
Před několika týdny byl přidělen patent AMD byl vysvětlen, jak budou fungovat jejich GPU rozdělené do několika čipů, což bude obecné pravidlo nejen pro ně, ale i pro konkurenci. Kde to víme NVIDIA Násypka a Intel Xe-HP jsou rozděleny do několika čipů. Řešení AMD se ale poněkud liší od řešení navrženého konkurencí, vysvětlujeme patent na chiplety AMD.
Důvod, proč duální GPU zmizely z domácího prostředí a je odpovědí na otázku, proč již nevidíme grafické karty kompatibilní s NVIDIA SLI nebo AMD Crossfire, je stejný, aplikace, které používáme na našich počítačích, jsou naprogramovány tak, aby používaly jeden GPU.

V počítačových videohrách při použití duálního GPU. Používají se techniky, jako je Alternativní vykreslování snímků, kdy každý grafický procesor vykresluje alternativní snímek vzhledem k druhému, nebo Rozdělené vykreslování snímků, kde dvojice grafických procesorů rozděluje práci jednoho snímku.
Ve výpočtech přes GPU k tomuto problému nedochází, a proto v systémech, kde se grafické karty nepoužívají k vykreslování grafiky, zjistíme, že několik z nich funguje bez problémů. A co víc, aplikace, které využívají GPU jako paralelní procesory dat, jsou již navrženy tak, aby využívaly výhody GPU tímto způsobem.
Nárůst velikosti GPU v posledních letech

Podíváme-li se na vývoj GPU v posledních letech, uvidíme, že došlo k výraznému růstu v oblasti špičkových GPU z jedné generace na druhou.
Nejhorší ze současného scénáře? Zatím neexistuje žádný GPU, který by měl ideální výkon pro hraní 4K. Je třeba vzít v úvahu, že nativní 4K obraz má 4krát více pixelů než jeden při 1080p, a proto mluvíme o datovém pohybu, který je čtyřikrát větší než u Full HD.
V současné situaci ve VRAM máme případ GDDR6, uvedená paměť používá 32bitové rozhraní na čip, rozdělené do dvou 16bitových kanálů, ale s taktovými rychlostmi, které způsobí prudký nárůst spotřeby energie, což vede hledáme další řešení pro rozšíření šířky pásma.
Rozšíření šířky pásma VRAM

Pokud chceme šířku pásma rozšířit, existují dvě možnosti:
- Prvním je zvýšení rychlosti paměti, ale je třeba vzít v úvahu, že při zvyšování MHz se napětí zvyšuje na druhou a tím i spotřeba energie.
- Druhým je zvýšení počtu pinů, což by mělo jít z 32 bitů na 64 bitů.
Nemůžeme zapomenout ani na věci, jako je PAM-4 používaný v GDDR6X, ale to byl krok společnosti Micron, aby se zabránilo dosažení vysokých rychlostí hodin. Pro případnou GDDR64 by se tedy měla očekávat 7bitová sběrnice na čip VRAM.
Nevíme, co budou tvůrci VRAM dělat, ale zvyšování rychlosti hodin není možnost, o které si myslíme, že ji nakonec přijmou v rámci omezeného energetického rozpočtu.

Nevíme, co budou tvůrci VRAM dělat, ale zvýšení rychlosti hodin není možnost, o které si myslíme, že si ji nakonec osvojí.
Rozhraní mezi GPU a VRAM jsou však umístěna na vnější straně obvodu samotného GPU. Takže zvýšení počtu jeho bitů znamená rozšíření periferie uvedeného GPU, a proto jeho zvětšení.
Co je vážné z přidaných problémů kvůli vysoké velikosti z hlediska nákladů, to donutí výrobce grafických karet používat několik čipů místo jednoho, a to je v tomto okamžiku, kdy zadáme takzvané chiplety.
Typy GPU založené na chipletech

Existují dva způsoby, jak rozdělit GPU na chiplety:
- Rozdělení jednoho GPU o velké velikosti na více chipletů je kompromisem v tom, že komunikace mezi různými stranami vyžaduje obrovskou šířku pásma, která by bez použití speciálních interkomů nebyla možná.
- Použijte několik GPUS ve stejném prostoru, které fungují společně jako jeden.
V článku HardZone s názvem „Takto budou GPU založené na Chiplets, které uvidíme v budoucnu“ si můžete přečíst o konfiguraci prvního typu, zatímco patent AMD týkající se jeho GPU s chiplety odkazuje na druhý typ.
Zkoumání patentu na chiplety AMD:
Prvním bodem, který se objevuje v každém patentu, je užitečnost vynálezu, který vždy vychází z jeho pozadí, což se nás týká:
Konvenční monolitické designy, jejichž výroba je stále dražší. Chiplety byly úspěšně použity v procesor architektury ke snížení výrobních nákladů a zlepšení výnosů. Vzhledem k tomu, že jeho heterogenní výpočetní povaha se přirozeně přizpůsobuje samostatným jádrům CPU v různých jednotkách, které nevyžadují velkou vzájemnou komunikaci.
Zmínka o CPU je jasná, že odkazuje na AMD Ryzen a je to, že velká část designérského týmu architektur Zen byla přemístěna do Radeon Technology Group, aby pracovala na vylepšení architektury RDNA. Koncept chiplet není první zděděný po zenu, druhý je Nekonečná mezipaměť, který zdědil koncept „oběti mezipaměti“ od zenu.
Zadruhé, problém interkomu, na který odkazujete, odkazuje na obrovskou šířku pásma, kterou GPU potřebují ke vzájemné komunikaci svých prvků. Což je překážkou tváří v tvář jejich konstrukci v chipletech kvůli energii spotřebované při přenosu dat.
Práce GPU je ze své podstaty paralelní. Geometrie zpracovávaná GPU však zahrnuje nejen části práce paralelně, ale také díla, která vyžadují synchronizaci v určitém pořadí mezi různými částmi.
Důsledek toho? Programovací model pro GPU, který distribuuje práci napříč různými vlákny, je často neefektivní, protože paralelismus je obtížné distribuovat napříč různými pracovními skupinami a chiplety, protože je obtížné a nákladné synchronizovat obsah paměti zdrojů sdílených v systému.

Část, kterou jsme uvedli tučně, je vysvětlení z pohledu vývoje softwaru, pro který jsme neviděli GPU založené na chipletech. Nejedná se pouze o problém s hardwarem, ale také o problém se softwarem, je proto nutné jej zjednodušit.
Z logického hlediska jsou také aplikace psány s názorem, že systém má pouze jeden GPU. To znamená, že ačkoli konvenční GPU obsahuje mnoho jader GPU, aplikace jsou naprogramovány tak, aby cílily na jedno zařízení. Proto bylo historicky výzvou přinést metodiku návrhu chipletů do architektur GPU.
Tato část je klíčem k pochopení patentu, AMD nemluví o rozdělení jednoho GPU na chiplety, což dělá ve svých CPU, ale spíše mluví o použití několika GPU, ve kterých je každý chiplet, je důležité zachovat pamatujte na tento rozdíl, protože řešení AMD se zdá být více zaměřeno na vytvoření Crossfire, ve kterém není nutné, aby programátoři přizpůsobovali své programy pro různé GPU.
Jakmile je problém definován, dalším bodem je mluvit o řešení nabízeném patentem.
Zkoumání patentu AMD Chiplet: Řešení
Řešení vystaveného problému navrženého společností AMD je následující:
Aby se zlepšil výkon systému pomocí chiplet GPU při zachování současného programovacího modelu, patent ilustruje systémy a metody, které používají pasivní křížová propojení s velkou šířkou pásma pro vzájemné propojení chipletů GPU.
Důležitou součástí patentu jsou křížové odkazy, o kterých si povíme dále v tomto článku, jedná se o komunikační rozhraní mezi různými chiplety, tj. Jak se mezi nimi přenášejí informace.
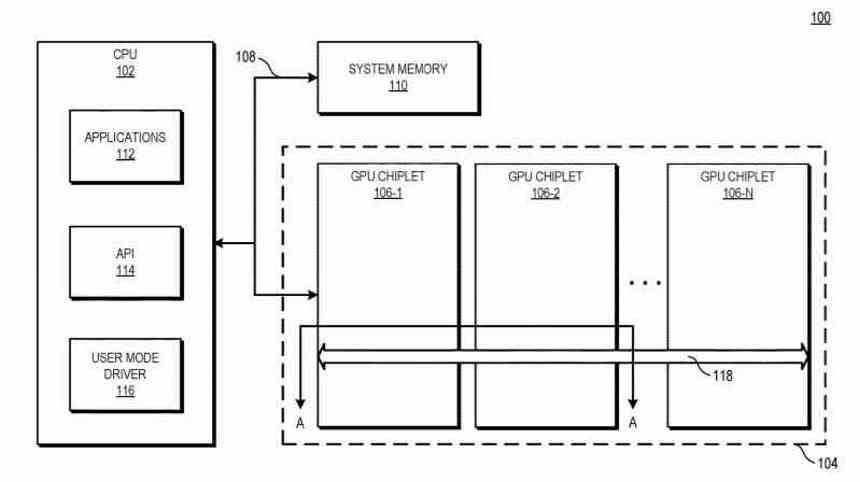
V různých implementacích systém zahrnuje centrální procesorovou jednotku (CPU), která je připojena k prvnímu chipletu GPU v řetězci, který je připojen k druhému chipletu prostřednictvím pasivního síťování. V některých implementacích je pasivní síťování pasivním interposerem, který zpracovává komunikaci mezi chiplety .
V zásadě jde o to, že nyní máme duální GPU fungující jako jeden, který je složen ze dvou vzájemně propojených čipů přes interposer, který by byl umístěn níže.
Pasivní křížová propojení s velkou šířkou pásma
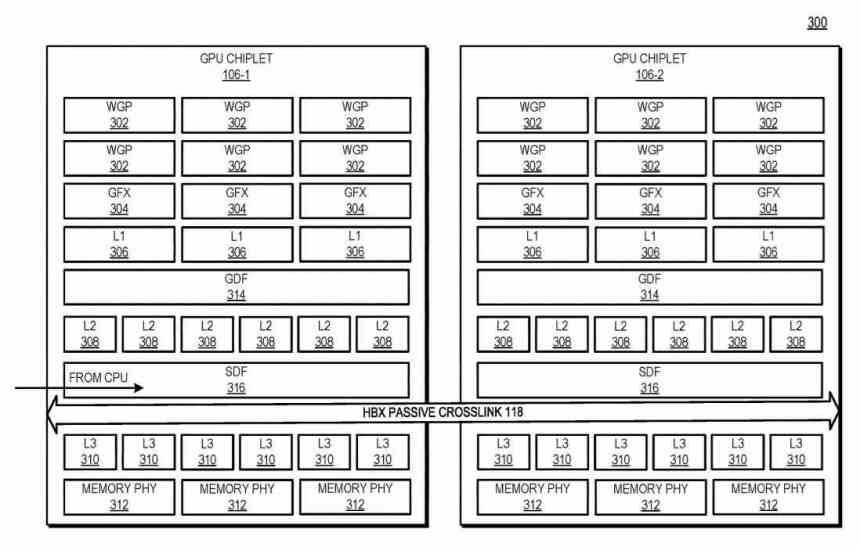
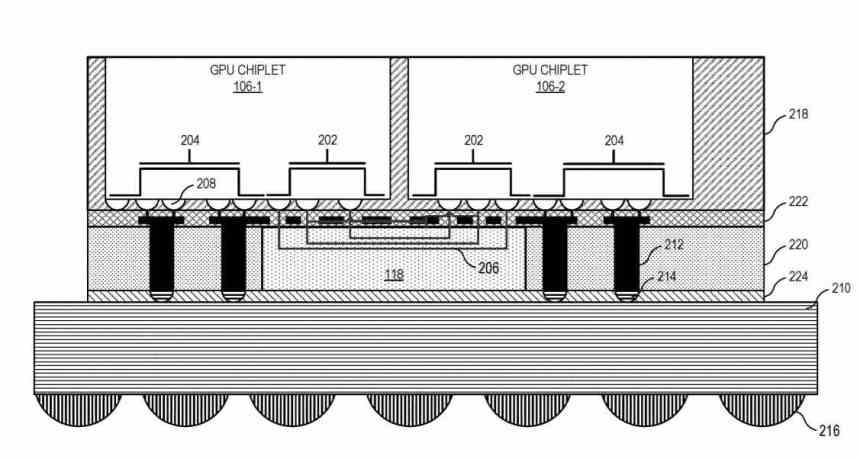
Jak chiplety komunikují s interposerem? Pomocí typu rozhraní, které vzájemně komunikuje Scalable Data Fabric (SDF) každého z chipletů, je SDF v GPU AMD ta část, která normálně sedí mezi mezipamětí nejvyšší úrovně GPU a rozhraním. paměť, ale v tomto případě existuje mezipaměť L3 mezi SDF každého chipletu GPU a SDF a předtím rozhraní, které vzájemně komunikuje tyto dva chiplety.
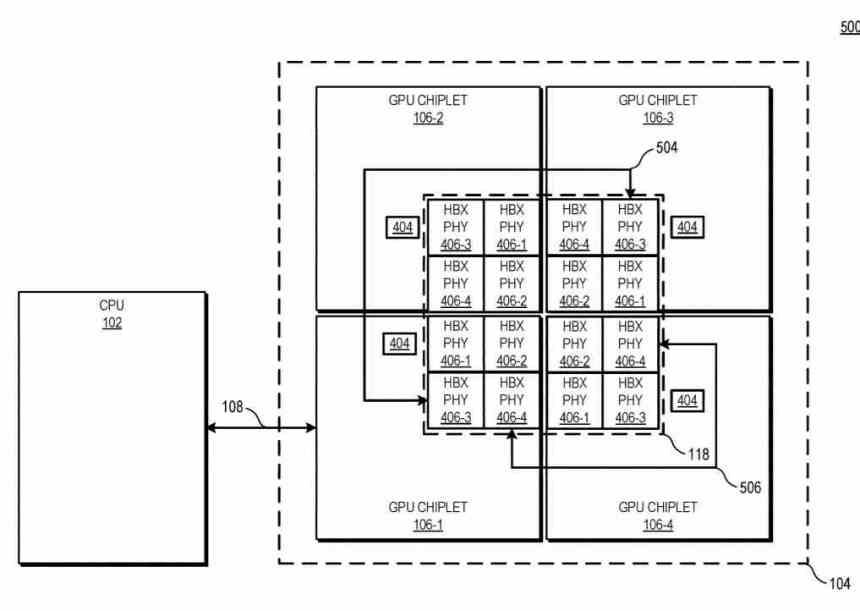
V tomto diagramu vidíte příklad se 4 chiplety GPU, počet rozhraní HBX je vždy 2 2 ve kterém n je počet chipletů v interposeru. Podíváme-li se na úroveň hierarchie mezipaměti, L0 (není popsáno v patentu) je lokální pro každou výpočetní jednotku, L1 pro každé Shader Array, L2 pro každý GPU chiplet, zatímco L3 cache by byla novinka, toto Je popsáno jako mezipaměť poslední úrovně nebo LCC celé sady GPU.
V současné době mají různé architektury alespoň jednu úroveň mezipaměti, která je konzistentní napříč celým GPU. Tady v architektuře GPU založené na chipletech umístí tyto fyzické zdroje na samostatné čipy a komunikuje je takovým způsobem, aby uvedená mezipaměť nejvyšší úrovně zůstala konzistentní napříč všemi chiplety GPU. I přes provoz v masivně paralelizovaném prostředí tedy musí být mezipaměť L3 konzistentní.
Během operace se požadavek na adresu paměti z CPU do GPU přenáší na jeden chiplet GPU, který komunikuje s pasivním křížením s velkou šířkou a vyhledá data. Z hlediska CPU to vypadá, že míříte k monolitickému jednočipovému GPU. To umožňuje použití velkokapacitního GPU, složeného z několika chipletů, jako by to byl jeden GPU pro aplikaci.
To je důvod, proč řešením AMD není rozdělení GPU na několik různých chipletů, ale použití několika GPU, jako by to bylo jedno, čímž se vyřeší jeden z problémů, které s sebou přinesla AMD Crossfire, a umožňuje jakýkoli software, který můžete použít více GPU současně, jako by byly jedno a bez nutnosti přizpůsobovat kód.
Druhým klíčem k pasivním křížovým vazbám je skutečnost, že na rozdíl od toho, co mnozí z nás spekulovali, nekomunikují s GPU pomocí kanálů přes křemík nebo TSV, ale že AMD vytvořilo proprietární interkomunikaci pro konstrukci SoC. , CPU a GPU, v 2.5DIC a 3DIC, což nás vede k otázce, zda je rozhraní X3D, které musí nahradit jeho Infinity Fabric.
AMD chiplety jsou pro RDNA 3 dále

Skutečnost, že problém při použití několika GPU není problémem aplikací určených pro výpočet pomocí GPU, jasně ukazuje, že řešení navržené společností AMD ve svém patentu je zaměřeno na domácí trh, konkrétně GPU architektur RDNA, existuje několik vodítek o tom:
- V diagramech chipletů patentu se objevuje termín WGP, který je typický pro architekturu RDNA a nikoli pro CDNA a / nebo GCN.
- Zmínka v části patentu o používání paměti GDDR, která je typická pro domácí GPU.
Patent nám nepopisuje konkrétní GPU, ale můžeme předpokládat, že AMD vydá první duální GPU na základě chipletů při spuštění RDNA 3. To umožní AMD vytvořit jeden GPU namísto různých variant architektury ve formě různých čipů, jak tomu bylo dnes.

Řešení AMD také kontrastuje s tím, o čem se říká NVIDIA a Intel. Od prvního víme, že Hopper bude jeho první architekturou založenou na chipletech, ale neznáme jeho cílový trh, takže může být dobře zaměřen na vysoce výkonný výpočetní trh, jako je hraní her.
Pokud jde o Intel, víme, že Intel Xe-HP je GPU složený také z chipletů, ale bez nutnosti řešení, jako je AMD, protože cílem společnosti Intel pro uvedený GPU není domácí trh.