Den største svaghed ved RX 6000 sammenlignet med RTX 30 er dens ydeevne i forhold til Ray Tracing. Det er simpelthen at aktivere det i spil og se, hvordan forskellen stiger til fordel for NVIDIA kort. Dette har ført til AMD at foretage ændringer i RDNA 3-arkitektur til Ray Tracing . Så alt tyder på, at det vil være den mest gavnlige del af alle for den næste generation af RX 7000.
Et af de svage punkter, som RDNA-arkitekturen havde i sin begyndelse, som bestod af RX 5000-serien, var dens mangel på enheder analogt med NVIDIA RT Cores, som er ansvarlige for at udføre to almindelige opgaver i Ray Tracing. Den første af disse er beregningen af stråle-objekt skæringspunktet, som forekommer flere milliarder gange hvert sekund og bruger en stor mængde ressourcer. Den anden er gennemgangen af datastrukturen, der repræsenterer scenen. AMD besluttede at gå efter en blandet løsning. Hvor skæringspunktet beregnes gennem dets Ray Accelerator Units, men de beregner ikke datastrukturen. En løsning, der i sidste ende ikke har været den mest effektive.

Ændringer i RDNA 3-beregningsenheder til strålesporing
På sin sidste offentlige konference for investorer og aktionærer lavede AMD en hurtig forhåndsvisning af, hvad vi kan se i fremtidens RX 7000. Nogle ændringer var allerede kendt af os, såsom det faktum, at nogle modeller i serien var opdelt i flere forskellige chips , ligesom desktop Ryzen, og brugen af TSMC's 5nm node. Det er dog ikke den eneste ændring, vi vil se, og det ser ud til, at AMDs engagement i Ray Tracing i RDNA 3 bliver vigtigere end nogensinde. Nå, hvad er hybrid gengivelse for, hvilket er hvad spil bruger, kombinerer typisk 3D pipeline rasterisering med Ray Tracing til beregning af indirekte belysning helt eller delvist.


Lad os ikke glemme, at Compute Units er den sande kerne af grafikchippen, da de har alle brikkerne til at udføre de forskellige trin i cyklussen for hver instruktion, og det faktum, at AMD officielt siger, at det vil ændre sin organisation, er vigtigt . Sidste gang han gjorde det, var med springet fra RX Vega til RX 5000, og det var nok til, at han begyndte at tale om en ny arkitektur. Selvom det første vi håber på er en bedre Ray Accelerator Unit der udfører sin opgave mere effektivt, og det er mindst på niveau med dem, der findes i RTX 30. Og ja, skæringsenhederne findes inden for hver Compute Unit.
Dobbelt FLOPS pr. beregningsenhed
Den anden forbedring, der forventes, er at fordoble floating point-beregningskapaciteten, på samme måde som NVIDIA gjorde i sin RTX 30. Måden at gøre det på vil være at placere dobbelt så mange 32-bit flydende kommaenheder i forhold til den foregående generation. Det ved vi ikke officielt gennem AMD marketing, men vi ved det fra tilstrækkelig officiel information som f.eks sine egne patenter og grafikdrivere.
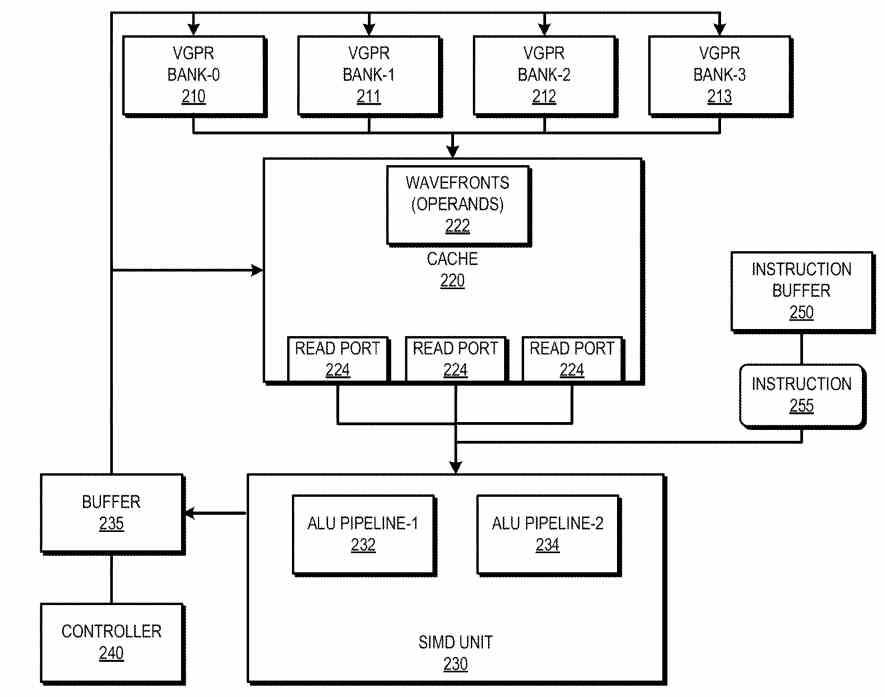
I begge tilfælde har vi været i stand til at erfare, at dobbelte instruktioner kan sendes til beregningsenhederne. Derfor omfatter hver SIMD-enhed i beregningsenheden og den de forskellige 32-bit flydende kommaenheder vil gå fra 32 elementer i RDNA 2 til 64 elementer i RDNA 3 . Nævnte instruktioner eller tråde kan udføres som 32 dobbelte instruktioner eller 32-bit tråde eller 64 simple instruktioner eller tråde.