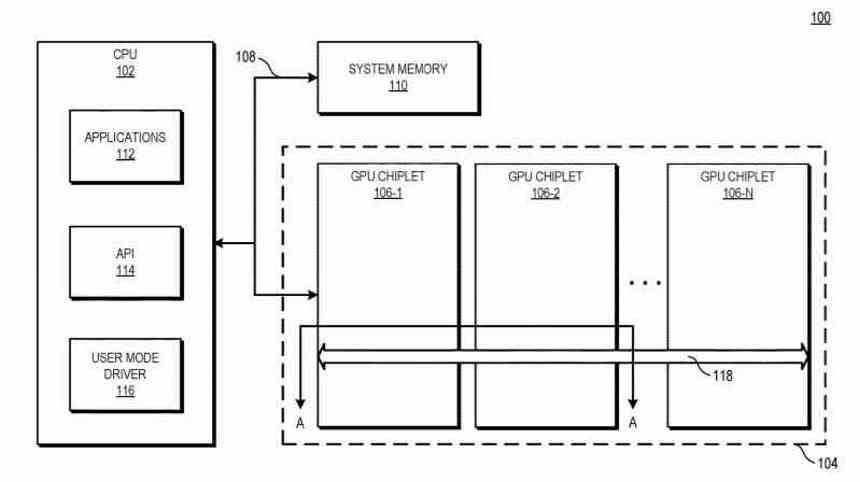
I et grafikkort baseret på en Multi-GPU af chiplets eksisterer den samme konfiguration stadig som i en konventionel Multi-GPU, når du opretter skærmlisten. Hvor der oprettes en enkelt liste, som modtager den første GPU, der er ansvarlig for administration af resten af GPU'er, men den store forskel er, at LLC -chiplet, som vi har diskuteret i det foregående afsnit, tillader den første GPU at koordinere og sende opgaver til resten af multi-GPU-behandlingsenheder pr. chip.
En alternativ løsning er, at alle chiplets i Multi-GPU'en fuldstændig vil mangle kommandoprocessoren, og dette er i samme kredsløb som hvor LCC-chipletten er placeret som orkesterleder og udnytter al den eksisterende kommunikationsinfrastruktur til at sende de forskellige instruktioner tråde til forskellige dele af GPU'en.
I det andet tilfælde ville vi ikke have en master GPU og resten som underordnede, men hele det 2.5D integrerede kredsløb ville være en enkelt GPU, men i stedet for at være monolitisk ville det være sammensat af flere chiplets.
Dens betydning for Ray Tracing

Et af de vigtigste punkter for fremtiden er Ray Tracing, som for at fungere kræver, at systemet opretter en rumlig datastruktur på objekternes information for at repræsentere transporten af lys. Det har vist sig, at hvis strukturen er tæt på processoren, er den acceleration, som Ray Tracing lider under, vigtig.
Selvfølgelig er denne struktur kompleks og optager meget hukommelse. Derfor vil det være ekstremt vigtigt at have en stor LLC -cache i fremtiden. Og det er grunden til, at LLC -cachen kommer til at være i en separat chiplet. At have den højest mulige kapacitet og gøre den datastruktur så tæt på GPU'en som muligt.
I dag skyldes meget af langsommeligheden i Ray Tracing, at meget af dataene er i VRAM'en, og der er en enorm latens i dens adgang. Husk, at LLC-cachen i en Multi-GPU ville have fordelene ikke kun med hensyn til båndbredde, men også i latenstid af en cache. Desuden vil dens store størrelse og datakomprimeringsteknikkerne, der udvikles i laboratorierne hos Intel, AMD og NVIDIA, få BVH -strukturer, der bruges til acceleration, til at blive gemt i GPU'ens "interne" hukommelse.