Når vi har en server med Linux eller en NAS-server (som også har et Linux-baseret styresystem) med en masse information inde, både selve styresystemet og personlige eller arbejdsfiler og -mapper, er det vigtigt at kontrollere, at harddiskene og SSD drev er ved godt helbred og vil ikke gå i stykker lige nu uden varsel. Af denne grund er det meget vigtigt løbende at overvåge harddisken eller SSD'en på vores server for at undgå tab af data på grund af, at den går i stykker. I dag i denne artikel vil vi vise dig alt, hvad du bør tjekke på din Linux-server for at kontrollere dine diskes tilstand.

Hvad er diskenes SMART
Alle harddiske og SSD-drev har en teknologi kaldet SMART, eller også kendt som SMART som står for "Self Monitoring Analysis and Reporting Technology". Denne teknologi indbygget i firmwaren på harddiske og SSD'er består i at detektere mulige fejl på harddisken, med det formål at forudse fysiske fejl på harddisken eller uventede fejl i SSD-drev som følge af skrivning til intern flashhukommelse. . Målet med SMART er at advare brugerne, så de kan sikkerhedskopiere og udskifte drevet uden at miste data. Hvis vi ignorerer SMART, vil der komme et tidspunkt, hvor harddisken går i stykker, og vi vil miste data, så det er vigtigt altid at være opmærksom på diskenes SMART-data.
For at bruge SMART er det absolut nødvendigt at serverens BIOS eller UEFI er kompatibel med denne teknologi og at den er aktiveret, derudover er det også absolut nødvendigt at diskene inkorporerer det. I dag bruger alle servere, operativsystemer og diske denne teknologi til at opdage problemer på harddisken, man kan sige, at den er "universel", og at den altid bruges.
Denne teknologi er ansvarlig for at overvåge forskellige parametre på harddisken, såsom hastigheden af diskpladerne, dårlige sektorer, kalibreringsfejl, cyklisk redundanskontrol (de typiske CRC-fejl), disktemperatur, datalæsehastighed, starttidspunkt (spin- op), omallokerede sektortæller, søgehastighed (søgetid) og andre meget avancerede parametre, der giver dig mulighed for at vide, hvad der er vigtigt: hvis harddisken snart vil svigte.
Internt har SMART en række værdier, som vi kan betragte som "normale", og når en parameter går ud af disse værdier, det vil sige når alarmen går, vil BIOS/UEFI detektere det og meddele operativsystemet, at der er en fejl i systemet. disk, og det kan være alvorligt. I Linux-operativsystemer har vi mulighed for at udføre SMART-tests for at tjekke om disken fungerer korrekt, derudover har vi mulighed for at programmere disse tests for at minimere indvirkningen på ydeevnen.
Sådan får du vist disksundhed
I de fleste Linux-baserede distributioner har vi en pakke kaldet smartmontools. Nogle gange er denne pakke forudinstalleret i vores distribution, og andre gange skal vi selv installere den. Denne pakke har to forskellige programmer:
- smartctl : er kommandolinjeprogrammet, der giver os mulighed for at verificere harddiske og SSD'er efter behov, eller vi kan programmere dets drift gennem den typiske cron i operativsystemet.
- smartd : er en dæmon eller proces, der verificerer, at harddiske eller SSD'er i et specificeret interval ikke har haft nogen fejl. Den er i stand til at registrere enhver form for advarsel eller diskfejl til serverens hovedsyslog, den tillader også at sende de samme advarsler og fejl via e-mail til administratoren, så han kan bekræfte, at alt er korrekt.
Smartmontools-pakken er ansvarlig for overvågning af harddiske og SSD-drev, uanset om de bruger SATA, SCSI, SAS eller NVME-grænseflader, den understøtter enhver type datagrænseflade. Selvfølgelig er dette program helt gratis.
Installation
Installation af dette program, hvis det ikke er installeret som standard på din Linux-distribution, sker ved at bruge din distributions pakkehåndtering. For eksempel på Debian-operativsystemer med apt ville det være som følger:
sudo apt install smartmontools
Afhængigt af pakkehåndteringen af din distribution, skal du bruge en eller anden kommando, det vigtige er, at denne pakke er tilgængelig for alle Unix-baserede distributioner og også Linux, så du kan også installere den på FreeBSD uden problemer.
Bruger smartctl
For at bruge dette program og kontrollere vores harddisks tilstand, er det første, vi skal gøre, at vide, hvor mange harddiske vi har, og hvad er vejen til at undersøge de pågældende harddiske eller SSD'er. For at vide, hvor diskene er, skal vi udføre følgende kommando:
df -h
Vi kunne også bruge fdisk til at få listen over diske, som vi har på vores server:
sudo fdisk -l
Disse kommandoer viser os en liste over enhederne og også over partitionerne. Vi skal bruge dette program på harddisk- eller SSD-niveau, ikke på partitionsniveau. Generelt i Linux-systemer vil vi finde diskene i /dev/sdX-stien.
Når vi ved, hvilket drev vi skal analysere for at kontrollere dets helbred gennem SMART, skal vi vide, at der i alt er to forskellige tests, som vi kan udføre:
- Kort test – Denne test bruges oftest til at opdage diskproblemer. Når du udfører denne test, vil den vise os de vigtigste fejl og advarsler, uden at det er nødvendigt at analysere hele disken i detaljer. Vi kan planlægge denne korte test gennem cron til at være ugentlig, på denne måde vil den en gang om ugen udføre denne analyse og give os besked, hvis den har opdaget nogen fejl. Det er tilrådeligt at udføre denne test på et tidspunkt, hvor der er ringe eller ingen brug, det anbefales ikke at gøre det i arbejdstiden, bedre ved daggry.
- Lang test – Denne test kan tage ret lang tid, afhængigt af drevet og dets kapacitet. Ved at udføre denne omfattende test vil den vise os alle de advarsler eller fejl, den finder på hele disken. Vi kan planlægge, at denne lange test med cron skal udføres månedligt, det vil sige, at vi en gang hver måned udfører denne test for at kontrollere diskens tilstand. Det er tilrådeligt at udføre denne test på et tidspunkt, hvor der er ringe brug af disken, f.eks. ved daggry, da læse- og skriveydelsen ellers vil stige betydeligt.
Når vi kender de to typer test, vi kan bruge, er den første ting, vi skal vide, om harddisken eller SSD'en har SMART aktiveret:
sudo smartctl -i /dev/sda
I tilfælde af at disken understøtter SMART, men ikke er aktiveret, kan vi aktivere den ved at udføre følgende kommando:
sudo smartctl -s on /dev/sda
For at se alle SMART-attributterne for producenten af den pågældende disk, kan vi udføre følgende kommando:
sudo smartctl -a /dev/sda
For at udføre en kort test udfører vi følgende:
sudo smartctl -t short /dev/sda
For at udføre en lang test udfører vi følgende:
sudo smartctl -t long /dev/sda
Når vi har udført den korte eller lange test, kan vi udføre følgende kommando for at se alle resultaterne:
sudo smartctl -H /dev/sda

Vi anbefaler at læse man-siderne i smartctl, hvor du vil finde alle de kommandoer, som vi vil være i stand til at udføre for at bruge mulighederne i SMART, men hovedkommandoerne er dem, vi har forklaret dig.
Hvilke værdier skal jeg se på?
Når vi laver en SMART-test, vil et stort antal attributter for vores harddisk eller SSD dukke op. Nogle af disse værdier er kritiske, som vi er meget opmærksomme på, fordi de kan give os "antydninger" om, at disken snart vil fejle:
- Reallocated_Sector_Ct: er antallet af sektorer, der er blevet omallokeret til andre områder på disken, fordi der har været læsefejl. Denne fejl er meget typisk, når en disk er meget gammel og nær slutningen af dens levetid.
- Spin_Retry_Count: er antallet af forsøg, der har været nødvendige for at starte disken, dette indikerer, at der er et alvorligt hardwareproblem på disken, og at den muligvis ikke starter næste gang.
- Reallocated_Event_Count – Antallet af omallokeringer, der er blevet udført, enten med succes eller uden succes. Jo højere tal, jo dårligere er harddiskens helbred.
- Current_Pending_Sector: antallet af sektorer, der afventer at omfordele snart.
- Offline_Uncorrectable: antal ukorrigerbare fejl ved adgang, enten læsning eller skrivning, til forskellige sektorer af disken.
- Multi_Zone_Error_Rate: det samlede antal fejl under skrivning af en sektor.
På det følgende billede kan du se status for en WD Red 4TB-harddisk fra vores NAS med XigmaNAS-operativsystemet:

I det forrige skærmbillede kan du se en masse information, men vi skal vide, om det er en isoleret fejl, ellers kan vores disk snart svigte.
Status for diske i QNAP NAS
Hvis du har en QNAP-, Synology- eller ASUSTOR NAS-server, vil du også kunne se SMART-statussen for dine harddiske og SSD'er gennem operativsystemet med webadgang, der er ingen grund til at gå ind via SSH eller Telnet og udføre eventuelle kommandoer . I eksemplet nedenfor har vi brugt en QNAP NAS-server, men processen med de andre producenter ville være meget ens.
Det første vi skal gøre er at gå til " Opbevaring og snapshots ”-sektion, når du er her, skal du klikke på “ Opbevaring / Diske ” og vi vil se noget som dette:

Hvis vi klikker på " Diskens tilstand ”, bliver vi nødt til at vælge hvilken disk af alle vi vil se på. Vi kan vælge både HDD-harddiske såvel som SSD-drev, uanset hvilken type de er, fordi de også har intern SMART-information for at se, om der er en diskfejl.

I menuen "Opsummering" kan vi se diskens generelle status, hvis der er nogen form for fejl eller alvorlig advarsel, kan vi også nemt og hurtigt se det generelle helbred uden behov for at udføre en detaljeret analyse af SMART'en værdier. Vi kan selvfølgelig også se diskadgangshistorikken, og om der har været problemer.

Selvom QNAP giver os meget letforståelig information, vil vi også være i stand til at gøre det uden problemer, hvis vi ønsker at se alle råværdierne. Derudover vil vi have en ekstra kolonne, der fortæller os "Status", og om den er god eller dårlig.
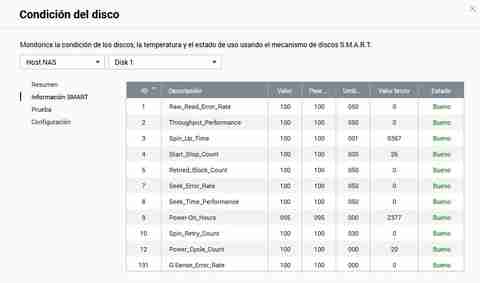
Vi vil være i stand til at lave hurtige eller komplette test her, vi skal blot vælge testmetoden og derefter klikke på "Test" knappen.

Endelig kan vi også programmere disse tests på en meget nem måde, vi skal blot vælge at aktivere hurtig eller komplet test, og vælge frekvensen: dagligt, ugentligt eller månedligt, derudover kan vi definere starttidspunktet for denne test.

Som du kan se, er kontrol og verificering af sundhedsstatus for harddiske og SSD'er på en server noget virkelig vigtigt for at undgå tab af data. Når der opstår nogen form for fejl, er det meget vigtigt at købe et nyt drev og lave en sikkerhedskopi for at undgå tab af data. Derudover bør vi også kontrollere status for RAID, fordi vi kan forårsage tab af hele lagerpuljen, især hvis vi har konfigureret en ZFS RAID 0 eller Stripe.