Er det muligt, at RT Cores i fremtiden forsvinder fra fremtidige GPU'er fra NVIDIA, Intel og / eller AMD? Kan Shader-enhederne med deres enorme computerkraft vokse nok til at gøre inkluderingen helt dispensabel? af disse typer enheder?
RT-kernerne, Ray Accelerator-enhederne eller krydsningsenhederne er specialiserede enheder, der har ansvaret for en enkelt opgave i GPU'erne, og som kom for første gang fra hånden til den første NVIDIA RTX.

I denne artikel vil vi ikke forklare, hvad de er til, for dette anbefaler vi, at du kigger efter artiklen i HardZone med titlen Hvad er RT-kerner til strålesporing, og hvordan fungerer de? hvor vi på en enkel, men detaljeret måde forklarer driften af denne type enheder.
Hvad er RT-kerner eller skæringsenheder?
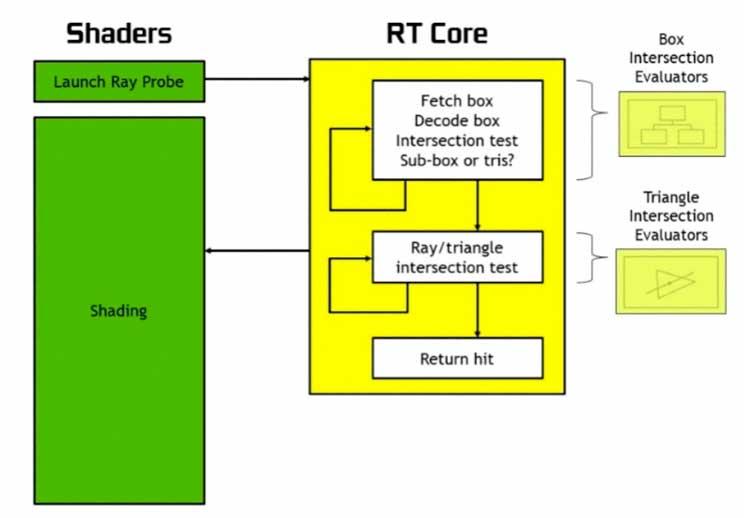
RT-kernerne i NVIDIA- eller Ray Accelerator-enheder i AMD er enheder, der har ansvaret for at beregne skæringspunktet mellem strålerne og de forskellige elementer i scenen for at forstå, hvad der er behov for denne type enhed i hardwaren til de nye grafikkort, vi er nødt til at forstå, hvordan den enkleste version af strålesporingsalgoritmen fungerer:
For hver pixel eller objekt, hvor pixlen er placeret, hvis strålen krydser objektet: farveværdien af den pixel på skærmen ændres.
Dette gøres kontinuerligt og gentagne gange i hver af de rammer, som GPU gengiver, der genereres ved hjælp af strålesporingsalgoritmen eller en af dens varianter, enten delvis for at løse de indirekte belysningsproblemer, som rasterisering ikke selv kan løse.
Möller - Trumbore-algoritmen til skæringspunktet mellem stråler og trekanter
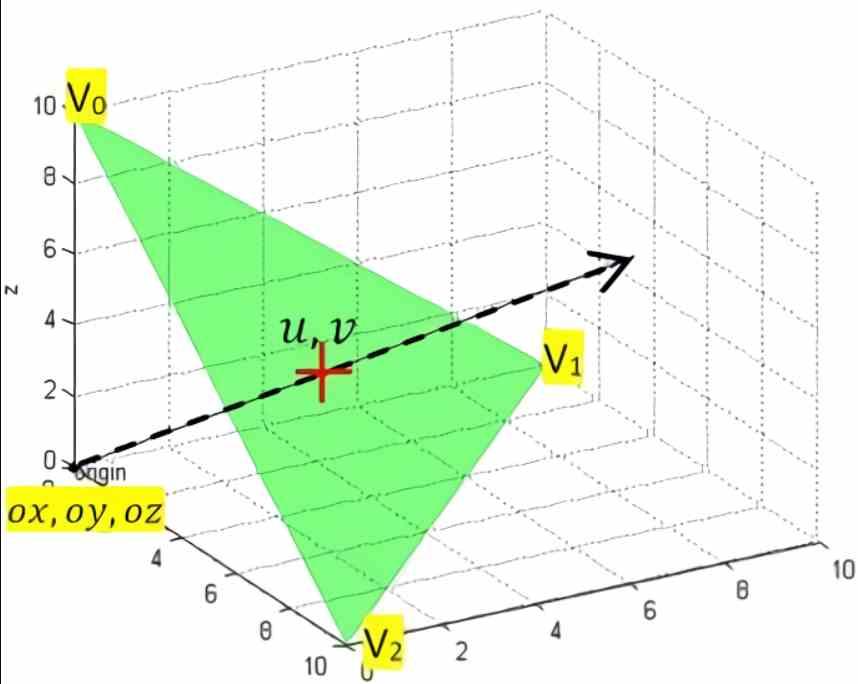
Strålingsskæringsenheder er faste funktionsenheder, der udfører Moller-Trumbore algoritme . Det skal tages i betragtning, at hvad faste funktionsenheder gør, altid er at anvende det samme program fra nogle inputdata, programmet er mikro-kablet, så de transistorer, der udgør enheden, er placeret på en sådan måde, at de kun kan køre det program og ikke et andet.
Fordelen ved faste funktionsenheder er, at de har brug for færre transistorer end programmerbare enheder, som er meget mere komplekse, men en fast funktionsenhed giver kun mening i hardware, hvor programmerbare enheder dominerer, hvis den kan udføre sin opgave på én gang. hastighed, der til pris og hastighedsniveau ikke kan matches af den programmerbare del.
Som enhver algoritme er det åbenbart muligt at udføre den i skyggenheder, men for at dette er muligt, ville det være nødvendigt for enhederne at være hurtige nok til at dispensere med faste funktionsenheder.
Omkostningerne ved Möller - Trumbore-algoritmen

På trods af at der er flere algoritmer, er dette den mest berømte og anvendte, derfor har vi besluttet at bruge det som et eksempel og tro mig, at prisen ikke er direkte billig, da der i alt er 27 flydende punktoperationer pr. Pixel . Men i nogle arkitekturer, fordi divisionen er mere kompleks at implementere i shaders, udføres den ikke af konventionelle SIMD-enheder, men af SFU'er, som kan udføre meget mere komplekse aritmetiske operationer, men med en lavere hastighed end summer. og multiplikationer.
Med andre ord ville vi have brug for 27 FLOPS ikke pr. Pixel men pr. Pixel og skæringspunkt, tænk nu på antallet af skæringspunkter og pixels i en scene, og du får en grov ide om, hvorfor krydsningsenhederne eller RT-kernerne er så nødvendige.
Den type skyggeprogram, der erstatter RT Cores
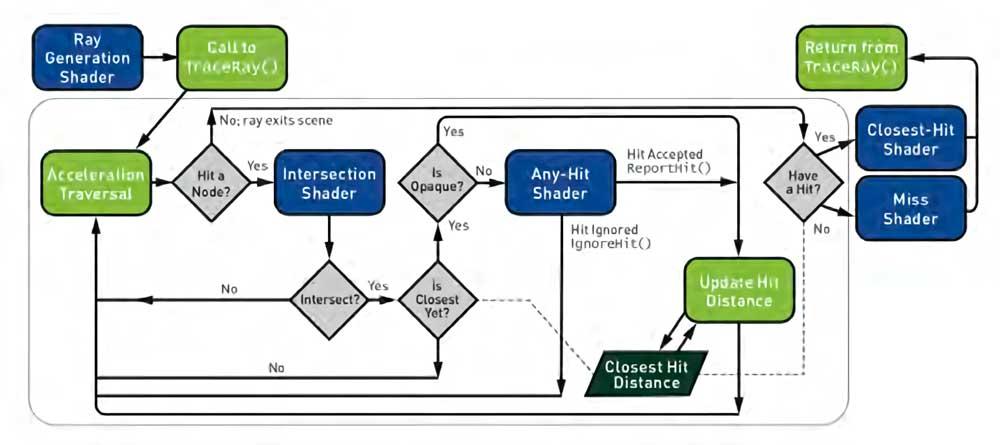
I API-specifikationerne til realtidsstrålesporing, både i DXR inden for DX12 Ultimate og i Ray Tracing-udvidelser til Vulkan, er der en type skygge, der er blevet forældet, som er skæringsskærmen, som den helt erstatter til krydsningsenheder i hardware, hvor de ikke er til stede.
Husk, at en skygge kun er et program, og det faktum, at programmører skal lave deres egen krydsningsenhed spil for spil, kan være et kedeligt, det er derfor, begge API'er inkluderer eksempler på krydsningsskygger. Afvejningen for dette? Mange udviklere kan se krydsningsalgoritmen inkluderet i API'er samt faste funktionsenheder som upassende.
I hardwaredesign er det ikke almindeligt at eliminere faste funktionsenheder, der fungerer som acceleratorer, men snarere er det sædvanligt at udvide kapaciteten af disse enheder og endda gøre disse enheder programmerbare, så det næste trin i udviklingen af krydsningsenheder, hvis det ikke allerede er gjort, er det til et specifikt domæneformål med mikroprogrammeret kode, der kan opdateres.
Derfor er det muligt, at vi ser oprettelsen af nye krydsningsalgoritmer med bedre ydeevne, som ender med at blive skrevet i den interne hukommelse på hver af enhederne med en firmwareopdatering.
Faste funktionsenheder er aldrig blevet fjernet fra en GPU

En GPU har en række faste funktionsenheder til gengivelse af 3D-grafik, disse enheder er ligesom skæringsenhederne ansvarlige for at udføre gentagne og gentagne opgaver i hver ramme. Vi henviser til enheder såsom teksturenheder, dem der har ansvaret for rasterisering af geometri osv.
Disse enheder er aldrig blevet elimineret på grund af det faktum, at deres opgaver kan udføres af en skyggeenhed. Hvad mere er, hvis vi tog en GPU uden de nævnte faste enheder og fik dem til at gengive en scene i 3D, ville de være i størrelsesorden mere ineffektiv end en GPU med færre skyggeenheder, men med disse enheder inkluderet.
Tendensen er altid, at der vises en del, der er gentagne og gentagne i hver ramme, hvilket ville optage en god del af tiden og ressourcerne for de enheder, der udfører skyggelægningerne, da det ender med at skabe en type specialenhed, der ikke kun udlades fra den nævnte opgave til disse enheder, men at gøre det hurtigere og til en del af prisen.